源码中的2D检测生成的one_hot_vec
你好,我在阅读源码的时候一直都没有找到kitti和sunrgbd数据集的2D检测部分的代码,作者是否将这一步省略了直接提取了原始数据中的2D bounding box作为训练结果? 以及在论文中一直提到一个one hot vec 作为分类向量,在代码中和点云数据一起输入了模型进行训练,请问这个one_hot_vec是怎么获取的呢?我看着论文里是说在2d检测后得到的? 我输出了kitti的中的one hot vec他是一个好像是分为三类(1,0,0)这个样子,1代表属于这一类?那one hot vec 的大小是(n,3)?n是点云数量?那sunrgbd是(n,classnum)? 这个代码看的我满脑子都是疑惑。。。尤其是想把自己的数据标注好丢进去训练,一直没看明白kitti数据集和surgbd数据集中的这么多数据哪些是要用的哪些是不要用的,如果你能不吝赐教将不胜感激。
Fpointnet本来就是一个基于2D目标检测结果,通过对2D检测的框直接做投影获得3D的点云视锥所以他原本2D的检测模块是没有公布的,只公开了他们用的2D检测结果txt,当然他这个结果也有不少问题我们是自己实现一个2D检测结果把所有图跑一边存下来就可以用了。至于one hot vec就是基于label所得到的目标类别,独热编码你可以搜搜看,n*3同时只有1个为1的表示目标属于哪一类,用来做最后回归,n应该是目标数量记不清了
------------------ 原始邮件 ------------------ 发件人: "chonepieceyb/reading-frustum-pointnets-code" <[email protected]>; 发送时间: 2020年9月22日(星期二) 下午3:54 收件人: "chonepieceyb/reading-frustum-pointnets-code"<[email protected]>; 抄送: "Subscribed"<[email protected]>; 主题: [chonepieceyb/reading-frustum-pointnets-code] 源码中的2D检测生成的one_hot_vec (#4)
你好,我在阅读源码的时候一直都没有找到kitti和sunrgbd数据集的2D检测部分的代码,作者是否将这一步省略了直接提取了原始数据中的2D bounding box作为训练结果? 以及在论文中一直提到一个one hot vec 作为分类向量,在代码中和点云数据一起输入了模型进行训练,请问这个one_hot_vec是怎么获取的呢?我看着论文里是说在2d检测后得到的? 我输出了kitti的中的one hot vec他是一个好像是分为三类(1,0,0)这个样子,1代表属于这一类?那one hot vec 的大小是(n,3)?n是点云数量?那sunrgbd是(n,classnum)? 这个代码看的我满脑子都是疑惑。。。尤其是想把自己的数据标注好丢进去训练,一直没看明白kitti数据集和surgbd数据集中的这么多数据哪些是要用的哪些是不要用的,如果你能不吝赐教将不胜感激。
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub, or unsubscribe.
感谢回答!他们2D目标检测结果txt是在kitti\rgb_detections两个txt文件中吗? 因为是我自己的点云和图像数据,所以像这样的2d检测结果我可以自己用labelme之类的工具生成吗? label生成json文件,也是一个长方形, 如下所示: "label": "cloud", "points": [ [ 76.59459459459458, 64.94594594594594 ], [ 707.9459459459459, 419.0 ] ],然后根据这个生成2dboundingbox=xmin,ymin,xmax,ymax 我看了prepare_data这一部分的代码,demo( )中的3dbounddingbox似乎是从label文件中直接提取的长宽高经过compute_box_3D生成了8个顶点坐标? 那他自己生成3Dbound ingboxd 代码是在extract_frustum_data()中获取的吗? 在extract_frustum_data()中objects也就是对应label文件中的每个被标注对像的标注信息,那它的2dbox的xmin,ymin,xmax,ymax和3dbox的长宽高说到底还是从标注信息里面获取的? 即: 1、objects = dataset.get_label_objects(data_idx) #从label文件生成object 2、box2d = objects[obj_idx].box2d #2dbox生成 3、box3d_pts_2d, box3d_pts_3d = utils.compute_box_3d(obj, calib.P) #生成3dbox 难道2d和3dbox都是从标注文件中获取吗?模型只是做了一个3dboundingbox里面包含的点云的实例分割? 只有extract_frustum_data_rgb_detection()才用到了一个kitti\rgb_detections的txt文件,也只是生成了一个验证集的frustum_carpedcyc_val_rgb_detection.pickle文件。 然而在模型训练的时候调用的也直接是由标注文件生成的train.pickle文件? 我现在就很迷茫,如果用的都是kitti数据集已经标注好了的信息去框点云,再把框出来的点云丢到模型里面去训练,那这个网络训练的误差岂不是很低?
sry最近有点忙,Fpointnet本来就是对2D检测的结果框进行3D投影得到点云的视锥,然后对点云的视锥直接进行学习。你可以好好看下prepare_data里,先跑prepare_data然后把所有2d label做一些预处理坐标转换等存在pickle文件里,然后整个模型都是读取pickle文件,至于你说的生成3dbox,这个就是最后和模型输出的3dbox做损失的label,而通过2d box进行视锥投影得到的点云视锥里其实还有很多不在3d box里的点云,所以我还不是很清楚你的问题是什么,欢迎交流反正
------------------ 原始邮件 ------------------ 发件人: "chonepieceyb/reading-frustum-pointnets-code" <[email protected]>; 发送时间: 2020年9月23日(星期三) 中午11:33 收件人: "chonepieceyb/reading-frustum-pointnets-code"<[email protected]>; 抄送: "鹏霖"<[email protected]>;"Comment"<[email protected]>; 主题: Re: [chonepieceyb/reading-frustum-pointnets-code] 源码中的2D检测生成的one_hot_vec (#4)
感谢回答!他们2D目标检测结果txt是在kitti\rgb_detections两个txt文件中吗? 因为是我自己的点云和图像数据,所以像这样的2d检测结果我可以自己用labelme之类的工具生成吗? label生成json文件,也是一个长方形, 如下所示: "label": "cloud", "points": [ [ 76.59459459459458, 64.94594594594594 ], [ 707.9459459459459, 419.0 ] ],然后根据这个生成2dboundingbox=xmin,ymin,xmax,ymax 我看了prepare_data这一部分的代码,demo( )中的3dbounddingbox似乎是从label文件中直接提取的长宽高经过compute_box_3D生成了8个顶点坐标? 那他自己生成3Dbound ingboxd 代码是在extract_frustum_data()中获取的吗? 在extract_frustum_data()中objects也就是对应label文件中的每个被标注对像的标注信息,那它的2dbox的xmin,ymin,xmax,ymax和3dbox的长宽高说到底还是从标注信息里面获取的? 即: 1、objects = dataset.get_label_objects(data_idx) #从label文件生成object 2、box2d = objects[obj_idx].box2d #2dbox生成 3、box3d_pts_2d, box3d_pts_3d = utils.compute_box_3d(obj, calib.P) #生成3dbox 难道2d和3dbox都是从标注文件中获取吗?模型只是做了一个3dboundingbox里面包含的点云的实例分割? 只有extract_frustum_data_rgb_detection()才用到了一个kitti\rgb_detections的txt文件,也只是生成了一个验证集的frustum_carpedcyc_val_rgb_detection.pickle文件。 然而在模型训练的时候调用的也直接是由标注文件生成的train.pickle文件? 我现在就很迷茫,如果用的都是kitti数据集已经标注好了的信息去框点云,再把框出来的点云丢到模型里面去训练,那这个网络训练的误差岂不是很低?
— You are receiving this because you commented. Reply to this email directly, view it on GitHub, or unsubscribe.
谢谢你再一次的回答!我之前一直没弄明白2d和3dboundingbox这一块的代码,看完prepare_data总觉得作者是直接从label文件里提取2dboundingbox的四个点和3dboundingbox的长宽高去算这俩boundingbox,完了之后又要用label里的数据去和这俩去算误差,我就一直想这样算误差不得等于0吗?后来发现原来是因为他没有把2D检测的代码公布出来,所以使用的是label的文件。现在我准备用yolo去做2D检测器,但是问题是yolo做2D检测器了也只是生成了一个2dbox的xmin,ymin,xmax,ymax,而我看了prepare_data中生成3Dboundingbox的部分也有用到label中的3D长宽高的信息,那么在不使用label文件的情况下3Dbox要怎么计算呢?
而且作者用的kitti数据集有4个相机,我只有一个相机,只能获得一个内参和外参数据,这是我的相机参数信息:
color_intrin
[ 640x480 p[317.606 237.686] f[617.01 617.055] Inverse Brown Conrady [0 0 0 0 0] ]
depth_intrinsics
[ 640x480 p[324.468 242.84] f[384.633 384.633] Brown Conrady [0 0 0 0 0] ]
depth_extrinsics
rotation: [0.999946, 0.000695059, -0.010396, -0.000717043, 0.999997, -0.00211104, 0.0103945, 0.00211838, 0.999944]
translation: [0.0148265, 3.82519e-05, -2.88962e-05]
根据您在代码提供的链接我去看了kitti各个相机间的转换关系即
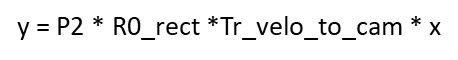 ,其中Tr_velo_cam和R0_rect这俩矩阵我没有,就算撇去了R0_rect这个矩阵,我也没有另一个矩阵,我要去哪里获得这个矩阵呢?
期待您的回答,非常感谢!
,其中Tr_velo_cam和R0_rect这俩矩阵我没有,就算撇去了R0_rect这个矩阵,我也没有另一个矩阵,我要去哪里获得这个矩阵呢?
期待您的回答,非常感谢!
他公开的源码中label中的2d信息是他自己用了一个检测器之后跑出来的反正,至于数据预处理那块是我之前另一个组员负责的我不是很清楚,但是大概率是激光雷达数据中自带的转换坐标系矩阵,具体的你可以好好看下kitti数据集下velodyne里面详细的数据格式
------------------ 原始邮件 ------------------ 发件人: "chonepieceyb/reading-frustum-pointnets-code" <[email protected]>; 发送时间: 2020年9月28日(星期一) 中午1:59 收件人: "chonepieceyb/reading-frustum-pointnets-code"<[email protected]>; 抄送: "鹏霖"<[email protected]>;"Comment"<[email protected]>; 主题: Re: [chonepieceyb/reading-frustum-pointnets-code] 源码中的2D检测生成的one_hot_vec (#4)
谢谢你再一次的回答!我之前一直没弄明白2d和3dboundingbox这一块的代码,看完prepare_data总觉得作者是直接从label文件里提取2dboundingbox的四个点和3dboundingbox的长宽高去算这俩boundingbox,完了之后又要用label里的数据去和这俩去算误差,我就一直想这样算误差不得等于0吗?后来发现原来是因为他没有把2D检测的代码公布出来,所以使用的是label的文件。现在我准备用yolo去做2D检测器,但是问题是yolo做2D检测器了也只是生成了一个2dbox的xmin,ymin,xmax,ymax,而我看了prepare_data中生成3Dboundingbox的部分也有用到label中的3D长宽高的信息,那么在不使用label文件的情况下3Dbox要怎么计算呢? 而且作者用的kitti数据集有4个相机,我只有一个相机,只能获得一个内参和外参数据,这是我的相机参数信息: color_intrin [ 640x480 p[317.606 237.686] f[617.01 617.055] Inverse Brown Conrady [0 0 0 0 0] ] depth_intrinsics [ 640x480 p[324.468 242.84] f[384.633 384.633] Brown Conrady [0 0 0 0 0] ] depth_extrinsics rotation: [0.999946, 0.000695059, -0.010396, -0.000717043, 0.999997, -0.00211104, 0.0103945, 0.00211838, 0.999944] translation: [0.0148265, 3.82519e-05, -2.88962e-05] 根据您在代码提供的链接我去看了kitti各个相机间的转换关系即
,其中Tr_velo_cam和R0_rect这俩矩阵我没有,就算撇去了R0_rect这个矩阵,我也没有另一个矩阵,我要去哪里获得这个矩阵呢? 期待您的回答,非常感谢!
— You are receiving this because you commented. Reply to this email directly, view it on GitHub, or unsubscribe.
谢谢你的回答!我决定再看看sunrgbd的代码找一下2d和3d之间的关系,因为我的相机没有激光雷达,就也估计不会有这些矩阵,感觉还是sunrgbd比较贴近我的数据集一些。但是还想问一下, 你们在跑的时候需要在点云数据上进行boundingbox的标注吗?如果标注了需要用什么工具吗?我之前一直在找一个合适的工具来标注点云,很少有工具能输出boundingbox。标注了之后的误差是如何计算的呢?
没有激光雷达的话这个网路就对你没什么帮助了....fpointnet主要的操作都是对激光雷达的点云数据做的,至于标注有一个VGG Image Annotator的,手动标注这个误差就很大了反正,标注得好坏直接决定网络效果,我们就是直接用的kitti公开的点云label,建议你先好好看一下kitti数据集所提供的所有label信息
------------------ 原始邮件 ------------------ 发件人: "chonepieceyb/reading-frustum-pointnets-code" <[email protected]>; 发送时间: 2020年9月29日(星期二) 晚上7:19 收件人: "chonepieceyb/reading-frustum-pointnets-code"<[email protected]>; 抄送: "鹏霖"<[email protected]>;"Comment"<[email protected]>; 主题: Re: [chonepieceyb/reading-frustum-pointnets-code] 源码中的2D检测生成的one_hot_vec (#4)
谢谢你的回答!我决定再看看sunrgbd的代码找一下2d和3d之间的关系,因为我的相机没有激光雷达,就也估计不会有这些矩阵,感觉还是sunrgbd比较贴近我的数据集一些。但是还想问一下, 你们在跑的时候需要在点云数据上进行boundingbox的标注吗?如果标注了需要用什么工具吗?我之前一直在找一个合适的工具来标注点云,很少有工具能输出boundingbox。标注了之后的误差是如何计算的呢?
— You are receiving this because you commented. Reply to this email directly, view it on GitHub, or unsubscribe.
谢谢回复!我之前也看了很久kitti的数据格式,calib,点云,图像还有label。主要是我要把自己的数据塞进网络,就得想办法把标注打的和kiiti数据集一样,所以卡在数据标注和坐标转换上好久了。不过好在作者有提供sunrgbd的训练方式,它的数据采集和我的相机很相近,都用到了realsense相机,相机的内参和外参矩阵一样,点云生成公式也是一样的,所以决定参考sunrgbd的数据处理,但是用到sunrgbd的人很少,网上实在是找不到什么参考教程,只能一边结合kitti找这两个数据集预处理的共同之处,一边又慢慢的捋清网络的工作流程在代码上进行修改。我准备去试一试这个vgg Image annotator了,只是如果手动标注误差很大的话,要直接用sunrgbd数据集的label训练,训练出来的模型能用来测试我自己的点云吗?(我也许可以一边训练sunrgbd一边训练我自己的点云,但是我的实力和时间都不允许orz)
不好意思这么久又来打扰你了orz,就是我在测试kitti数据集的时候,将command_test_v1中的命令直接拿出来放在pycharm的终端里面运行了(因为是windows下面运行的)
命令行内容:
python train/test.py --gpu 0 --num_point 1024 --model frustum_pointnets_v1 --model_path train/log_v1/model.ckpt --output train/detection_results_v1 --data_path kitti/frustum_carpedcyc_val_rgb_detection.pickle --from_rgb_detection --idx_path kitti/image_sets/val.txt --from_rgb_detection
train/kitti_eval/evaluate_object_3d_offline dataset/KITTI/object/training/label_2/ train/detection_results_v1
但他一直报错
2020-10-19 17:26:43.938055: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll WARNING:tensorflow:From C:\Users\ouyang\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\compat\v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term usage: test.py [-h] [--gpu GPU] [--num_point NUM_POINT] [--model MODEL] [--model_path MODEL_PATH] [--batch_size BATCH_SIZE] [--output OUTPUT] [--data_path DATA_PATH] [--from_rgb_detection] [--idx_path IDX_PATH] [--dump_result] test.py: error: unrecognized arguments: train/kitti_eval/evaluate_object_3d_offline dataset/KITTI/object/training/label_2/ train/detection_results_v1
就是命令行中最后三项不在test.py的定义内,我去掉了这三项,最后成功运行,确实出现了train/detection_results_v1,其中也有test集的检测结果。想知道您最后测试的情况是怎么样的?
test.py是那你训练好的模型跑一边测试集然后把测试结果写成txt存在哪个路径下,具体想看你可以自己写一个可视化脚本读取生成的txt然后在对应的图片点云里画出来
------------------ 原始邮件 ------------------ 发件人: "chonepieceyb/reading-frustum-pointnets-code" <[email protected]>; 发送时间: 2020年10月20日(星期二) 上午9:14 收件人: "chonepieceyb/reading-frustum-pointnets-code"<[email protected]>; 抄送: "鹏霖"<[email protected]>;"Comment"<[email protected]>; 主题: Re: [chonepieceyb/reading-frustum-pointnets-code] 源码中的2D检测生成的one_hot_vec (#4)
不好意思这么久又来打扰你了orz,就是我在测试kitti数据集的时候,将command_test_v1中的命令直接拿出来放在pycharm的终端里面运行了(因为是windows下面运行的) 命令行内容: python train/test.py --gpu 0 --num_point 1024 --model frustum_pointnets_v1 --model_path train/log_v1/model.ckpt --output train/detection_results_v1 --data_path kitti/frustum_carpedcyc_val_rgb_detection.pickle --from_rgb_detection --idx_path kitti/image_sets/val.txt --from_rgb_detection train/kitti_eval/evaluate_object_3d_offline dataset/KITTI/object/training/label_2/ train/detection_results_v1 但他一直报错 2020-10-19 17:26:43.938055: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll WARNING:tensorflow:From C:\Users\ouyang\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\compat\v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term usage: test.py [-h] [--gpu GPU] [--num_point NUM_POINT] [--model MODEL] [--model_path MODEL_PATH] [--batch_size BATCH_SIZE] [--output OUTPUT] [--data_path DATA_PATH] [--from_rgb_detection] [--idx_path IDX_PATH] [--dump_result] test.py: error: unrecognized arguments: train/kitti_eval/evaluate_object_3d_offline dataset/KITTI/object/training/label_2/ train/detection_results_v1 就是命令行中最后三项不在test.py的定义内,我去掉了这三项,最后成功运行,确实出现了train/detection_results_v1,其中也有test集的检测结果。想知道您最后测试的情况是怎么样的?
— You are receiving this because you commented. Reply to this email directly, view it on GitHub, or unsubscribe.