closertb.github.io
 closertb.github.io copied to clipboard
closertb.github.io copied to clipboard
用React + Github Graphql API自定义你的博客
前言
国庆七天,就这样没了,以不想看人海的借口(9 s q),在家里白吃白喝待了七天。但作为前端练习生的我,又有时间倒腾了,这不,夜深人静时,用React + Github Issues + Github Graphql API + Github Action + Github Pages重写了自己的博客。
- 我的新博客站点
- 如果你对下面的实现过程没兴趣,可直接查看最后一节快速搭建属于你的博客
目的意图
以前是用Hexo搭的, 那为什么要换,嗯........图个乐。其实还有就是:阿里云又让续费服务器了;用segmentfault做自己的文件存储计划失效了(图片链接有时效性,动态的);hexo上条条框框太多了,博客资源仓库是静态的,都是离线编写。那为什么又要用上面的那一堆东西呢?嗯,是这样的:
- React : 三大框架,也就这个入了门,写起来快;
- Github Issues:博客数据库加图片文件存储,一箭双雕, 有时间再整个评论,直接帽子戏法;
- Github Graphql API:博客数据库(Issues)读取接口,为什么不用V3,接口返回东西太多,浪费带宽;
- Github Action:Github去年出的新功能-持续集成服务,可用于打包构建部署静态资源;
- Github Pages:服务器就不续费了,钱省下吃火锅。Pages用起挺好,还白送个域名,而且还免费配置了gzip,缓存策略
权限申请
Github Graphql Api 访问token
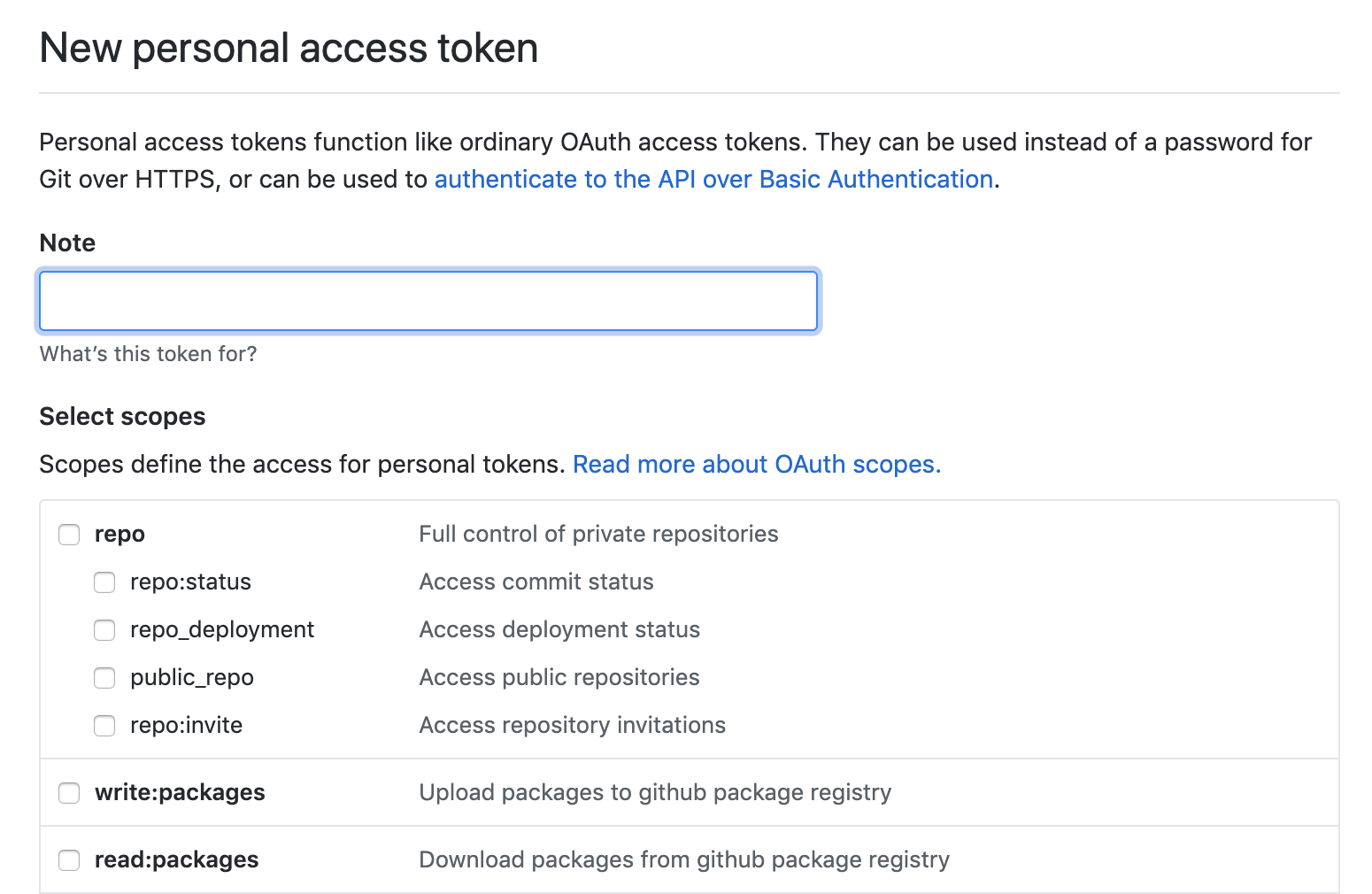
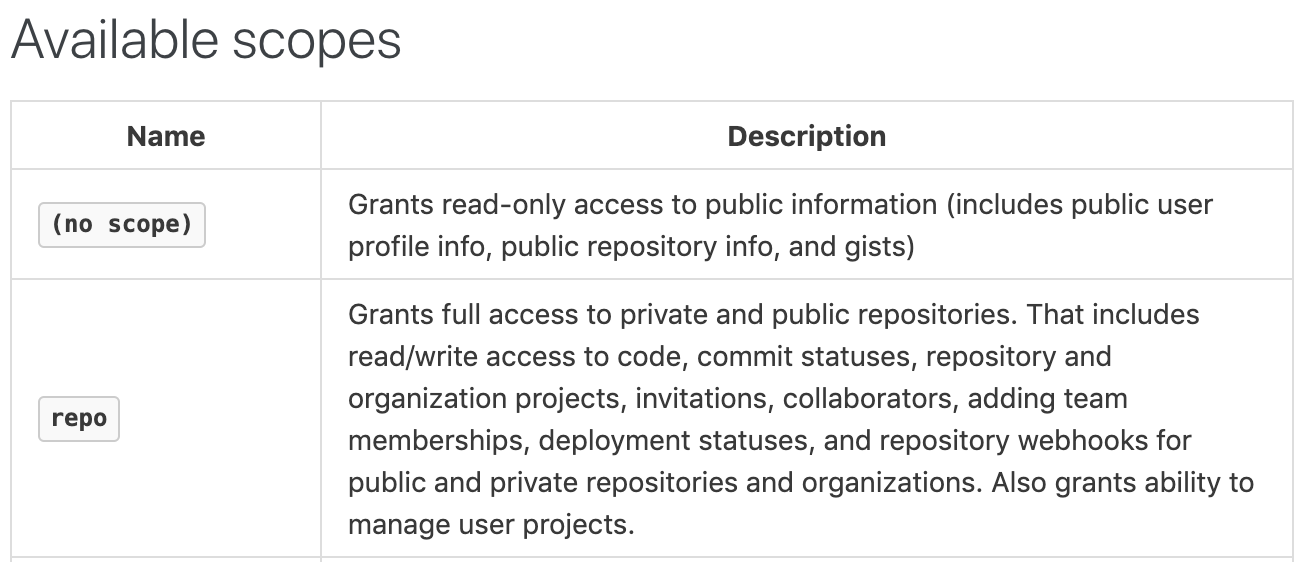
Github API V3版提供的Restful接口,可以直接访问,不需要鉴权,但访问次数有限制。而对于Github API V4,即Graphql接口,需要鉴权,所以我们需要申请一个token,具体步骤是:登录你的github -> Settings -> Developer settings -> Personal access tokens -> Generate New。 如下图所示,我们需要设置这个token的操作范围,出于安全的考虑,这里不做任何勾选。这样做对应的权限是no_scope,对应的权限是只读,可通过下面的图片和链接获取详细的权限范围。
Github Action 部署权限
关于Github Action是什么,还未了解的,可以阅读官方文档, 也可以自己Goggle一下。在后续Github Pages的部署,会用到一对秘钥,可以通过下面的命令在cmd中生成:
ssh-keygen -t rsa -b 4096 -C "$(git config user.email)" -f gh-pages -N ""
然后在你的当前目录会得到如下两个文件(gh-pages 与 gh-pages.pub):

然后参照Github上一个现成的手把手部署文档,在你的项目中设置这对秘钥。在后面的项目部署再细讲。
博客代码实现
其实一个简单的博客,就一个列表页和一个详情页,列表页就是展示你写了哪些文章,而详情页就是展示文章具体内容;下面的代码不会涉及到页面UI的设计及项目架构设计,重点讲与github的接口交互实现,想直接看源码实现的,可以直接clone下载下来看:
git clone -b blog https://github.com/closertb/closertb.github.io.git
写前须知
- React: 只涉及到React-Router这个生态,页面全部用函数式组件编写,所以Hooks有必要了解一下;
- 关于Graphql: 可以查看官网介绍, 也可以查看我之前写过的文章:
- 同学,GraphQL了解一下:基础篇,
- 同学,GraphQL了解一下:实践篇,
- GraphQL进阶篇: 挥手Redux不是梦, 看前两篇就够用了;
- 关于apollo graphql: 一个Graphql的第三方框架,可查看官网介绍,在上面的两篇文章也有提及,重点看下query就行了;
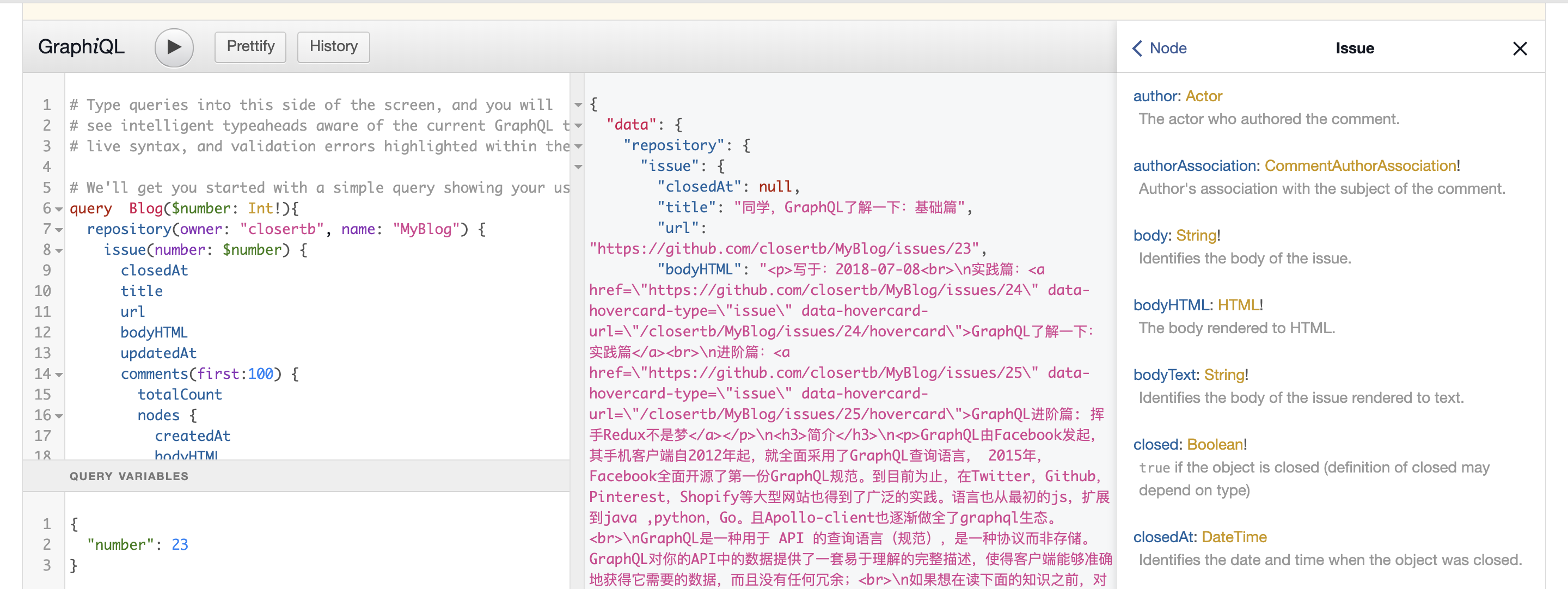
- Github Graphql API: 官网链接,但相信我,在官网学Github API是相当低效的,Graphql的优势就是接口实现了,运用Graphiql界面技术,相应的接口文档就出来了,官网也提供了这样的界面:Graphql Explorer, 你可以复制下面的代码到Graphql Explorer,并改成你自己的项目进行尝试(需删掉注释)
query {
repository(owner: "closertb", name: "closertb.github.io") {
issues(last: 10, states:OPEN, orderBy: {
field: CREATED_AT
direction: DESC
}) {
totalCount
edges {
cursor // 节点标志位, 后面分页会用到
node {
title
url
createdAt
updatedAt
reactions(first: 100) { // issue动态,什么赞,踩,喝彩这些
totalCount
nodes {
content
}
}
}
}
}
}
}
建立Graphq客户端
建立Graphql客户端,类似于我们写常规请求时,要初始化一个Http类或Axios类,来配置请求的目标域名与验证令牌,这个也是相似的;这里就会用到了前面申请的Github Graphql API 访问token,都是一些Api调用,直接上代码:
// Initialize
const cache = new InMemoryCache();
const authLink = setContext((_, { headers }) => ({
headers: {
...headers,
Authorization: `bearer ${token}`, // 申请的token
}
}));
const httpLink = new HttpLink({
uri: 'https://api.github.com/graphql', // 所有请求的Url
batchInterval: 10,
opts: {
credentials: 'cross-origin',
},
});
const client = new ApolloClient({
clientState: { resolvers, defaults, cache, typeDefs },
cache, // 本地数据存储, 暂时用不上
link: authLink.concat(httpLink)
});
function App() {
return (
<ApolloProvider client={client}>
<LayoutRouter />
</ApolloProvider>
);
}
这里关注一下uri 与 header的设置就行了。
列表页的实现
列表的展示,链接可点
列表的展示,主要就涉及到文章标题、文章发布日期、关联Issue、相关动态(赞,评论数量什么的),简略版的如我写的这样;
 最难的,就是写Graphql查询语句了,但幸好有了Graphql Explorer的存在,我们可以无限次的尝试自己写的sql语句,最后版的sql与上面的相似,只不过涉及到动态传参与graphql-tag转化:
最难的,就是写Graphql查询语句了,但幸好有了Graphql Explorer的存在,我们可以无限次的尝试自己写的sql语句,最后版的sql与上面的相似,只不过涉及到动态传参与graphql-tag转化:
import gql from 'graphql-tag';
import { OWNER, PROJECT } from '../../configs/constants';
/**
* @param pageBefore: 向前查的标志节点
* @param pageAfter: 向后查的标志节点
* @param pageFirst: 向前查的条数
* @param pageLast: 向后查的条数
* 说明: 查询时,pageFirst与pageAfter设置值,即为向后翻页;pageLast与pageBefore设置值,即为向后翻页
*/
export const sql = gql`
query Blog($pageFirst: Int, $pageLast: Int, $pageBefore: String, $pageAfter: String){
repository(owner: ${OWNER}, name: ${PROJECT}) {
sshUrl
issues(first: $pageFirst, last: $pageLast, states:OPEN, before: $pageBefore, after: $pageAfter, orderBy: {
field: CREATED_AT
direction: DESC
}, filterBy: {
createdBy: "closertb"
}) {
totalCount
edges {
cursor
node {
title
url
createdAt
updatedAt
reactions(first: 100) {
totalCount
nodes {
content
}
}
}
}
}
}
}`;
上面这段语句的语义化还是相当明显了,就不再过多说明了。然后直接采用apollo提供的查询hooks:useQuery,通过传入sql语句与查询变量,hooks将返回三个值(loading, error, data),我们优先处理错误,然后处理请求中的状态,当没有错误并请求完成的时候,展示列表,原理很简单,直接看代码:
export default function Blog() {
const query = { pageFirst: 10 };
const { loading, error, data } = useQuery(sql, {
variables: query
});
if (error) {
return (<p>{error.message || '未知错误'}</p>);
}
if (loading) {
return (<p>loading</p>);
}
const { repository: { issues: { totalCount = 0, edges = [] } } } = data;
return (
<div className="list-wrapper">
<ul>
{edges.map(({ node: { title, url, updatedAt } }) => (
<li className="block" key={url}>
<h4 className="title">
<Link to={`/blog/${url.replace(/.*issues\//, '')}`}>{title}</Link>
</h4>
<div className="info">
<div className="reactions">
<a href={url} target="_blank" rel="noopener noreferrer">Issue链接</a>
</div>
<span className="create-time">
{updatedAt}
</span>
</div>
</li>
))}
</ul>
</div>);
上下翻页的实现
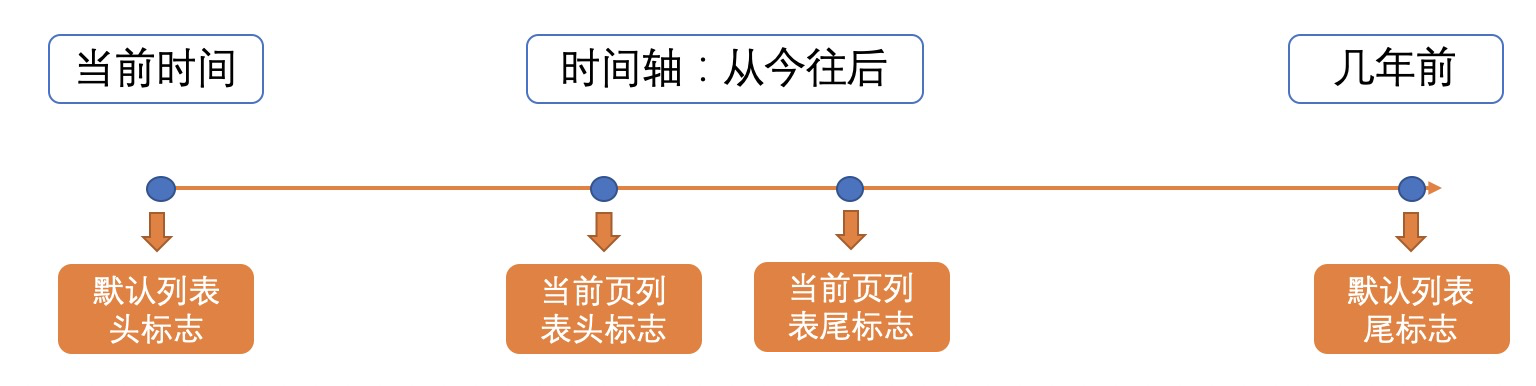
列表的主要难点,主要体现在翻页的实现上。常用的restful接口,我们在查询时,只需传入page和pageSize,即可获取要查询页的数据。但Github的Graphql接口并没有这样做,而是以另一种思维来做了这件事,把所有的Issue整理在一张时间轴上(如下图所示),每一个Issue都作为一个节点(用cursor标识),举例说,当我们查最近(first)的10条,如果我们不传标识,接口会默认以第一条issue作为标识,取最近的10条:而如果传了一个有效的标识,接口会以这个标识往后取最近的10条,很简单有没有。现在就来实现翻页的代码。
 这里我们采用了useState, useRef, useCallback三个hooks来实现
这里我们采用了useState, useRef, useCallback三个hooks来实现
export default function Blog() {
const [param, setParam] = useState({ pageFirst: PAGE_SIZE, current: 1 });
const pageRef = useRef();
const setCursorBack = useCallback((data) => {
const { repository: { issues: { edges } } } = data;
pageRef.current = {
pageBefore: edges[0].cursor,
pageAfter: edges[edges.length - 1].cursor
};
});
const setNextPage = useCallback(dir => () => {
const { pageAfter, pageBefore } = pageRef.current;
// dir: true 为向下, false 为向上
setParam(dir ?
{ pageFirst: PAGE_SIZE, pageAfter, current: param.current + 1 } :
{ pageLast: PAGE_SIZE, pageBefore, current: param.current - 1 });
});
const { current, ...query } = param;
// ...接上面的代码
// 回调存储表要的临时变量
if (!loading && !error && callback) {
setCursorBack(data);
}
return (
<div className="list-wrapper">
<ul>
{/* ...接上面的代码 */}
</ul>
<div className="page-jump">
{current !== 1 && <a className="last" onClick={setNextPage(false)}>上一页</a>}
{current < (issues.totalCount / PAGE_SIZE) && <a className="next" onClick={setNextPage(true)}>下一页</a>}
</div>
</div>);
}
上面代码仅是思路,具体实现请参看源码。大概说一下,用了current来存储当前的查询参数和当前页码,通过setParam触发翻页查询,使用一个ref来存储当前列表的头部和尾部标识位,用于下一次翻页查询。
详情页的实现
详情页的实现比列表页更简单,在Github V3 Restful接口中,返回的issue详情,返回的body是md格式字符串,你需要自己转码才能在页面上展示。而在Graphql接口的返回里,你可以选择md格式,也可以选择html格式的返回值,当然聪明点的,都会直接选择html,然后展示样式直接复用github的文章样式。
但除了文章详情,更友好的交互,还会在页末展示上一篇,下一篇这种。在api中这个也是没有现成接口的,但我们可以用类似上面翻页的思路来实现,我们以当前文章为标识位,查找上一篇和下一篇文章列表。在Restful接口中,这种我们一般都是先查出详情,然后再发送请求查上一篇和下一篇。这时候graphql接口的优势又体现的淋漓尽致,看下面代码实现, 查询代码较长,作用分别是查询当前文章详情(issue),查询上一篇文章(last), 查询下一篇文章(next),一次查询,做三件事:
/**
* @param: number 文章索引编号
* @param: cursor 当前文章标识,用于查上一篇,下一篇
*/
export const sql = gql`query BlogDetail($number: Int!, $cursor: String) {
repository(owner: ${OWNER}, name: ${PROJECT}) {
issue(number: $number) {
title
url
bodyHTML
updatedAt
comments(first:100) {
totalCount
nodes {
createdAt
bodyHTML
author {
login
avatarUrl
}
}
}
reactions(first: 100) {
totalCount
nodes {
content
}
}
}
last: issues(last: 1, before: $cursor, orderBy: {
field: CREATED_AT
direction: DESC
}, filterBy: {
createdBy: "closertb"
}) {
edges {
cursor
node {
title
url
}
}
}
next: issues(first: 1, after: $cursor, orderBy: {
field: CREATED_AT
direction: DESC
}, filterBy: {
createdBy: "closertb"
}) {
edges {
cursor
node {
title
url
}
}
}
}
}`;
因为使用的是react,我们直接拿到了详情的html,所以使用了dangerouslySetInnerHTML这个属性。具体实现代码如下:
function RelateLink({ data, className }) {
const { edges = [] } = data;
if (edges.length === 0) {
return null;
}
const { cursor, node: { title, url } } = edges[0];
return (<Link className={className} to={`/blog/${url.replace(/.*issues\//, '')}?cursor=${cursor}`}>{title}</Link>);
}
export default function BlogDetail({ location: { pathname, search = '' } }) {
const number = pathname.replace('/blog/', '');
if (typeof number !== 'string' && typeof +number !== 'number') {
return <div className="content-waring">路径无效</div>;
}
// 提取cursor
const cursor = search ?
search.slice(1).split('&').find(item => item.includes('cursor=')).replace('cursor=', '') :
undefined;
const param = { number: +number, cursor };
const { loading, error, data = {} } = useQuery(sql, param);
// ...loading , error 处理什么的
const { repository: { issue: { title, url, bodyHTML, updatedAt }, last = {}, next = {} } } = data;
return (
<div className={style.Detail}>
<div className="header">
<h3 className="title">{title}</h3>
<div className="info">
<a href={url} target="_blank" rel="noopener noreferrer">issue链接</a>
<span>更新于:{DateFormat(updatedAt)}</span>
</div>
</div>
<div className="markdown-body" dangerouslySetInnerHTML={{ __html: bodyHTML }} />
<div className="page-jump">
<RelateLink data={last} className="last" />
<RelateLink data={next} className="next" />
</div>
</div>
);
}
至此,一个简单的博客功能就完成了。
其他
- 统一错误的处理
- 统一loading动画的处理
- 博客更新很慢,请求接口结果缓存也是很重要的
- 移动端的适配
- 评论什么的展示
这些都是一些很平常的方案,有兴趣的可查看源码;
Github Action构建打包
Github去年出的新功能-持续集成服务,作为前端的我们,可用于打包构建部署静态资源。如果你还不了解,可自行Goggle(baidu)一下或查看官方文档。而关于github page项目自动打包部署,可查看这篇文章了解, 只提醒这两点,就是user pages站点(xxx.github.io),这个pages的静态资源没法选资源和资源文件夹,静态资源默认部署到master分支根目录的,所以资源推送是配置要注意。
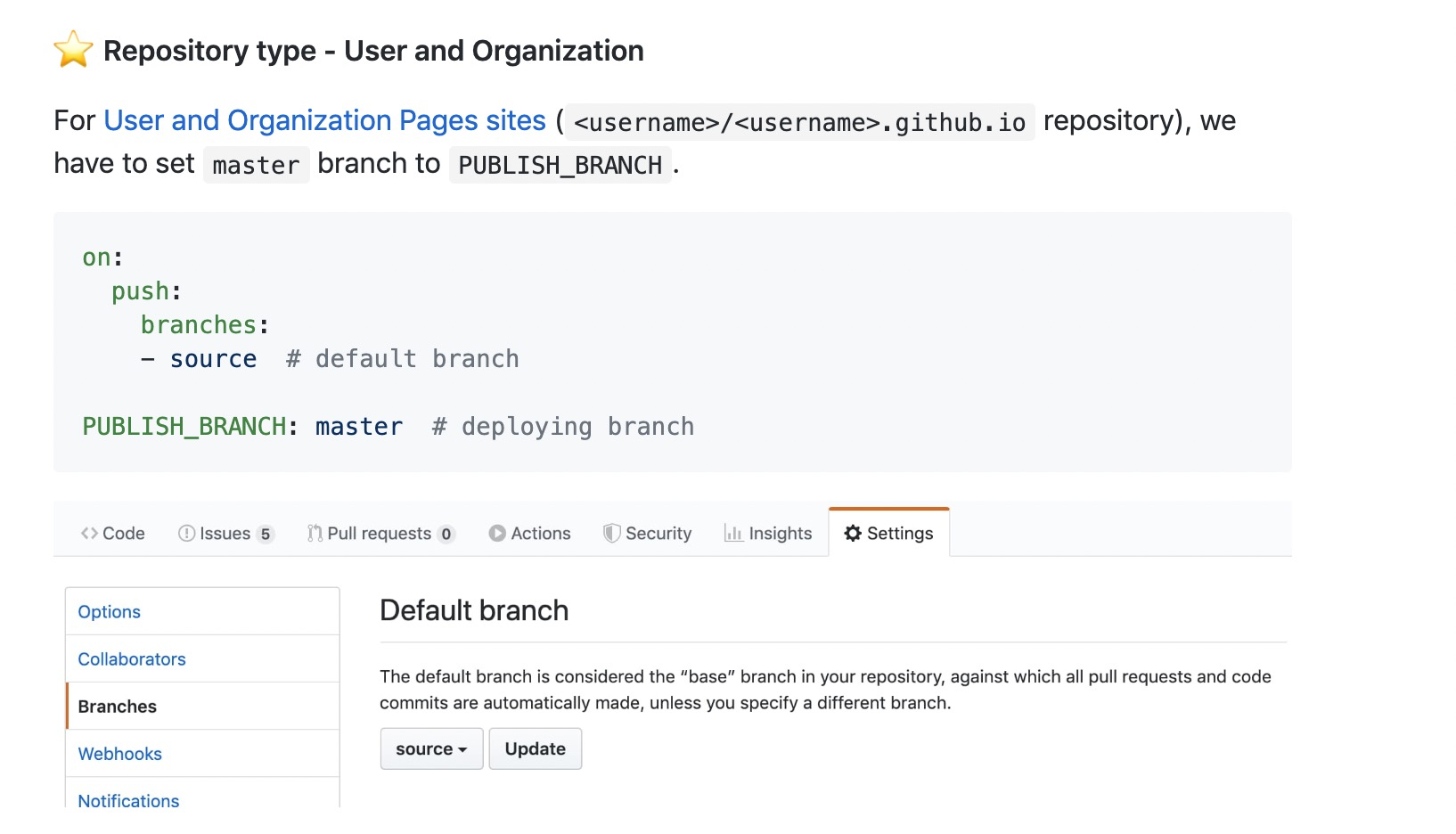
快速搭建属于你的博客
项目Copy
可采用下面两种方式:
- create-doddle脚手架,得到的是干净的项目:
npx create-doddle github yourblogName
- 直接clone博客源码blog分支
git clone -b blog https://github.com/closertb/closertb.github.io.git
然后:
npm i
github项目创建
如果你和我一样,有现成的pages(特指:xxx.github.io), 那你可以忽略这一步。这个项目将用于issues的创建(数据仓库),博客源码的存放(我新建了blog分支),博客静态资源的部署(master分支)。愿你以前就存在一个用issue写博客的好习惯。搬运博客文章,我至少搬了一天。如果没有github pages,那你还需要去创建一个pages项目,步骤很简单,看这里,一个普通项目也行,但需要开通pages功能。
修改配置
- 修改configs/constants文件中的配置 :
/* Github个人信息相关 */
export const SITE_NAME = '网站标题'; // 网站标题
export const SITE_ADDRESS = '你网站网址'; // 网站地址,可为空
export const SITE_MOTTO = '一个落魄前端工程师'; // 一句段子,可为空
export const OWNER = 'xxx'; // 你github名
export const PROJECT = '"xxx.github.io"'; // 你issue项目名, 就是上一步创建的项目名,注意用pages做项目名时,需要用双引号括起来
// 由于github安全保护规则,token不能暴露到仓库中,但又因为我们申请的token只是一个只读token,所以这里使用了简单函数进行了对称加解密,以绕开规则;
export const TOKEN = '你申请的token,参见申请权限章节';
export const GITHUB_URL = 'https://github.com/xxx'; // 你的github主页地址
然后npm start; 项目在本地已经能跑起来了,看看数据是否和你issue的吻合。 2. 修改.github/workflow/nodejs.yml构建配置,具体可参见上一节的构建打包: 主要修改点就是你监听的分支、token变量名与构建结果要推送的地址;
on:
push:
branches:
- blog // 你源代码分支
- name: deploy
uses: peaceiris/[email protected]
env:
ACTIONS_DEPLOY_KEY: ${{ secrets.Deploy_Access_Token }}
PUBLISH_BRANCH: master // pages 只能推master分支
PUBLISH_DIR: './dist'
- git init, 然后设置到你自己的项目上去,然后push, 等待构建结果,完成,你的pages仓库应该就有你构建后的代码了,访问xxx.github.io, 就能看到你的线上项目了;
- 至此,完成。如果你还需要设置CNAME解析,可在public文件夹添加CNAME文件,打包构建时会自动给你部署到根目录;
写在最后
如果你还有任何疑问,可在这篇文章下留下你的评论
请教一下,你把Authorization放在header,再graphql的server端,是用什么方式来验证每次请求的Authorization呢
用directive做吗?
请教一下,你把Authorization放在header,再graphql的server端,是用什么方式来验证每次请求的Authorization呢
用directive做吗?
我不用验证,我的服务其实只做了转发。真正的服务是github graphql server,它在做鉴权