webmagic
 webmagic copied to clipboard
webmagic copied to clipboard
A scalable web crawler framework for Java.
请问,这是 org.slf4j exclude 导致的? 要怎么处理?
cookie问题

这是我设置cookie的地方,应该没问题的。 开始请求接口 浏览器自动打开然后请求我放入的url,如图所示: 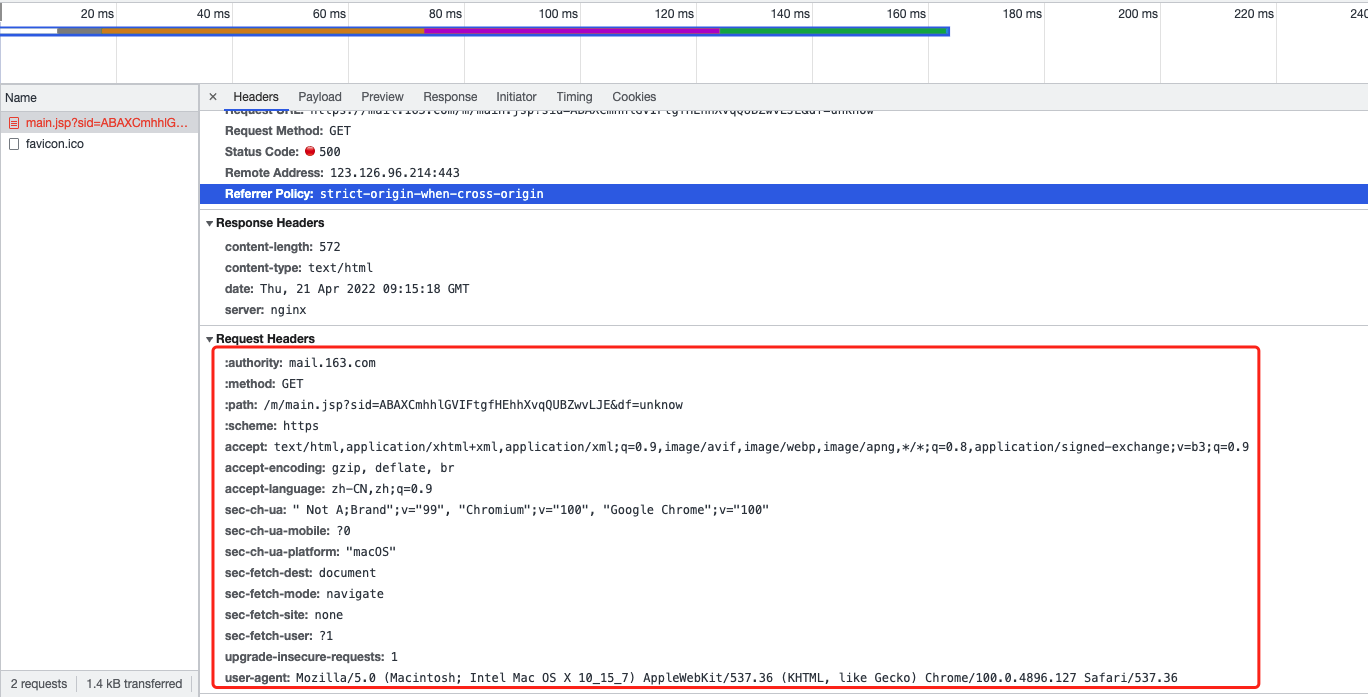 根本进不去,如图所示:  然后我手动刷新一下:  这是什么情况啊???很着急 !在线等!!!
新版`ProxyProvider`只有一个默认实现`SimpleProxyProvider `,主要是作者考虑到实现一个复杂版本,第一不一定能完全理解需求,另外实现也没有经过检验,所以就抛砖引玉,先写一个简单可用的版本。 如果有更复杂的场景,欢迎回复此issue。
用了框架寫了個簡單程式,有些網站能抓,有些網站出現timeout,想請問這個可能是哪方面的問題,看了許久,找不出問題。 目前抓取的網站是: https://www.arrow.com/en/categories/diodes-transistors-and-thyristors/bipolar-transistors/rf-bjt?page=1 代碼如下: public class ArrowPageProcessor implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000).addHeader("user-agent","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.83 Safari/537.36"); @Override public void...
第一个爬虫项目启动失败
 如图 点击不同tab 渲染出不同的内容,如何让爬虫爬取默认点击tab后 继续点击其他tab 并获取内容! 求解
 
样例链接:https://chejiahao.autohome.com.cn/info/10349473#pvareaid=6826274 获取文章内容xpath:/html/body/div[4]/div[2]/div[1]/div[3]/div/div[1]/div[1] 通过page.getHtml()查看某一图片链接: ` ` 实际图片链接地址: `` 推测是因为图片链接中有`|`导致被截取,望修复
Metadata
Owner
Metadata
A scalable web crawler framework for Java.