ChakraCore
 ChakraCore copied to clipboard
ChakraCore copied to clipboard
for-of 10x slower with Math functions
When Math functions are involved in a large number of iterations (> 10000), for-of loop is about 10 times slower in master (x86 release build) then in the last released version.
const arr = [...Array(10000).keys()];
for (const item of arr) {
const a = Math.round(item/3);
}
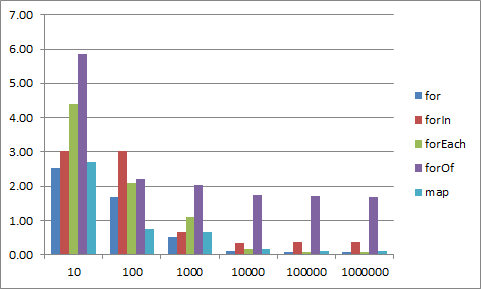
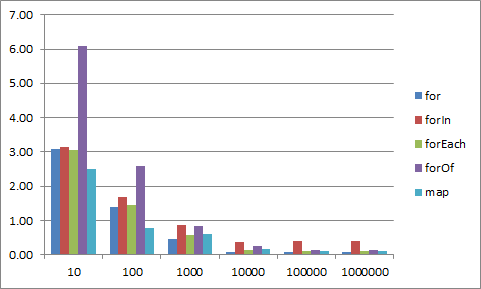
ChakraCore.dll compiled with VS 2019, x86 release build.
Tested on AMD Ryzen 3rd and Intel Core 5th gen. CPUs, Windows 10 x64 OS, x86 host application (not written in C/C++).
complete test:
const arr = [...Array(100000).keys()]
let fn = (item) => Math.round(item/3);
// warm up
for (let i = 0; i < arr.length; i++) {
let a = fn(arr[i]);
};
// console provided by the host app and use high resolution timers
console.time('for');
for (let i = 0; i < arr.length; i++) {
let a = fn(arr[i]);
};
console.timeEnd('for');
console.time('forIn');
for (const key in arr) {
let a = fn(arr[key]);
}
console.timeEnd('forIn');
console.time('forEach');
arr.forEach(item => {
let a = fn(item);
});
console.timeEnd('forEach');
console.time('forOf');
for (const item of arr) {
let a = fn(item);
}
console.timeEnd('forOf');
console.time('map');
let x = arr.map(item => fn(item));
console.timeEnd('map');
Investigated this a little, it seems to stem from here: https://github.com/chakra-core/ChakraCore/pull/6583
And specifically the slow down occurs if both the array prototype and math object builtins are loaded, what I can't work out yet is why that would happen.
Hmm - checked a bit further, the slow down occurs if the Math object or Object constructor builtins are loaded AFTER the Array prototype builtins.
There shouldn't be any effect on performance from this loading order but there is - there must be some kind of unintended interaction OR something needed for optimisation being overwritten by the second load.
The reason why the builtins are relevant to for...of performance is that for...of uses the Array's iterator method which is defined in the Array_prototype builtins file.
EDIT: the below analysis is wrong Found what's going wrong - sort of; on line 12822 of Lower.cpp there is a function that inserts a pre-call BailOut for inlined builtIns to check if the "builtIn" is actually a builtin and bail out if it's not.
In the case of JsBuiltIns the check it inserts only returns true for the last loaded file of builtIns - so if we load the Array prototype and then the math object afterwards, any inlined array prototype builtins will bailout when called - as one such is used on every iteration of a jitted for...of loop you get a bailout per iteration......
I can't currently work out how the check works - though hopefully it will be a simple fix when understood.