FedSim
 FedSim copied to clipboard
FedSim copied to clipboard
Similarity Guided Model Aggregation for Federated Learning
FedSim
Similarity Guided Model Aggregation for Federated Learning
This work is published at the Neurocomputing Journal FedSim: Similarity guided model aggregation for Federated Learning
Bibtext
@article{palihawadana2021fedsim,
title={FedSim: Similarity guided model aggregation for Federated Learning},
author={Palihawadana, Chamath and Wiratunga, Nirmalie and Wijekoon, Anjana and Kalutarage, Harsha},
journal={Neurocomputing},
year={2021},
publisher={Elsevier}
}
Usage
bash run_fedsim.sh DATASET_NAME DROP_PERC NUM_CLUSTERS NUM_CLIENTS Run_Name
bash run_fedsim.sh mnist 0 9 20 mnist_run
FedSim algorithm implementation is available in flearn/trainers/fedsim.py.
Reproduce results
The experiments performed on all the datasets were carried out with 35 random seeds (from 0 to 34 incremented by 1) to empirically demonstrate the significance. Repetition of the same experiment with different random seeds helps to reduce the sampling error of our experiments.
For a single dataset, run rounds of FedSim, FedAvg and FedProx where each run will generate a single folder in the logs folder, as a reference we have added a sample log folder with the results in logs/sample/
Used hyper parameters for the experiments are presented in Table 2.
Once the experiments are completed, create the summary log files with the 3 methods as in results/ folder. We have added our results in here which can help to refer and use FedSim.
-
Figure 3 - Results on real datasets -
plot_fedsim_main.py -
Figure 5 - Accuracy improvements of FedSim -
plot_fedsim_improvements.py -
Figure 6 - Results on synthetic datasets -
plot_fedsim_main.pychange line #123 toif(True) -
Figure 7 - Results on other learning models -
plot_fedsim_other.py
Experiment setup
We have adapted the experiment setup from FedProx and Leaf Benchmark work. Thanks for the support by Tian Li.
Dataset generation
For all datasets, see the README files in separate data/$dataset folders for instructions on preprocessing and/or sampling data.
For further clarifications follow the guides on FedProx and Leaf
The two datasets produced with this work is published with the generation source code.
Downloading dependencies
pip3 install -r requirements.txt
Run FedSim Experiments
bash run_fedsim.sh DATASET_NAME 0 NUM_CLUSTERS NUM_CLIENTS Run_Name
bash run_fedavg.sh mnist 0 9 20 mnist_run
or direcly use the python command
python3 -u main.py --dataset='goodreads' --optimizer='fedsim' --learning_rate=0.0001
--num_rounds=250 --clients_per_round=20 --eval_every=1 --batch_size=10 --num_epochs=10
--model='rnn' --drop_percent=0 --num_groups=11 --ex_name=goodreads_rnn_0 --seed=0
When running on GPU specify the id and then run the experiments
export CUDA_VISIBLE_DEVICES=GPU_ID
Results
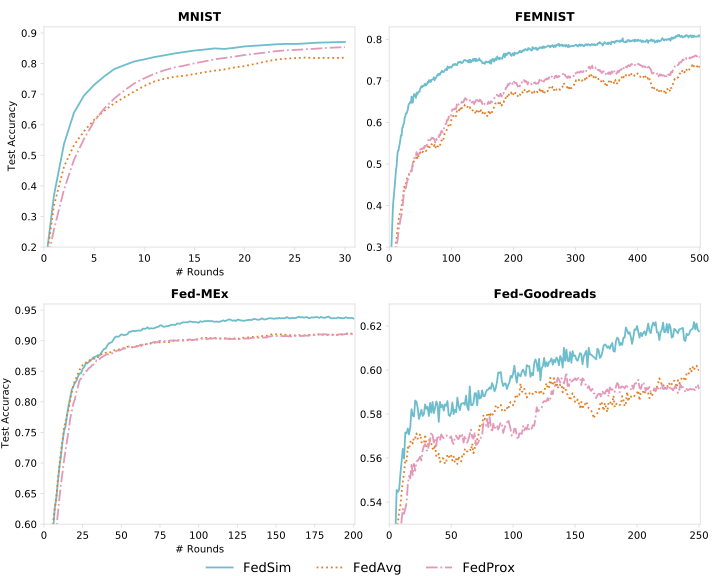
Figure 3: Comparison of performances over communication rounds with real-world datasets

Figure 5: Accuracy improvements of FedSim compared to FedAvg and FedProx of experiments in Figure 3. Values below zero indicate negative performance against a baseline and grey vertical lines denote areas of no statistical significance
Metadata
Owner
Metadata
Similarity Guided Model Aggregation for Federated Learning