spark sql cast问题分析
背景
今天小伙伴有个sql跑的不符合他预期,想了解下到底是什么原因造成的
他的sql是
select "0.88" = 0 a,"0" = 0 b
但输出都是true
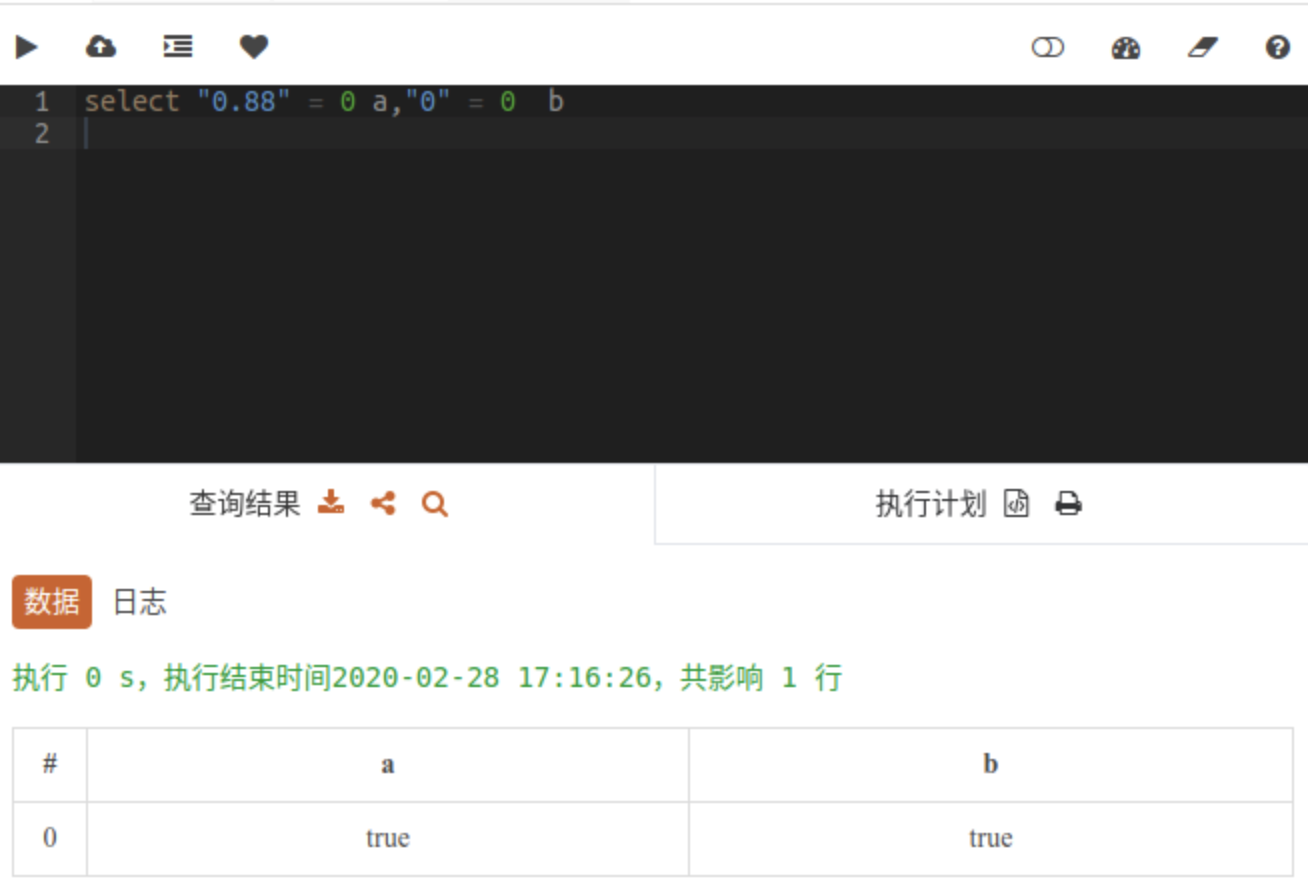
他能理解"0" = 0 ,但是理解不了"0.88" = 0 这种情况,所以想问下为什么
分析
相信有经验小伙伴应该马上反应什么原因造成的,但有些小伙伴没有相关经验,所以我们就带大家分析下这个问题
第一步Explain
遇到不符合预期的sql,第一反应就是打一个explain
== Parsed Logical Plan ==
'Project [(0.88 = 0) AS a#1499530, (0 = 0) AS b#1499531]
+- OneRowRelation
== Analyzed Logical Plan ==
a: boolean, b: boolean
Project [(cast(0.88 as int) = 0) AS a#1499530, (cast(0 as int) = 0) AS b#1499531]
+- OneRowRelation
== Optimized Logical Plan ==
Project [true AS a#1499530, true AS b#1499531]
+- OneRowRelation
== Physical Plan ==
*(1) Project [true AS a#1499530, true AS b#1499531]
+- Scan OneRowRelation[]
从plan中我们已经看出了问题出现在cast上了,在analyze阶段将0.88cast成int了,所以最终是0 =0 的比较,返回true
第二步快速定位规则
对于快速定位catalyst的代码,我的建议是用trace log,这样比你用断点通常快很多,对比下trace log基本能很快找到哪个rule造成的
那就让我们开启相关日志跑一下吧:
o.a.s.s.c.a.Analyzer$ResolveReferences - Attempting to resolve 'Project [(0.88 = 0) AS a#0, (0 = 0) AS b#1]
11:35:20.281 TRACE o.a.s.s.h.HiveSessionStateBuilder$$anon$1 -
=== Applying Rule org.apache.spark.sql.catalyst.analysis.TypeCoercion$PromoteStrings ===
!'Project [(0.88 = 0) AS a#0, (0 = 0) AS b#1] Project [(cast(0.88 as int) = 0) AS a#0, (cast(0 as int) = 0) AS b#1]
+- OneRowRelation +- OneRowRelation
我们很容易通过日志找到上述逻辑生效的规则是TypeCoercion$PromoteStrings
第三步快速定位代码
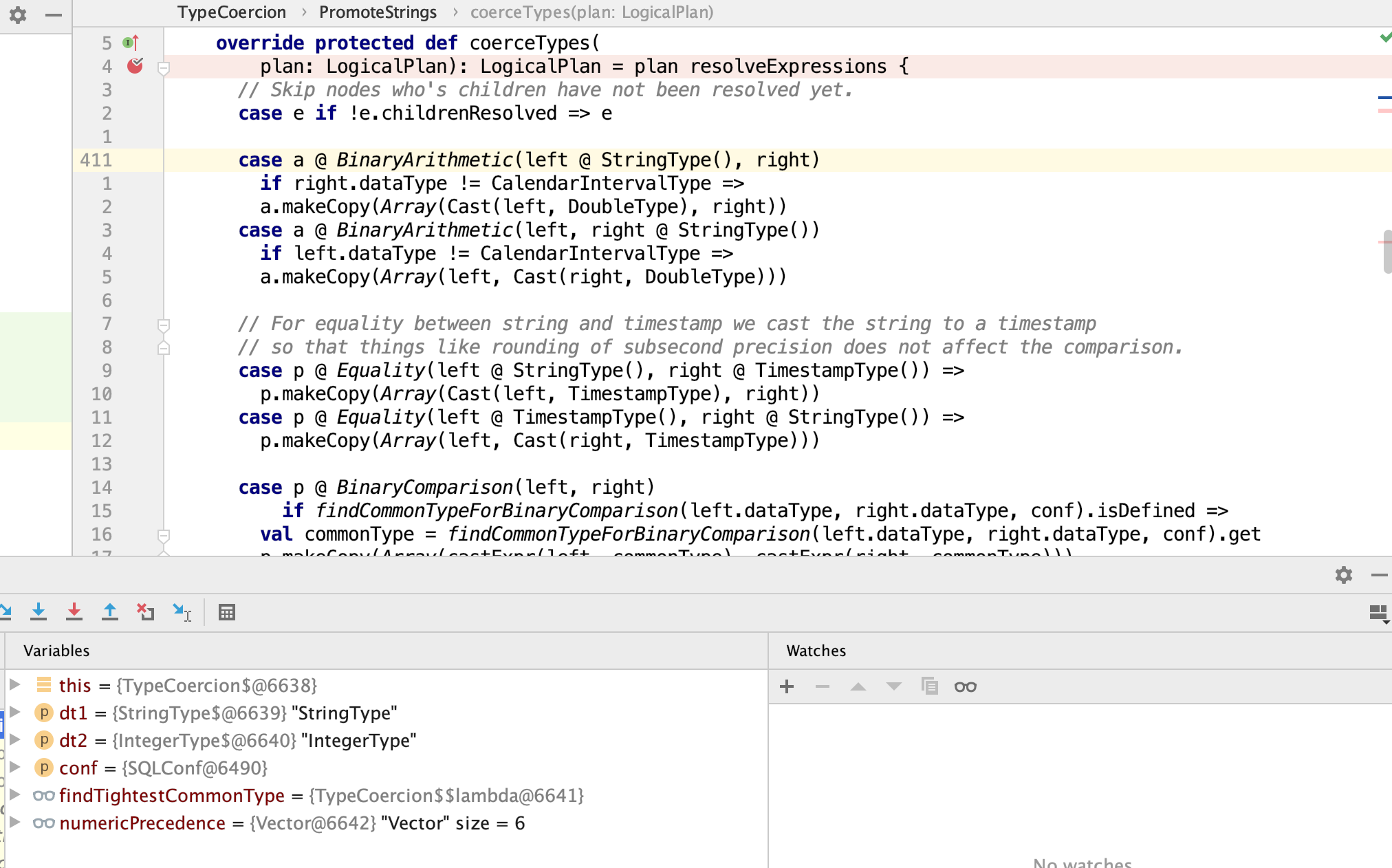
这样我们有的放矢的加上断点,很快就找到相关代码
private def findCommonTypeForBinaryComparison(
dt1: DataType, dt2: DataType, conf: SQLConf): Option[DataType] = (dt1, dt2) match {
// We should cast all relative timestamp/date/string comparison into string comparisons
// This behaves as a user would expect because timestamp strings sort lexicographically.
// i.e. TimeStamp(2013-01-01 00:00 ...) < "2014" = true
case (StringType, DateType) => Some(StringType)
case (DateType, StringType) => Some(StringType)
case (StringType, TimestampType) => Some(StringType)
case (TimestampType, StringType) => Some(StringType)
case (StringType, NullType) => Some(StringType)
case (NullType, StringType) => Some(StringType)
// Cast to TimestampType when we compare DateType with TimestampType
// if conf.compareDateTimestampInTimestamp is true
// i.e. TimeStamp('2017-03-01 00:00:00') eq Date('2017-03-01') = true
case (TimestampType, DateType)
=> if (conf.compareDateTimestampInTimestamp) Some(TimestampType) else Some(StringType)
case (DateType, TimestampType)
=> if (conf.compareDateTimestampInTimestamp) Some(TimestampType) else Some(StringType)
// There is no proper decimal type we can pick,
// using double type is the best we can do.
// See SPARK-22469 for details.
case (n: DecimalType, s: StringType) => Some(DoubleType)
case (s: StringType, n: DecimalType) => Some(DoubleType)
case (l: StringType, r: AtomicType) if r != StringType => Some(r)
case (l: AtomicType, r: StringType) if l != StringType => Some(l)
case (l, r) => None
}
String类型的0.88和Int类型的0为了建立比较关系,所以将string强转到了int,也就出现了我们刚看到的现象了,这就是根本原因所在
第四步有趣的小实验
select "0.88" = 0 a,0.88 = "0" b
我们基于刚才的源码跟踪,将0.88的引号去掉,把0变成string,这样大家都往double转,进行比较之后就得到false了

总结
对于问题分析:
- 先打一个explain确定下计划是否符合预期
- 再利用trace log找到对应规则
- 有的放矢的跟踪源代码
对于一般用户:
- sql尽量严谨,不要依赖这种隐式转换,通过显式的cast在任何版本都不会有问题的,因为这段逻辑在1.6的时候其实是往double转的,但是2.x不是了,所以为了sql的健壮性,最好不要写出骚操作的代码
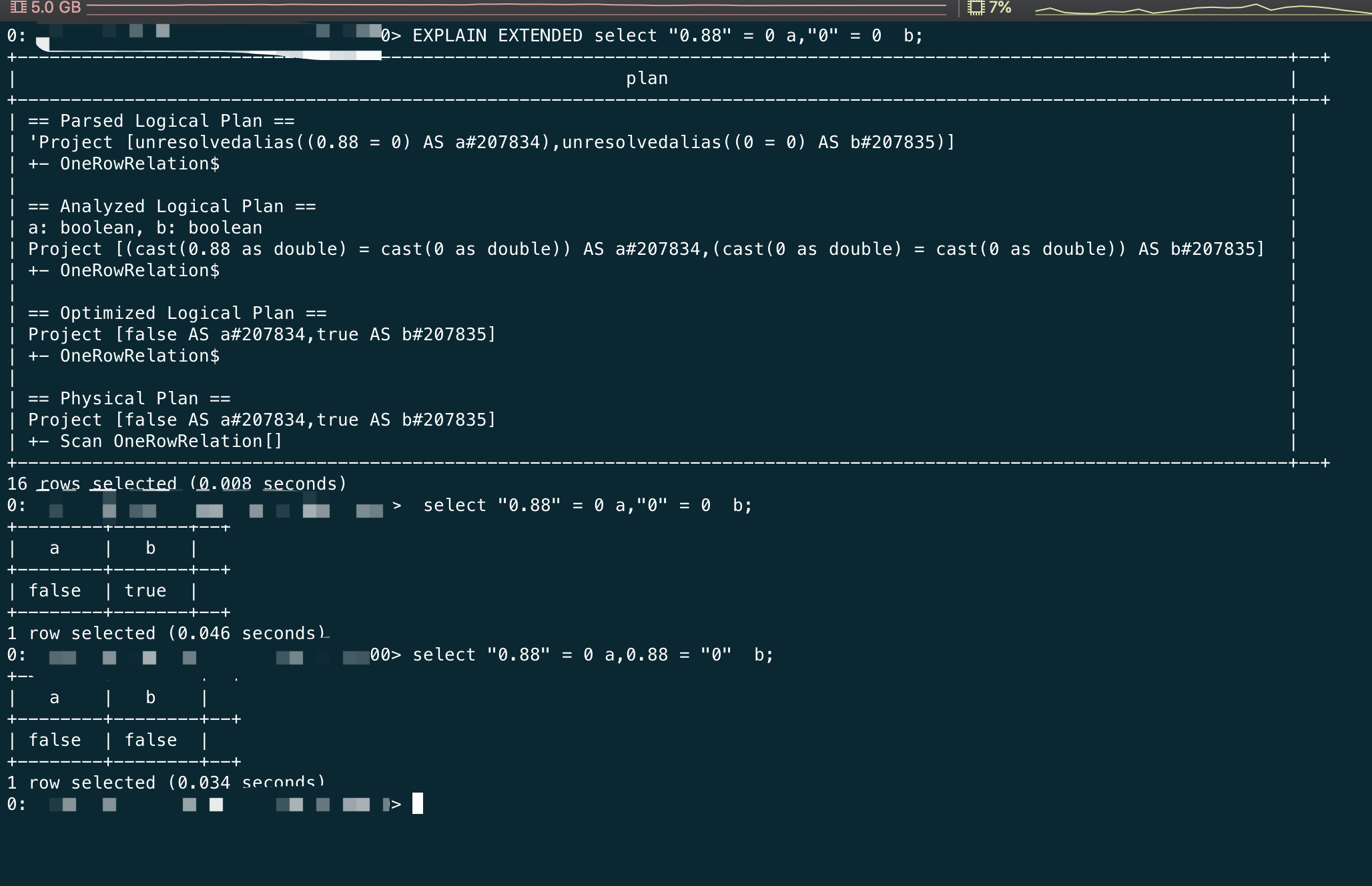
最后附上一个1.6的执行计划和结果
@cjuexuan 如果是计算平台上的用户想测试下自己的UDF每次修改逻辑。这时候也没法重启ThriftServer,可能别的人也在使用平台。所以我是想调度引擎去管理这些UDF,提交Job的时候先执行注册UDF的代码,然后在执行平台用户写的计算逻辑。不知道还有没有更好的解法。所以想和您交流下。
@deadwind4 目前我们reload udf还需要滚动重启app
 @deadwind4 在我司,如果通用udf会由平台维护,如果自定义udf的话,各个组自己维护,然后引擎启动会依赖udf.properties这个文件给udf做注册,所以他们只需要在文件里声明就行了,这些任务会以独立spark application的方式运行
@deadwind4 在我司,如果通用udf会由平台维护,如果自定义udf的话,各个组自己维护,然后引擎启动会依赖udf.properties这个文件给udf做注册,所以他们只需要在文件里声明就行了,这些任务会以独立spark application的方式运行
如果是不通用的各个组维护的自定义UDF。就是每个Spark Job内部自己加载是吧。比如sql('CREATE TEMPORARY FUNCTION xxx ')这种。 这样各个组修改自己的UDF逻辑也没关系,反正下次Job启动逻辑就更新了。和Hive Metastore也无关,也不需要重启ThriftServer。对吧?