chroma
 chroma copied to clipboard
chroma copied to clipboard
[Bug]: RuntimeError: dictionary changed size during iteration when take a load testing on "add" api
What happened?
I take a load testing on chroma server mode with default config. I focus on "/api/v1/collections/test1/add" and "/api/v1/collections/test1/query" api and find the performance of "add" is not good enough. I test the api for 5 minutes the result looks like:
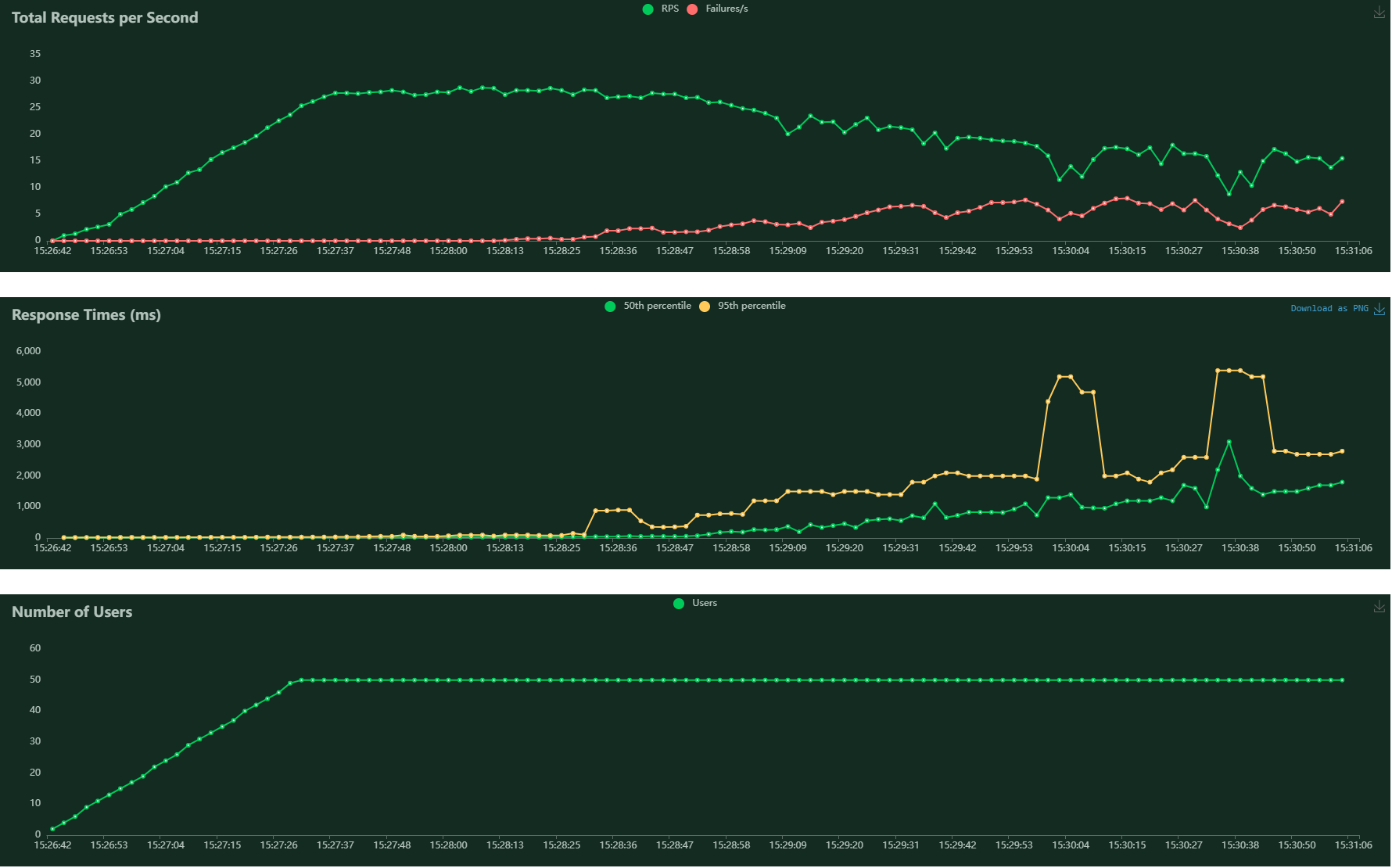 the "query" api is doing well.
the "query" api is doing well.
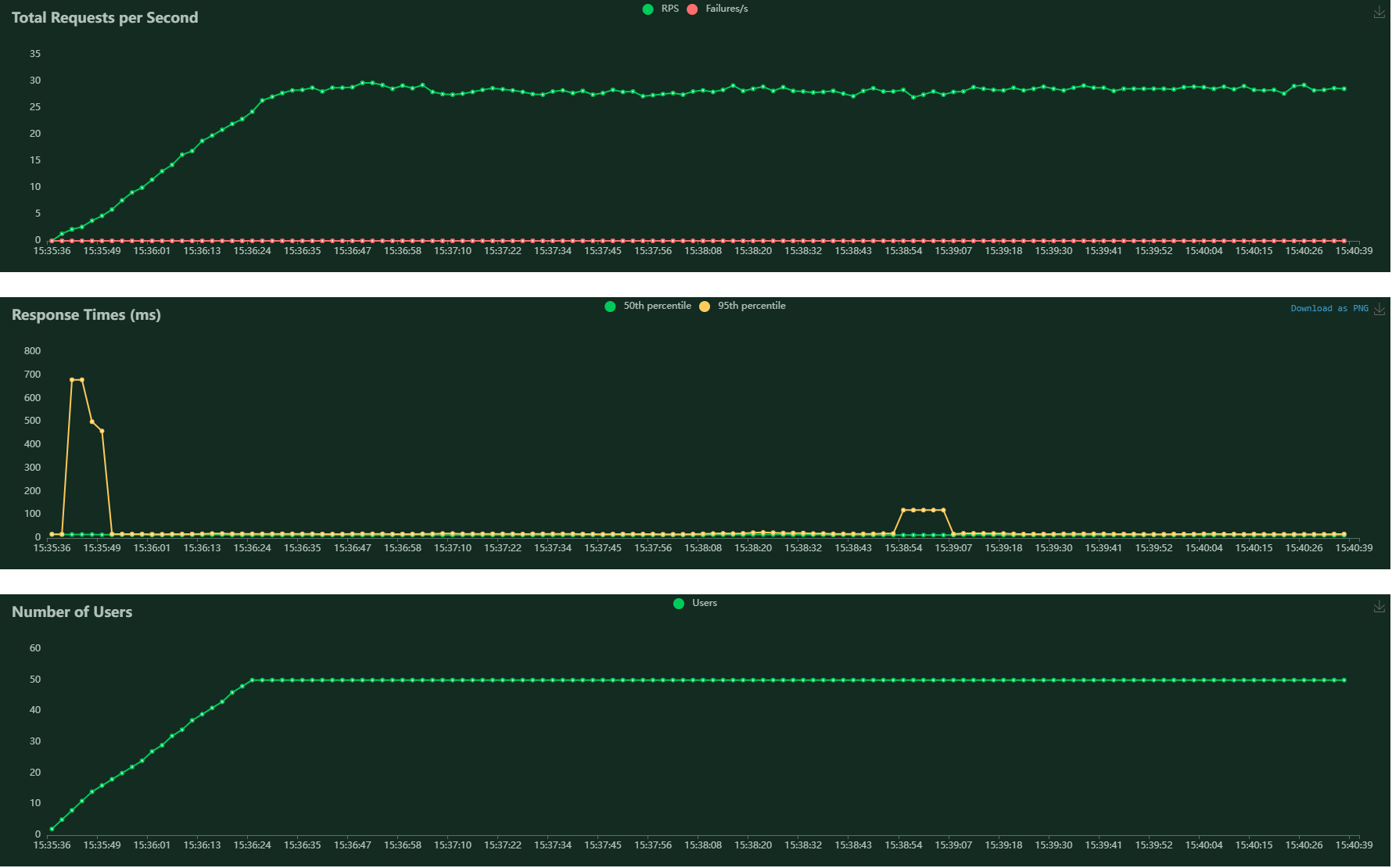 In the chroma.log I find these errors when test the "add" api:
In the chroma.log I find these errors when test the "add" api:
2023-05-05 07:30:16 INFO uvicorn.access 192.168.3.9:60162 - "POST /api/v1/collections/test1/add HTTP/1.1" 500
2023-05-05 07:30:16 DEBUG chromadb.db.index.hnswlib Index saved to .chroma/index/index.bin
2023-05-05 07:30:16 DEBUG chromadb.db.index.hnswlib Index saved to .chroma/index/index.bin
2023-05-05 07:30:16 DEBUG chromadb.db.index.hnswlib Index saved to .chroma/index/index.bin
2023-05-05 07:30:16 ERROR chromadb.server.fastapi dictionary changed size during iteration
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/anyio/streams/memory.py", line 94, in receive
return self.receive_nowait()
File "/usr/local/lib/python3.10/site-packages/anyio/streams/memory.py", line 89, in receive_nowait
raise WouldBlock
anyio.WouldBlock
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/starlette/middleware/base.py", line 43, in call_next
message = await recv_stream.receive()
File "/usr/local/lib/python3.10/site-packages/anyio/streams/memory.py", line 114, in receive
raise EndOfStream
anyio.EndOfStream
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/chroma/./chromadb/server/fastapi/__init__.py", line 47, in catch_exceptions_middleware
return await call_next(request)
File "/usr/local/lib/python3.10/site-packages/starlette/middleware/base.py", line 46, in call_next
raise app_exc
File "/usr/local/lib/python3.10/site-packages/starlette/middleware/base.py", line 36, in coro
await self.app(scope, request.receive, send_stream.send)
File "/usr/local/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 75, in __call__
raise exc
File "/usr/local/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 64, in __call__
await self.app(scope, receive, sender)
File "/usr/local/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 21, in __call__
raise e
File "/usr/local/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 18, in __call__
await self.app(scope, receive, send)
File "/usr/local/lib/python3.10/site-packages/starlette/routing.py", line 680, in __call__
await route.handle(scope, receive, send)
File "/usr/local/lib/python3.10/site-packages/starlette/routing.py", line 275, in handle
await self.app(scope, receive, send)
File "/usr/local/lib/python3.10/site-packages/starlette/routing.py", line 65, in app
response = await func(request)
File "/usr/local/lib/python3.10/site-packages/fastapi/routing.py", line 231, in app
raw_response = await run_endpoint_function(
File "/usr/local/lib/python3.10/site-packages/fastapi/routing.py", line 162, in run_endpoint_function
return await run_in_threadpool(dependant.call, **values)
File "/usr/local/lib/python3.10/site-packages/starlette/concurrency.py", line 41, in run_in_threadpool
return await anyio.to_thread.run_sync(func, *args)
File "/usr/local/lib/python3.10/site-packages/anyio/to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "/usr/local/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "/usr/local/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 867, in run
result = context.run(func, *args)
File "/chroma/./chromadb/server/fastapi/__init__.py", line 162, in add
result = self._api._add(
File "/chroma/./chromadb/api/local.py", line 208, in _add
self._db.add_incremental(collection_uuid, added_uuids, embeddings)
File "/chroma/./chromadb/db/clickhouse.py", line 542, in add_incremental
index.add(uuids, embeddings)
File "/chroma/./chromadb/db/index/hnswlib.py", line 148, in add
self._save()
File "/chroma/./chromadb/db/index/hnswlib.py", line 187, in _save
pickle.dump(self._label_to_id, f, pickle.HIGHEST_PROTOCOL)
RuntimeError: dictionary changed size during iteration
Versions
chorma v0.3.21 python 3.10.6 os centos 7
Relevant log output
No response
Got this one too @rxy1212
@HammadB Do you mean the Chroma server? Does it have this config parameter? Couldn't find it here https://github.com/chroma-core/chroma/blob/main/chromadb/config.py
@HammadB I already set workers=4 in docker-compose.yml and docker_entrypoint.sh but it didn't get better. Please fix this bug, otherwise chroma can't be deployed in product at all.
@adijo I guess @HammadB means we can set workers in docker-compose.yml and docker_entrypoint.sh files.
uvicorn chromadb.app:app --reload --workers 4 --host 0.0.0.0 --port 8000 --log-config log_config.yml
But It does not make things change.
By default the docker-compose sets workers to 1, as chromadb is not thread-safe. Can you try with workers=1. We are working on a refactor to make Chroma threadsafe and production grade.
https://docs.trychroma.com/roadmap
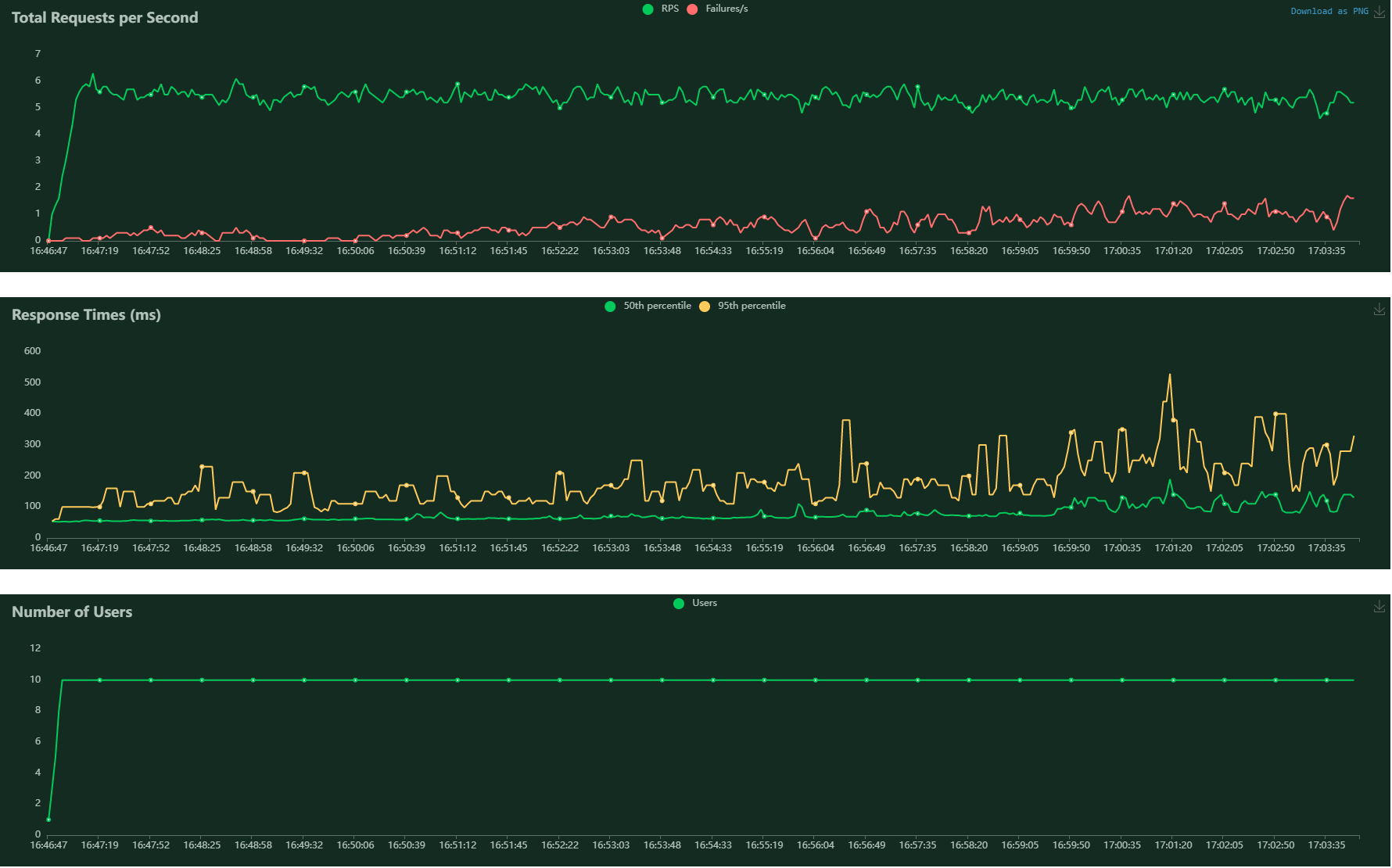
@HammadB I have tried the both settings (workers=1 and workers=4). Unfortunately the concurrency of 'add' api is still too weak. I give 2 load testing result as below.
test1
users: 10 wait_time: between 1s and 2.5s duration: 10 minutes
 we can see the median value of response time increase from 13ms to 30ms
test2
users: 50 wait_time: between 1s and 2.5s duration: 10 minutes
we can see the median value of response time increase from 13ms to 30ms
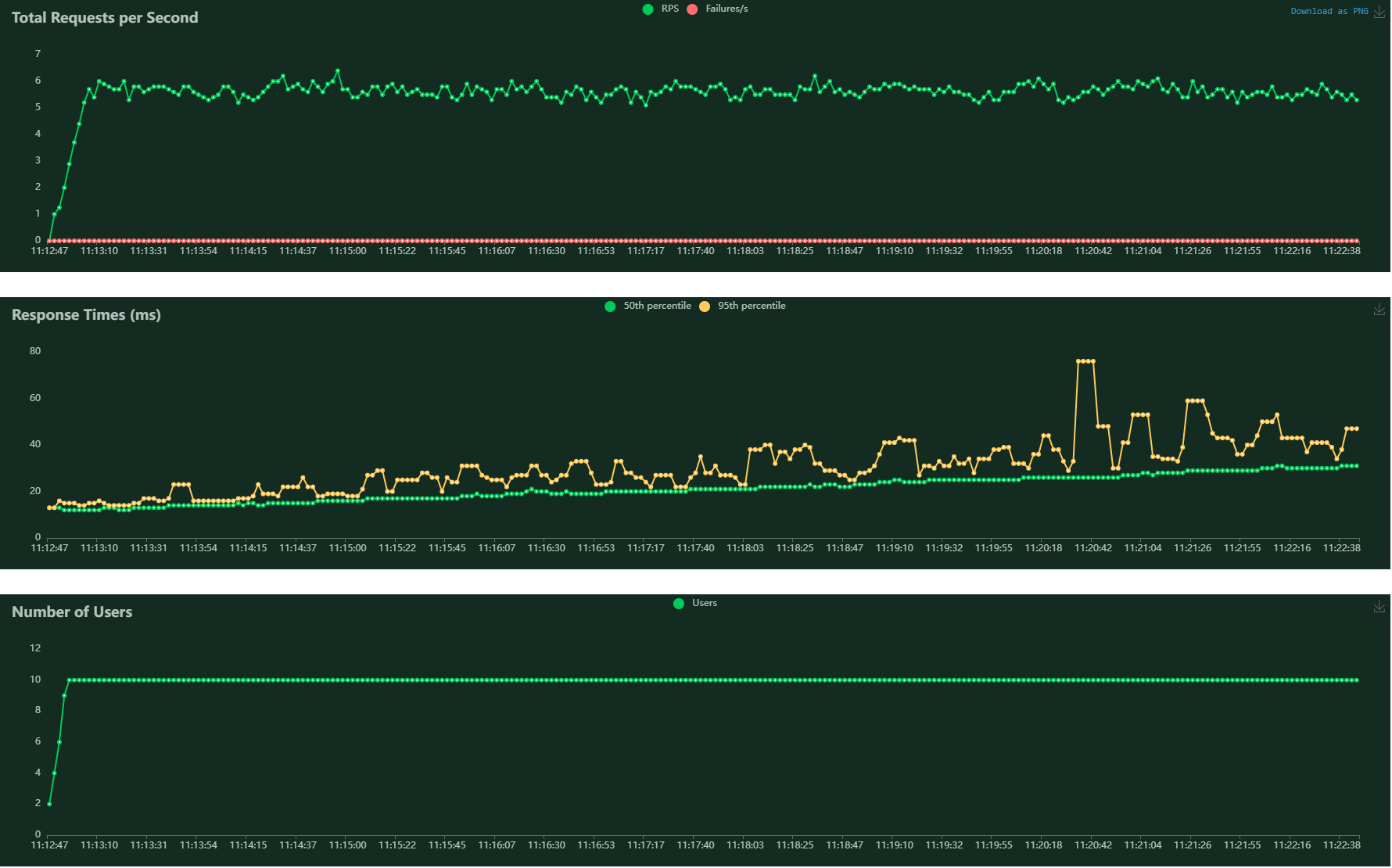
test2
users: 50 wait_time: between 1s and 2.5s duration: 10 minutes
 the server is dead in three minutes
the server is dead in three minutes
@HammadB It there any official bench mark we can reference in client or server mode?
I guess the bottleneck is the hnswlib module. Every time I add vecvtors, it write some files to the disk. .pkl file may be not a good idea in high concurrency scenarios.
'''
chromadb/db/index/hnswlib.py
'''
def _save(self):
# create the directory if it doesn't exist
if not os.path.exists(f"{self._save_folder}"):
os.makedirs(f"{self._save_folder}")
if self._index is None:
return
self._index.save_index(f"{self._save_folder}/index_{self._id}.bin")
# pickle the mappers
# Use old filenames for backwards compatibility
with open(f"{self._save_folder}/id_to_uuid_{self._id}.pkl", "wb") as f:
pickle.dump(self._label_to_id, f, pickle.HIGHEST_PROTOCOL)
with open(f"{self._save_folder}/uuid_to_id_{self._id}.pkl", "wb") as f:
pickle.dump(self._id_to_label, f, pickle.HIGHEST_PROTOCOL)
with open(f"{self._save_folder}/index_metadata_{self._id}.pkl", "wb") as f:
pickle.dump(self._index_metadata, f, pickle.HIGHEST_PROTOCOL)
logger.debug(f"Index saved to {self._save_folder}/index.bin")
As the file gets bigger and bigger the "add" api gets slower and slower. And the errors here are also triggered by this code block.
I take another test to simulate a situation that add a batch of vectors instead of single vector into chroma.
users: 1 batch_size: 50 wait_time: between 1s and 2.5s duration: 10 minutes
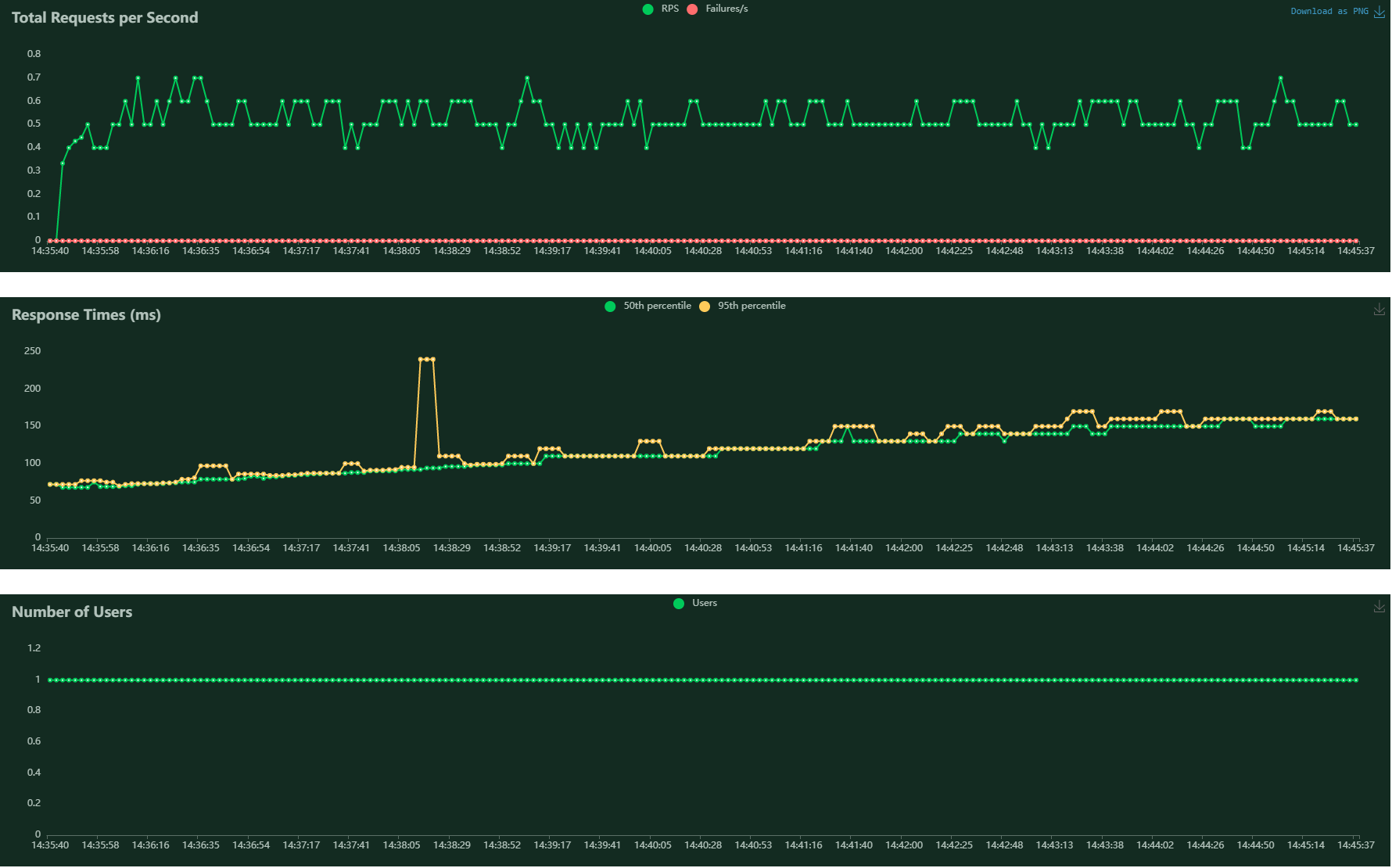 The response time increased from 70ms to 160ms in 10 minutes.
The response time increased from 70ms to 160ms in 10 minutes.
Any update on this? Regularly running into RuntimeError('dictionary changed size during iteration')
I will look into this today. I think there are two things going on:
- chroma is not thread-safe as is chroma is really a single-process db. We are actively working on making it production ready for higher load cases. https://docs.trychroma.com/roadmap
- We don't need to be saving the index every write. This is being tracked through #545
Closing as resolved - thread safety and persistence issues were addressed in v0.4 release.