PyPDF4
 PyPDF4 copied to clipboard
PyPDF4 copied to clipboard
Crop files *before* merging them
This issue has been cross-posted as mstamy2/PyPDF3#11, since it affects both projects.
Note: All PDF described here are available for download at the end of this message.
I have a two-pages PDF file looking like that:

What is not visible here is that I crafted this PDF so that the shapes go over the edges: half the circles and half the squares are not visible (outside the edges). Now, if I run the following script (to put the two pages side by side on a single, bigger page):
import PyPDF4
from PyPDF4.generic import RectangleObject
dest = PyPDF4.PdfFileWriter()
page = dest.addBlankPage(595, 421)
source = PyPDF4.PdfFileReader("overflow.pdf")
page0 = source.getPage(0)
# The following lines seem useless (even uncommented)
# page0.mediaBox = RectangleObject([50, 100, 150, 200])
# page0.trimBox = RectangleObject([50, 100, 150, 200])
# page0.cropBox = RectangleObject([50, 100, 150, 200])
# page0.bleedBox = RectangleObject([50, 100, 150, 200])
# page0.artBox = RectangleObject([50, 100, 150, 200])
page.mergeTranslatedPage(page0, 0, 0)
page1 = source.getPage(1)
page.mergeTranslatedPage(page1, 297, 0)
with open("output.pdf", "bw") as output:
dest.write(output)
print("The End")
I get the following result, which is wrong, because the shapes overflow on the other page.
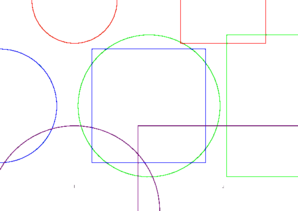
I would like to have the following result, where the source pages are cropped before being merged.
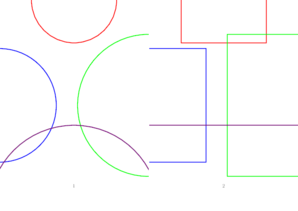
I tried playing with the *boxes (trimBox, bleedBox, cropBox, etc.) but:
- changing those boxes on the source pages does not change anything;
- changing those boxes on the output page, but both (original) pages are cropped at once, which does not give the expected result.
Is there a way to get the expected result, that is: crop the source pages, then merge them?
Thanks, -- Louis
Downloads:
Hi. I've wrote in pyPDF3 Repo : I am interested in this topic. I have been researching a lot of time and the only way to solve it is to regenerate the PDF using pdftocairo or ghostscript (gs) before merging
Hi. I've wrote in pyPDF3 Repo : I am interested in this topic. I have been researching a lot of time and the only way to solve it is to regenerate the PDF using pdftocairo or ghostscript (gs) before merging
@jserrano-rebold struggling with the same topic right now. could you tell me more about how you used pdftocairo to regenerate? do you mean pdf to pdf or rasterizing to png for example?
Hi. I've wrote in pyPDF3 Repo : I am interested in this topic. I have been researching a lot of time and the only way to solve it is to regenerate the PDF using pdftocairo or ghostscript (gs) before merging
@jserrano-rebold struggling with the same topic right now. could you tell me more about how you used pdftocairo to regenerate? do you mean pdf to pdf or rasterizing to png for example?
@canedha Yes pdf to pdf. This is my code:
def pdfregenerar_cairo(pdf_file, pdf_out, width=None, height=None):
command = 'pdftocairo -pdf -nocenter'
if width is not None and height is not None:
# Evita el problema con pdftocairo que no permite desactivar el autorotate.
# y cuando el width es más grande que height rota la página.
if height >= width:
command += ' -paperw {} -paperh {}'.format(int(math.ceil(width)),int( math.ceil(height)))
else:
command += ' -paperh {} -paperw {}'.format(int(math.ceil(width)),int( math.ceil(height)))
else:
command += ' -noshrink'
command += ' {} {}'.format(pdf_file, pdf_out)
output = None
try:
p = subprocess.Popen(command, universal_newlines=True, shell=True,
stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
output = p.stdout.read()
retcode = p.wait()
res = True
except subprocess.CalledProcessError:
res = False
if output is None:
output = 'Error en la regeneración (cairo) del PDF.'
except Exception as e:
res = False
if output is None:
output = 'Error en la regeneración (cairo) del PDF: {}' % format(e)
return (res, output)
@jserrano-rebold thanks so much for your reply! have 2 more questions : after the regeneration the cropped region will be merged correctly into a larger page? do you maybe also know if after your regeneration the pdf still contains all information (if viewmcropbox is widened again ) or if the regeneration works as an destructive crop deleting all information outside the viewbox?
@jserrano-rebold thanks so much for your reply! have 2 more questions : after the regeneration the cropped region will be merged correctly into a larger page? do you maybe also know if after your regeneration the pdf still contains all information (if viewmcropbox is widened again ) or if the regeneration works as an destructive crop deleting all information outside the viewbox?
I always merge the regemerated cropped file in a DinA4 page and normally information outside de cropped box is destroyed. Sometimes I have found cases (very few) of frames within the PDF that have'nt been completely removed and since it is not text, to be sure, I finally cover it by merging with a mask page that I generate with reportlab (white rectangles around the clipping box).
@jserrano-rebold thanks for the clarification! would you have a code snippet for the mask page for me as well? you do not know how much this helps me! struggling with this stuff for days now.
@canedha This is a snippet of the code.
I put the clipping in the center of a DinA4 page. The margin variable contains the left, bottom, right, and top margins of the centered clipping. Then I merge this page / PDF generated in this code with the DinA4 page that contains the centered clipping.
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
from reportlab.lib.utils import ImageReader
from reportlab.lib import colors
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.platypus import Paragraph, Frame, XBox, KeepInFrame
from reportlab.lib.enums import TA_LEFT, TA_RIGHT, TA_CENTER, TA_JUSTIFY
pdf_aux = tempfile.NamedTemporaryFile(suffix='_aux.PDF').name
pdf = canvas.Canvas(pdf_aux)
dpi_pdf = 72
anchoPag = ((210/25.4) * dpi_pdf) # Ancho Total pixels A4
altoPag = ((297/25.4) * dpi_pdf) # Alto Total pixels A4
if margin is not None:
pdf.setFillColorRGB(1, 1, 1)
# marco izquierda
pdf.rect(0, 0, margin[0], altoPag, stroke=0, fill=1)
# marco derecha
pdf.rect(anchoPag-margin[2], 0, margin[2], altoPag, stroke=0, fill=1)
# marco debajo
pdf.rect(0, 0, anchoPag, margin[1], stroke=0, fill=1)
# marco encima
pdf.rect(0, altoPag-margin[3], anchoPag, margin[3], stroke=0, fill=1)
# generamos la cabecera del PDF
self.generar_cabecera_pdf(noticia_obj, recorte_obj, archivo_pagina, marca, pdf)
pdf.showPage()
pdf.save()