cloudhan
![]()
cloudhan

@zjing14 This is a fully correct pipeline that support packed fp4 (2 `int4`s in a byte). This is used for demonstrate what might need to be changed to support subtype...
Sequence length 1 is extremely important for decoding (ASR, text generation, etc) In onnxruntime, we found the rocblas gemm + sofmax kernel +rocblas gemm is much faster for this case,...
Current client API `ck::tensor_operation::device::DeviceBatchedGemmSoftmaxGemmPermute` only has 1 D0 and exact 1 D0 version build into the client library. The non-bias version have no instance builtin. Please add instance to the...
In the 2024-02-02 blog post, for example 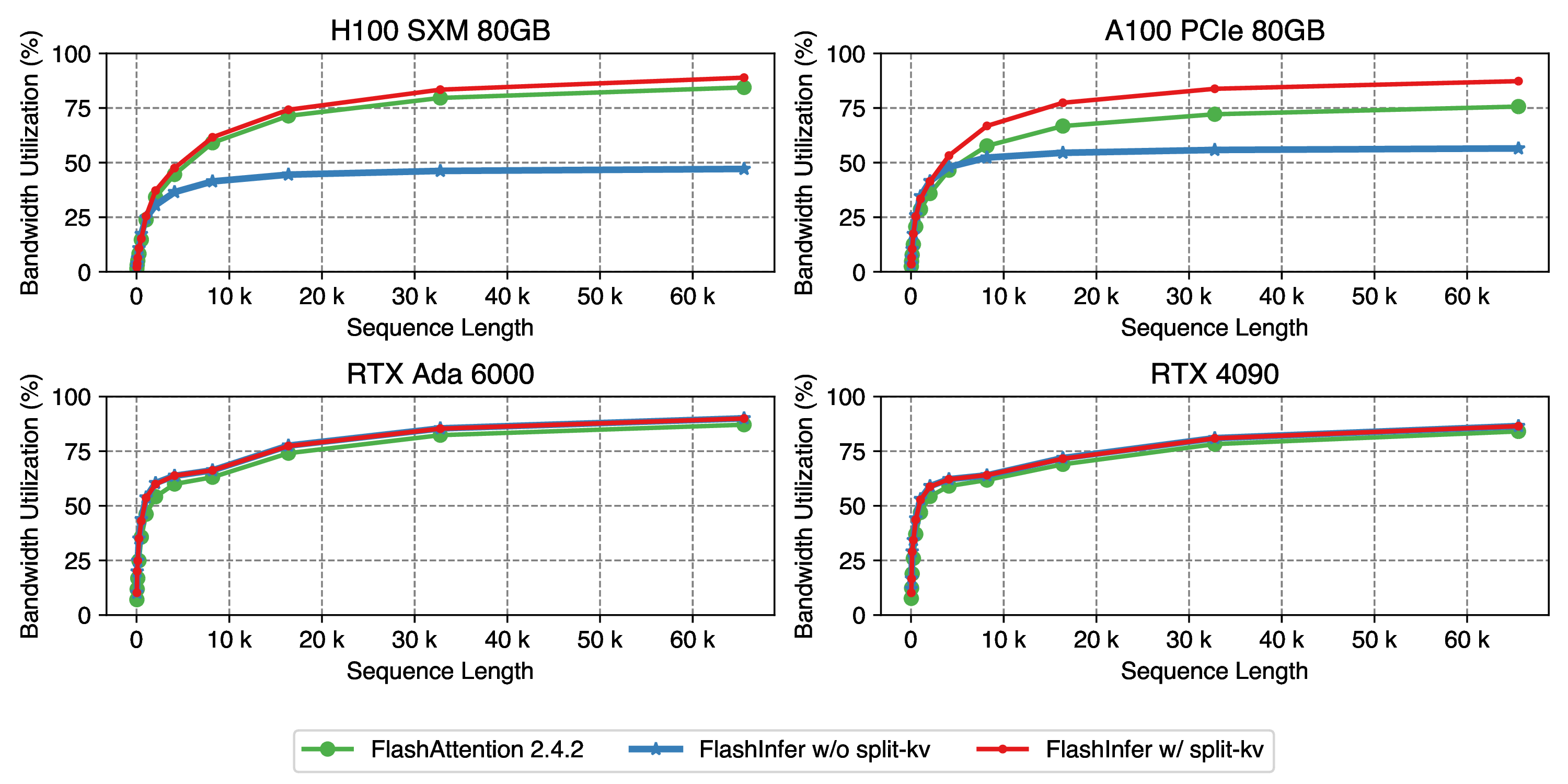 I tried to repro it simply with ncu data for numseq 1 and seqlen 16384 on 4090: ``` void vllm::paged_attention_v2_kernel(float *, float...
depends on - [x] #20913 - [x] #21028 - [x] #21030
Allow colorize only one thread of `print_latex`, to make mma pattern obvious and reduce eye strain. For example, ```cpp #include "cute/tensor.hpp" using namespace cute; int main() { auto tiled_mma =...
**Describe the bug** ```cuda #include "cute/tensor.hpp" using namespace cute; __global__ void kernel(int *gmem) { int tid = threadIdx.x; gmem[tid * 4 + 0] = tid * 4 + 0; gmem[tid...
The set of kernels was integrated in our fork of vllm previously, now porting them to onnxruntime as a native OpKernel for potential future development. Feature set: Decomposed scheduler and...
1. Clip can be removed iff the codoamin of QuantizeLinear remain unchanged. 2. To remain unchanged, y=QuantizeLinear(Clip(x)) must span the full range of values that can be represented by the...