webmagic
 webmagic copied to clipboard
webmagic copied to clipboard
A scalable web crawler framework for Java.
re interrupting waitNewUrl and sleep after the interruptException is catched.
有个需求,需要动态调整爬虫的线程池数量,因为爬虫在运行中,我只能下如下的代码去修改: //当前运行的线程数是10,希望通过以下代码调整为5 if (spider.getStatus() == Status.Running) { spider.stop(); spider.thread(5); spider.start(); } 但偶尔会得到以下错误,请帮忙看看@code4craft Exception in thread "Thread-13" java.util.concurrent.RejectedExecutionException: Task us.codecraft.webmagic.thread.CountableThreadPool$1@3ea050c0 rejected from java.util.concurrent.ThreadPoolExecutor@4d86ad21[Shutting down, pool size = 8, active threads =...

在添加新任务时,源码中时这样实现的 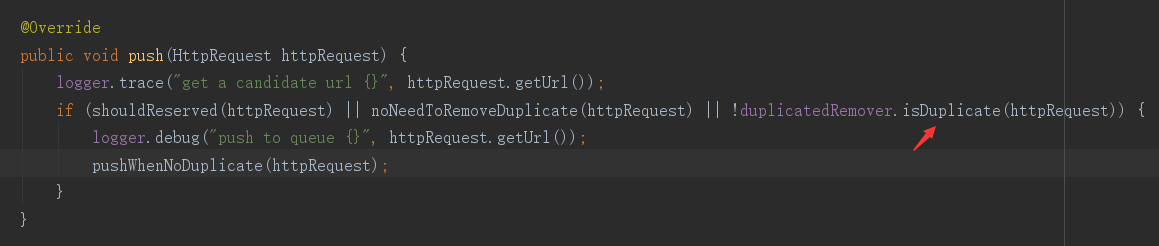 上面的判断条件 isDuplicate 是用来判断url是否在去重队列中,如果没被去重,才可以加入未抓取任务队列,该方法源码中实现: 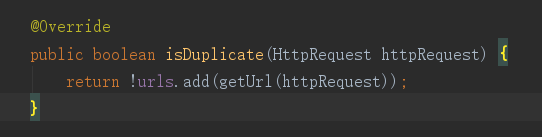 上面的实现是通过往set中添加url的方式,根据返回值来判断之前该url是否存在set中。这就表示,在判断的同时,就把要抓取的url添加到了去重集合中。 **我的问题:** 如果该url由于网站本身的问题,导致我这次未抓取成功。过几天我再抓取时,就会被去重功能过滤掉,导致即使抓取出错也不能再次进行抓取。 这里为什么不设计成当页面抓取完成以后再把url加入去重集合中。或者其他更合理的方式解决我的问题。 Webmagic我是初次接触,也可能存在理解偏差,望作者或者了解的大神们能帮忙解答,万分感谢。
BloomFilterDuplicateRemover是内存操作的吗?如果爬虫重启,要怎么初始化重建?因为已入库的可能有很多很多
@Override public synchronized Request poll(Task task) { Jedis jedis = pool.getResource(); try { String url = jedis.lpop(getQueueKey(task)); if (url == null) { return null; } String key = ITEM_PREFIX +...
Would be interested to know why maven dependencies haven't been cached on Travis. Thank you.
比如抓取url_a重定向到了url_b,在最终的页面如果有的超链接写的是相对路径,比如c?k=v,那么在做超链接填充的时候取得是request中的url_a拼上相对路径为url_a/c?k=v,但这个link是错误的,正确的应该是url_b/c?k=v。目前这个问题导致的问题是link无限叠加扩充,比如限定站点全站抓取根本就抓不完。
下个迭代能不能把SubPageProcessor的match参数从request改成page,有些时候要用到。 例如match返回false时,同时要把page.setSkip设置为false,让它不要触发Pipeline ```java @Override public void process(Page page) { for (SubPageProcessor subPageProcessor : subPageProcessors) { if (subPageProcessor.match(page.getRequest())) { SubPageProcessor.MatchOther matchOtherProcessorProcessor = subPageProcessor.processPage(page); if (matchOtherProcessorProcessor == null || matchOtherProcessorProcessor != SubPageProcessor.MatchOther.YES)...
Metadata
Owner
Metadata
A scalable web crawler framework for Java.