Fine-tunning for table data extraction
Hi,
is it possible to train donut for table data extraction and if so how would one build the metadata.jsonl gt_parse to include rowspans and collspans?
I want to extract all rows / columns of all tables in the image.
For example this table:
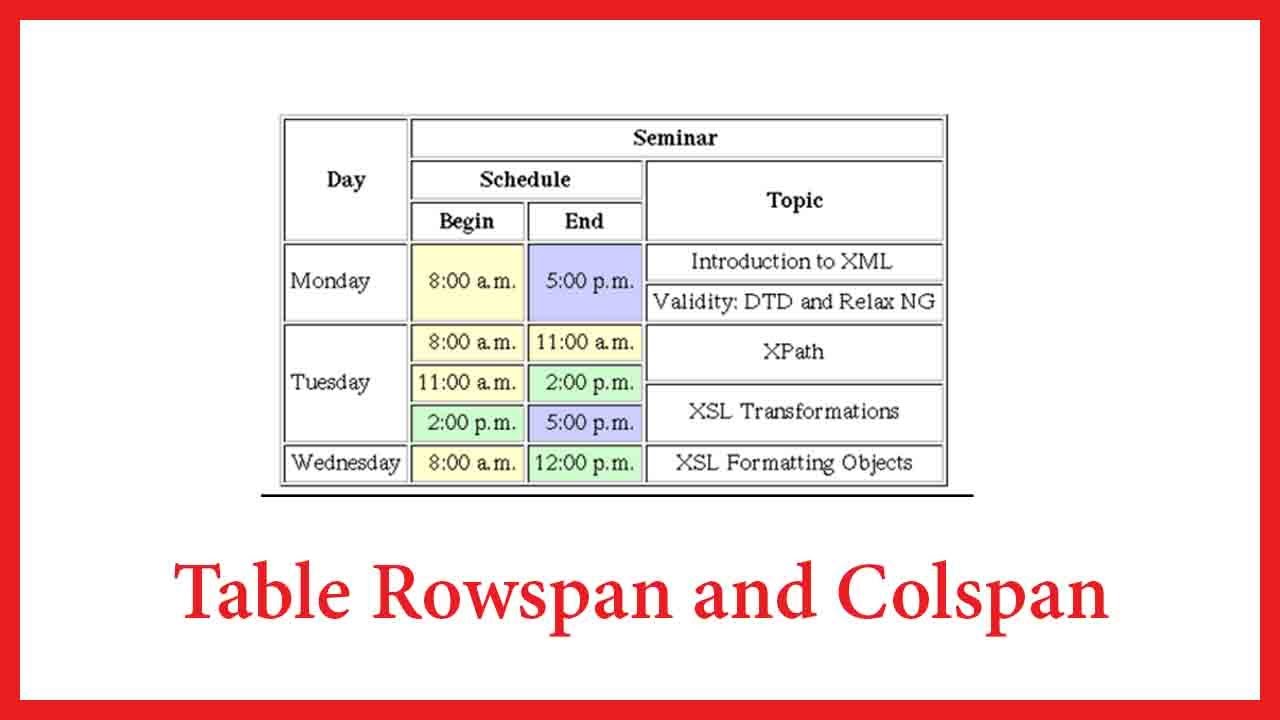
Is this format allowed or si it a better option to specify if a row/col is spanned over multiple rows/cols?
{
table: [
{
rows: [
[
{ 0: 'Day', 1: 'Seminar', 2: 'Seminar', 3: 'Seminar' },
{ 0: 'Day', 1: 'Schedule', 2: 'Schedule', 3: 'Topic' },
{ 0: 'Day', 1: 'Begin', 2: 'End', 3: 'Topic' },
],
[
{ 0: 'Monday', 1: '8:00 a.m.', 2: '5:00 p.m.', 3: 'Introduction to XML' },
{ 0: 'Monday', 1: '8:00 a.m.', 2: '5:00 p.m.', 3: 'Validity DTD and Relax NG' },
]
],
},
],
...
}
Thanks
I think the best option would be to to add some new special tokens (
Then, train donut to predict your structure and you are good to go. It will require some creativity, but I'm sure you'll get it 👌
Here's a naive sample I might make to represent a row with 2 columns. However, multi spanning rows/columns might take come more thought
<row><col>col1</col><col>col2</col></row>
I think the best option would be to to add some new special tokens ( , as an example) and define your own output structure that you can parse
Then, train donut to predict your structure and you are good to go. It will require some creativity, but I'm sure you'll get it 👌
Here's a naive sample I might make to represent a row with 2 columns. However, multi spanning rows/columns might take come more thought
<row><col>col1</col><col>col2</col></row>
How can we add special tokens? e.g. I've task similar to parsing but in a slightly different format
{
k1: v1,
k2: v2,
...
k3: [
{
k4: v4,
...
},
{
k5: v5,
...
},
]
}
but this donut model seems to be missing "[" and "]" i.e. array of dictionaries w.r.t k3
i.e. output for this section as as follows
<k3><k4><v4>...<sep/><k5><v5>...<sep/>
So how can I make the model learn to output "[" ?
here is a test i've done, without adding special tokens:
{"file_name":"PMC1064074_table_0.jpg","ground_truth":"{\"gt_parse\":{\"cells\":[{\"row_0_col_0\":\"Kinetic parameter\"},{\"row_0_col_1\":\"ND\"},{\"row_0_col_2\":\"D\"},{\"row_0_col_3\":\"D + dn-RhoA\"},{\"row_0_col_4\":\"D + dn-Rac1\"},{\"row_1_col_0\":\"Vmax\"},{\"row_1_col_1\":\"19.6 ± 0.75\"},{\"row_1_col_2\":\"26.2 ± 0.86*\"},{\"row_1_col_3\":\"31.3 ± 0.88†\"},{\"row_1_col_4\":\"21.6 ± 0.9\"},{\"row_2_col_0\":\"K' for H+\"},{\"row_2_col_1\":\"0.150 ± 0.02\"},{\"row_2_col_2\":\"0.113 ± 0.05†\"},{\"row_2_col_3\":\"0.105 ± 0.07†\"},{\"row_2_col_4\":\"0.137 ± 0.023\"},{\"row_3_col_0\":\"napp\"},{\"row_3_col_1\":\"2.19\"},{\"row_3_col_2\":\"2.16\"},{\"row_3_col_3\":\"2.03\"},{\"row_3_col_4\":\"2.23\"}]}}"}
You can try something like this...
{"file_name": "image.jpg", "ground_truth": "{\"gt_parse\":{\"k1\":\"v1\",\"k2\":\"v2\",k3\":[{\"k4\":\"v4\"},{\"k5\":\"v5\"} ...}]}}"}
Can anybody tell me whether this has been resolved or not because I am also working on the same problem. If this has been done then please tell me what was the accuracy of the fine-tune model?