Study-Notes
 Study-Notes copied to clipboard
Study-Notes copied to clipboard
Python基础入门系列
Python 基础入门总结,计划内容如下:
主要参考:
- 《Python 编程从入门到实践》
- everything-about-python-from-beginner-to-advance-level
- Python 基础教程
- Anaconda介绍、安装及使用教程
- 最详尽使用指南:超快上手Jupyter Notebook
- 喏,你们要的 PyCharm 快速上手指南
- 一天快速入门python
- 廖雪峰老师的教程
- 超易懂的Python入门级教程,赶紧收藏!
- Python3 函数 | 菜鸟教程
- 超易懂的Python入门级教程(下),绝对干货!
1. 简介和环境配置
1.1 简介
Python 是由 Guido van Rossum 在八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的。目前是最常用也是最热门的一门编程语言之一,应用非常广泛。
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
优点:
- Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
- Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
- Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
- **Python 是初学者的语言:**Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
缺点:
- 运行速度比
C++、C#、Java慢。这是缺乏即时优化器; - 空格缩减的句法限制会给初学者制造一些困难;
- 没有提供如同
R语言的先进的统计产品; - 不适合在低级系统和硬件上开发
1.2 环境搭建
Python 下载
Python 官网可以查看最新的源码、入门教程、文档,以及和 Python 相关的新闻资讯,链接如下:
https://www.python.org/
官方文档下载地址:
https://www.python.org/doc/
Python 安装
Python 在多个平台上都可以使用,不同的平台有不同的安装方式,下面是不同平台上安装的方法:
**Unix & Linux 平台安装 Python **
在 Unix & Linux 平台安装 Python 的简单步骤如下:
- 打开 WEB 浏览器访问 https://www.python.org/downloads/source/
- 选择适用于
Unix/Linux的源码压缩包。 - 下载及解压压缩包。
- 如果你需要自定义一些选项修改
Modules/Setup - 执行 ./configure 脚本
-
make -
make install
执行完上述步骤后,Python 会安装在 /usr/local/bin 目录中,Python 库安装在 /usr/local/lib/pythonXX,XX 为你使用的 Python 的版本号。
Window 平台安装 Python
安装步骤如下:
- 打开 WEB 浏览器访问 https://www.python.org/downloads/windows/
- 在下载列表中选择Window平台安装包,包格式为:
python-XYZ.msi文件 , XYZ 为你要安装的版本号。 - 要使用安装程序
python-XYZ.msi, Windows 系统必须支持Microsoft Installer 2.0搭配使用。只要保存安装文件到本地计算机,然后运行它,看看你的机器支持 MSI。Windows XP 和更高版本已经有 MSI,很多老机器也可以安装 MSI。 - 下载后,双击下载包,进入 Python 安装向导,安装非常简单,你只需要使用默认的设置一直点击"下一步"直到安装完成即可。
MAC 平台安装 Python
MAC 系统一般都自带有 Python2.x版本 的环境,你也可以在链接 https://www.python.org/downloads/mac-osx/ 上下载最新版安装。
环境变量配置
环境变量是由操作系统维护的一个命名的字符串,这些变量包含可用的命令行解释器和其他程序的信息。path(路径)存储在环境变量中。
Unix 或 Windows 中路径变量为PATH(UNIX 区分大小写,Windows 不区分大小写)。
在 Mac OS 中,安装程序过程中改变了 python 的安装路径。如果你需要在其他目录引用Python,你必须在 path 中添加 Python 目录。
Unix/Linux 设置环境变量
有以下三种方法:
-
在
csh shell中输入:
setenv PATH "$PATH:/usr/local/bin/python"
- 在 bash shell (Linux)输入:
export PATH="$PATH:/usr/local/bin/python"
- 在 sh 或者 ksh shell: 输入
PATH="$PATH:/usr/local/bin/python"
注意: ·/usr/local/bin/python· 是 Python 的安装目录。
Window 设置环境变量
两种方法设置环境变量。
第一种是在命令提示框中(cmd) : 输入
path=%path%;C:\Python
注意: C:\Python 是Python的安装目录。
也可以通过以下方式设置:
- 右键点击"计算机",然后点击"属性"
- 然后点击"高级系统设置"
- 选择"系统变量"窗口下面的 "Path",双击即可!
- 然后在 "Path" 行,添加 python 安装路径即可,所以在后面,添加该路径即可。 ps:记住,路径直接用分号";"隔开!
- 最后设置成功以后,在
cmd命令行,输入命令"python",就可以有相关显示。
Anaconda 安装
目前 Python 有两个版本,Python 2 和 Python 3,并且两个版本还有比较大的差异,所以推荐使用 Anaconda 库来管理不同的环境。
官网地址:
https://www.anaconda.com/
以下安装步骤参考 Anaconda介绍、安装及使用教程
1.Linux 安装
1.前往官方下载页面下载。有两个版本可供选择:Python 3.6 和 Python 2.7。
- 启动终端,在终端中输入命令 *md5sum /path/filename* 或 *sha256sum /path/filename*
- 注意:将该步骤命令中的 */path/filename* 替换为文件的实际下载路径和文件名。其中,path是路径,filename为文件名。
- 强烈建议:
① 路径和文件名中不要出现空格或其他特殊字符。
② 路径和文件名最好以英文命名,不要以中文或其他特殊字符命名。
- 根据 Python 版本的不同有选择性地在终端输入命令:
▫ Python 3.6: bash ~/Downloads/Anaconda3-5.0.1-Linux-x86_64.sh
▫ Python 2.7: bash ~/Downloads/Anaconda2-5.0.1-Linux-x86_64.sh
- 注意:
① 首词 bash 也需要输入,无论是否用的 Bash shell。
② 如果你的下载路径是自定义的,那么把该步骤路径中的 ~/Downloads 替换成你自己的下载路径。
③ 除非被要求使用 root 权限,否则均选择“Install Anaconda as a user”。
-
安装过程中,看到提示“In order to continue the installation process, please review the license agreement.”(“请浏览许可证协议以便继续安装。”),点击“Enter”查看“许可证协议”。
-
在“许可证协议”界面将屏幕滚动至底,输入“yes”表示同意许可证协议内容。然后进行下一步。
-
安装过程中,提示“Press Enter to accept the default install location, CTRL-C to cancel the installation or specify an alternate installation directory.”(“按回车键确认安装路径,按'CTRL-C'取消安装或者指定安装目录。”)如果接受默认安装路径,则会显示PREFIX=/home/
/anaconda<2 or 3> 并且继续安装。安装过程大约需要几分钟的时间。
- 建议:直接接受默认安装路径。
- 安装器若提示“Do you wish the installer to prepend the Anaconda<2 or 3> install location to PATH in your /home/
/.bashrc ?”(“你希望安装器添加Anaconda安装路径在 /home/ /.bashrc 文件中吗?”),建议输入“yes”。
- 注意:
① 路径 /home/
② 如果输入“no”,则需要手动添加路径,否则conda将无法正常运行。
-
当看到“Thank you for installing Anaconda<2 or 3>!”则说明已经成功完成安装。
-
关闭终端,然后再打开终端以使安装后的 Anaconda 启动。或者直接在终端中输入
source ~/.bashrc也可完成启动。 -
验证安装结果。可选用以下任意一种方法:
① 在终端中输入命令 condal list ,如果 Anaconda 被成功安装,则会显示已经安装的包名和版本号。
② 在终端中输入python。这条命令将会启动 Python 交互界面,如果 Anaconda 被成功安装并且可以运行,则将会在 Python 版本号的右边显示“Anaconda custom (64-bit)”。退出 Python 交互界面则输入 exit() 或 quit() 即可。
③ 在终端中输入 anaconda-navigator 。如果 Anaconda 被成功安装,则 Anaconda Navigator 将会被启动。
2.Window 安装
-
前往官方下载页面下载。有两个版本可供选择:Python 3.6 和 Python 2.7,选择之后根据自己操作系统的情况点击“64-Bit Graphical Installer”或“32-Bit Graphical Installer”进行下载。
-
完成下载之后,双击下载文件,启动安装程序。
- 注意:
① 如果在安装过程中遇到任何问题,那么暂时地关闭杀毒软件,并在安装程序完成之后再打开。
② 如果在安装时选择了“为所有用户安装”,则卸载 Anaconda 然后重新安装,只为“我这个用户”安装。
-
选择“Next”。
-
阅读许可证协议条款,然后勾选“I Agree”并进行下一步。
-
除非是以管理员身份为所有用户安装,否则仅勾选“Just Me”并点击“Next”。
-
在“Choose Install Location”界面中选择安装 Anaconda 的目标路径,然后点击“Next”。
- 注意:
① 目标路径中不能含有空格,同时不能是**“unicode”**编码。
② 除非被要求以管理员权限安装,否则不要以管理员身份安装。
- 在“Advanced Installation Options”中不要勾选“Add Anaconda to my PATH environment variable.”(“添加Anaconda至我的环境变量。”)。因为如果勾选,则将会影响其他程序的使用。如果使用 Anaconda,则通过打开 Anaconda Navigator或者在开始菜单中的“Anaconda Prompt”(类似macOS中的“终端”)中进行使用。
除非你打算使用多个版本的 Anaconda 或者多个版本的 Python,否则便勾选“Register Anaconda as my default Python 3.6”。
然后点击“Install”开始安装。如果想要查看安装细节,则可以点击“Show Details”。
-
点击“Next”。
-
进入“Thanks for installing Anaconda!”界面则意味着安装成功,点击“Finish”完成安装。
- 注意:如果你不想了解“Anaconda云”和“Anaconda支持”,则可以不勾选“Learn more about Anaconda Cloud”和“Learn more about Anaconda Support”。
- 验证安装结果。可选以下任意方法:
① “开始 → Anaconda3(64-bit)→ Anaconda Navigator”,若可以成功启动Anaconda Navigator则说明安装成功。
② “开始 → Anaconda3(64-bit)→ 右键点击Anaconda Prompt → 以管理员身份运行”,在Anaconda Prompt中输入 conda list ,可以查看已经安装的包名和版本号。若结果可以正常显示,则说明安装成功。
3.Mac 安装
两种安装方法,第一种是图形界面安装:
-
前往官方下载页面下载。有两个版本可供选择:Python 3.6 和 Python 2.7,目前推荐选择前者,也可以根据自己学习或者工作需求选择不同版本。选择版之后点击“64-Bit Graphical Installer”进行下载。
-
完成下载之后,双击下载文件,在对话框中“Introduction”、“Read Me”、“License”部分可直接点击下一步
-
“Destination Select”部分选择“Install for me only”并点击下一步。
- 注意:若有错误提示信息“You cannot install Anaconda in this location”则重新选择“Install for me only”并点击下一步。
4.“Installation Type”部分,可以点击“Change Install Location”来改变安装位置。标准的安装路径是在用户的家目录下。若选择默认安装路径,则直接点击“Install”进行安装。
5.等待“Installation”部分结束,在“Summary”部分若看到“The installation was completed successfully.”则安装成功,直接点击“Close”关闭对话框。
6.在 mac 的 Launchpad 中可以找到名为 “Anaconda-Navigator” 的图标,点击打开。
7.若“Anaconda-Navigator”成功启动,则说明真正成功地安装了Anaconda;如果未成功,请务必仔细检查以上安装步骤。
8.完成安装
第二种方法,命令行安装:
1.前往官方下载页面下载。有两个版本可供选择:Python 3.6 和 Python 2.7,目前推荐选择前者,也可以根据自己学习或者工作需求选择不同版本。选择版之后点击“64-Bit Graphical Installer”进行下载。
2.完成下载之后,在mac的Launchpad中找到“其他”并打开“终端”。
▫ 安装Python 3.6: bash ~/Downloads/Anaconda3-5.0.1-MacOSX-x86_64.sh
▫ 安装Python 2.7: bash ~/Downloads/Anaconda2-5.0.1-MacOSX-x86_64.sh
如果下载路径是自定义,将路径中的~/Downloads 替换为你下载的路径,此外如果更改过下载的文件名,那么也将 Anaconda3-5.0.1-MacOSX-x86_64.sh 更改为你修改的文件名。
ps:强烈建议不要修改文件名,如果重命名,也要采用英文进行命名。
3.安装过程中,看到提示“In order to continue the installation process, please review the license agreement.”(“请浏览许可证协议以便继续安装。”),点击“Enter”查看“许可证协议”。
-
在“许可证协议”界面将屏幕滚动至底,输入“yes”表示同意许可证协议内容。然后进行下一步。
-
安装过程中,提示“Press Enter to confirm the location, Press CTRL-C to cancel the installation or specify an alternate installation directory.”(“按回车键确认安装路径,按'CTRL-C'取消安装或者指定安装目录。”)如果接受默认安装路径,则会显示 PREFIX=/home/
/anaconda<2 or 3> 并且继续安装。安装过程大约需要几分钟的时间。
- 建议:直接接受默认安装路径。
- 安装器若提示“Do you wish the installer to prepend the Anaconda install location to PATH in your /home/
/.bash_profile ?”(“你希望安装器添加Anaconda安装路径在**/home/ /.bash_profile** 文件中吗?”),建议输入“yes”。
- 注意:
① 路径 /home/
②如果输入“no”,则需要手动添加路径。添加 export PATH="/
-
当看到“Thank you for installing Anaconda!”则说明已经成功完成安装。
-
关闭终端,然后再打开终端以使安装后的 Anaconda 启动。
-
验证安装结果。可选用以下任意一种方法:
- 在终端中输入命令 condal list ,如果 Anaconda 被成功安装,则会显示已经安装的包名和版本号。
- 在终端中输入 python 。这条命令将会启动 Python 交互界面,如果 Anaconda 被成功安装并且可以运行,则将会在Python版本号的右边显示“Anaconda custom (64-bit)”。退出 Python 交互界面则输入 exit() 或 quit() 即可。
- 在终端中输入 anaconda-navigator 。如果 Anaconda 被成功安装,则 Anaconda Navigator 的图形界面将会被启动。
Anaconda 使用
简单介绍几个 Anaconda 的基本使用命令:
1.查看版本
conda --version
2.创建环境
# 基本命令
conda create --name <env_name> <package_names>
# 例子:创建一个 python3.6 的环境, 环境名字为 py36
conda create -n py36 python=3.6
3.删除环境
conda remove -n py36 --all
4.激活环境
source activate py36
5.退出环境
source deactivate
Jupyter Notebook 安装
1.简介
Jupyter Notebook 是一个开源的 Web 应用程序,允许用户创建和共享包含代码、方程式、可视化和文本的文档。它的用途包括:数据清理和转换、数值模拟、统计建模、数据可视化、机器学习等等。它具有以下优势:
- 可选择语言:支持超过40种编程语言,包括 Python、R、Julia、Scala等。
- 分享笔记本:可以使用电子邮件、Dropbox、GitHub 和 Jupyter Notebook Viewer 与他人共享。
- 交互式输出:代码可以生成丰富的交互式输出,包括 HTML、图像、视频、LaTeX 等等。
- 大数据整合:通过 Python、R、Scala 编程语言使用 Apache Spark 等大数据框架工具。支持使用 pandas、scikit-learn、ggplot2、TensorFlow 来探索同一份数据。
2.安装
有两种安装的方式,分别是通过 Anaconda 安装和命令行安装。
第一种方式就是安装 Anaconda ,它附带 Jupyter Notebook 等常用的科学计算和数据科学软件包。
第二种通过命令行安装,命令如下,根据安装的 Python 选择对应的命令安装即可。
# Pyhton 3
python3 -m pip install --upgrade pip
python3 -m pip install jupyter
# Python 2
python -m pip install --upgrade pip
python -m pip install jupyter
3.运行和使用
运行 Jupyter Notebook 的方法很简单,只需要在系统的终端(Mac/Linux 的 Terminal,Window 的 cmd) 运行以下命令即可:
jupyter notebook
官方文档地址如下:
https://jupyter.org/documentation
Pycharm 安装
Pycharm 是 Python 的一个 IDE,配置简单,功能强大,而且对初学者友好,下面介绍如何安装和简单配置 Pycharm。
1.安装
Pycharm 提供 免费的社区版 与 付费的专业版。专业版额外增加了一些功能,如项目模板、远程开发、数据库支持等。个人学习 Python 使用免费的社区版已足够。 pycharm社区版:PyCharm :: Download Latest Version of PyCharm
安装过程照着提示一步步操作就可以了。注意安装路径尽量不使用带有 中文或空格 的目录,这样在之后的使用过程中减少一些莫名的错误。
2.配置
Pycharm 提供的配置很多,这里讲几个比较重要的配置
编码设置:
Python 的编码问题由来已久,为了避免一步一坑,Pycharm 提供了方便直接的解决方案
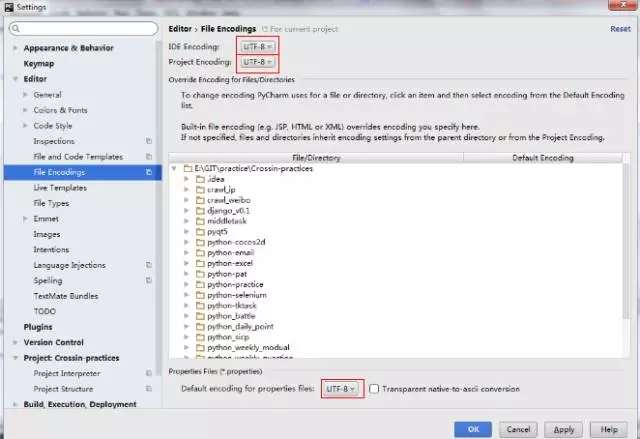
在 IDE Encoding 、Project Encoding 、Property Files 三处都使用 UTF-8 编码,同时在文件头添加
#-*- coding: utf-8 -
这样在之后的学习过程中,或多或少会避免一些编码坑。
解释器设置:
当有多个版本安装在电脑上,或者需要管理虚拟环境时,Project Interpreter 提供方便的管理工具。
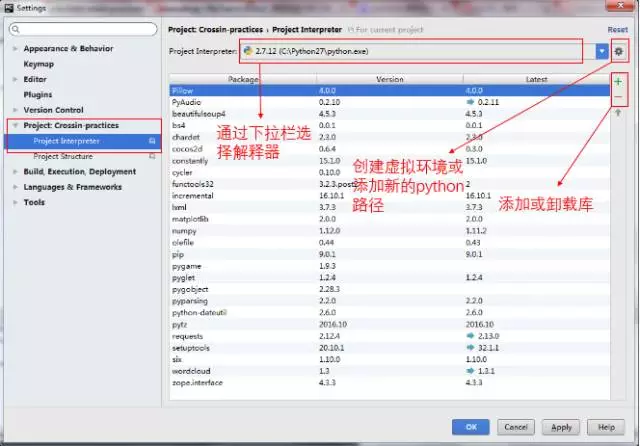
在这里可以方便的切换 Python 版本,添加卸载库等操作。
修改字体:
在 Editor → Font 选项下可以修改字体,调整字体大小等功能。
快捷键设置:
在 windows 下一些最常用的默认快捷键:
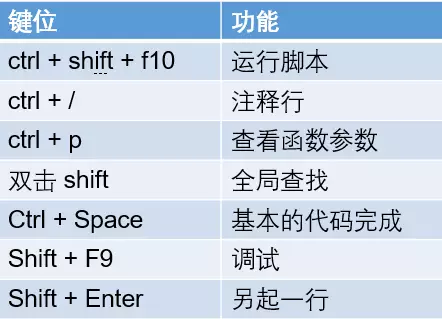
Pycharm 也为不同平台的用户提供了定制的快捷键方案,习惯了用emacs、vim、vs的同学,可以直接选择对应的方案。
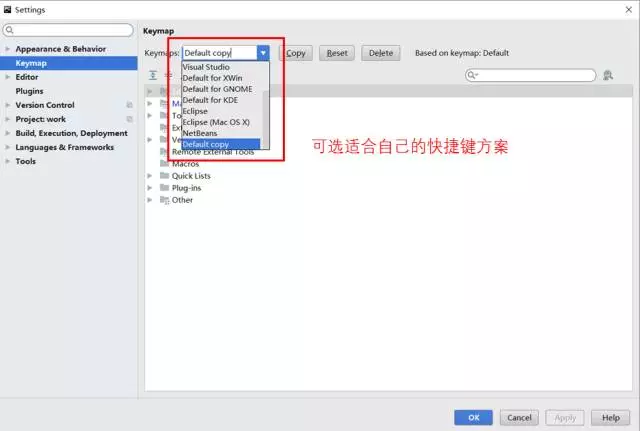
同时,Pycharm 也提供了自定义快捷键的功能。
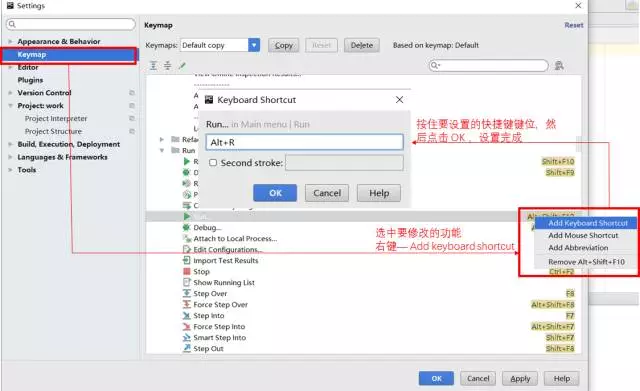
修改完成之后就去试试效果吧!
3.调试
强大的 Pycharm 为我们提供了方便易用的断点调试功能,步骤如下图所示:
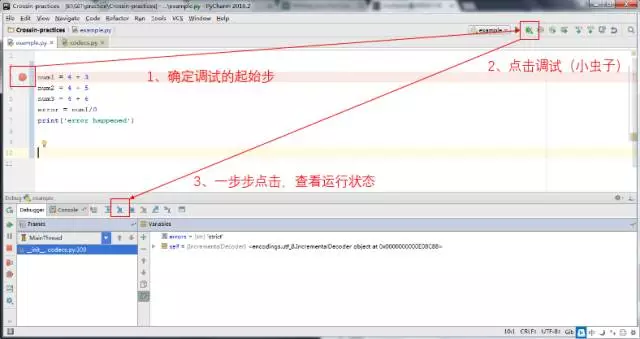
简单介绍一下调试栏的几个重要的按钮作用:

Resume Program:断点调试后,点击按钮,继续执行程序;

Step Over :在单步执行时,在函数内遇到子函数时不会进入子函数内单步执行,而是将子函数整个执行完再停止,也就是把子函数整个作为一步。有一点,经过我们简单的调试,在不存在子函数的情况下是和Step Into效果一样的(简而言之,越过子函数,但子函数会执行);

Step Into:单步执行,遇到子函数就进入并且继续单步执行(简而言之,进入子函数);

Step Out : 当单步执行到子函数内时,用step out就可以执行完子函数余下部分,并返回到上一层函数。
如果程序在某一步出现错误,程序会自动跳转到错误页面,方便我们查看错误信息 更详细的关于调试的知识参考之前的一篇文章:
如何在 Python 中使用断点调试 - Crossin的编程教室 - 知乎专栏
另外,PyCharm 还提供了一个方便调试的小功能,但隐藏得比较深,参见:
pycharm 如何程序运行后,仍可查看变量值? - 知乎专栏
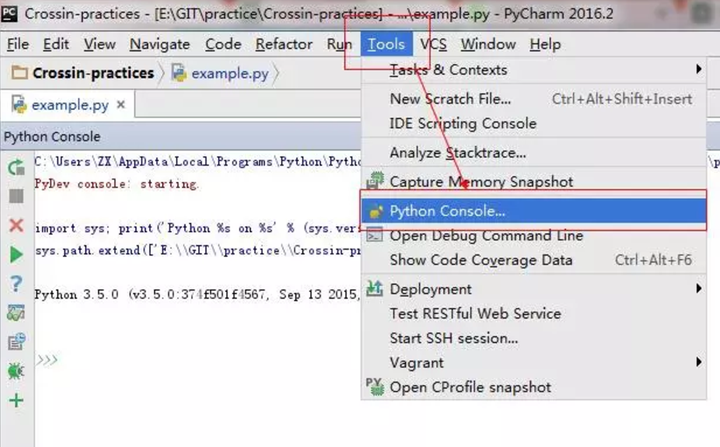
4.Python 控制台
为了方便用户,Pycharm 提供了另一个贴心的功能,将 Python shell 直接集成在软件中,调出方法如下:
2. 基础语法和变量类型
注意:主要是基于 Python 3 的语法来介绍,并且代码例子也是在 Python3 环境下运行的。
2.1 基础语法
标识符
标识符由字母、数字和下划线(_)组成,其中不能以数字开头,并且区分大小写。
以下划线开头的标识符是有特殊意义的:
- 单下划线开头的如
_foo,表示不能直接访问的类属性,需要通过类提供的接口进行访问,不能通过from xxx import *导入; - 双下划线开头的如
__foo,表示类的私有成员; - 双下划线开头和结尾的如
__foo__代表 Python 中的特殊方法,比如__init()__代表类的构建函数
保留字
保留字是不能用作常数或变数,或者其他任何标识符名称。 keyword 模块可以输出当前版本的所有关键字:
import keyword
print(keyword.kwlist)
所有的保留字如下所示:
| and | exec | not |
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
行和缩进
和其他编程语言的最大区别就是,Python 的代码块不采用大括号 {} 来控制类、函数以及其他逻辑判断,反倒是采用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行,如下所示:
# 正确示例
i = 2
if i == 3:
print('true!')
else:
print('False')
# 错误示例
if i == 3:
print('i:')
print(i)
else:
print('wrong answer!')
# 没有严格缩进,执行时会报错
print('please check again')
这里将会报错 IndentationError: unindent does not match any outer indentation level,这个错误表示采用的缩进方式不一致,有的是 tab 键缩进,有的是空格缩进,改为一致即可。
而如果错误是 IndentationError: unexpected indent,表示格式不正确,可能是 tab 和空格没对齐的问题。
因此,按照约定俗成的管理,应该始终坚持使用4个空格的缩进,并且注意不能混合使用 tab 键和四格空格,这会报错!
注释
注释分为两种,单行和多行的。
# 单行注释
print('Hello, world!')
'''
这是多行注释,使用单引号。
这是多行注释,使用单引号。
这是多行注释,使用单引号。
'''
"""
这是多行注释,使用双引号。
这是多行注释,使用双引号。
这是多行注释,使用双引号。
"""
输入输出
通常是一条语句一行,如果语句很长,我们可以使用**反斜杠(\)**来实现多行语句。在 [], {}, 或 () 中的多行语句,则不需要反斜杠。
sentence1 = "I love " + \
"python"
sentence2 = ["I", "love",
"python"]
另外,我们也可以同一行显示多条语句,语句之间用分号(;)分割,示例如下:
print('Hello');print('world')
对于用户输入,Python2 采用的是 raw_input(),而 3 版本则是 input() 函数:
# 等待用户输入
# python 2
user_input = raw_input('请输入一个数字:\n')
# python 3
user_input = input('请输入一个数字:\n')
print('user_input=', user_input)
其中 \n 实现换行。用户按下回车键(enter)退出,其他键显示。
对于 print 输出,默认输出是换行的,如果需要实现不换行,可以指定参数 end,如下所示:
a = 3
b = 2
c = 4
d = 5
# 默认换行
print(a)
print(b)
# 不换行,并设置逗号分隔
print(c, end=',')
print(d)
2.2 基本变量类型
计算机程序要处理不同的数据,需要定义不同的数据类型。Python 定义了六种标准的数据类型,分布如下所示:
- Numbers(数字)
- Strings(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
变量赋值
Python 并不需要声明变量的类型,所说的"类型"是变量所指的内存中对象的类型。但每个变量使用前都必须赋值,然后才会创建变量。给变量赋值的方法是采用等号(=),等号左边是变量名,右边是存储在变量中的值。
一个示例如下:
counter = 100 # 赋值整型变量
miles = 1000.0 # 浮点型
name = "John" # 字符串
print(counter)
print(miles)
print(name)
Python 还允许同时为多个变量赋值,有以下两种实现方式:
# 创建一个整型对象,值为1,三个变量被分配到相同的内存空间上
n = m = k = 2
# 创建多个对象,然后指定多个变量
cc, mm, nn = 1, 3.2, 'abc'
print('n=m=k=', n, m, k)
print('cc=', cc)
print('mm=', mm)
print('nn=', nn)
其中同时给多个变量赋值的方式也是 Python 独特的一种变量赋值方法。
数字
数字类型用于存储数值,它是不可改变的数据类型。Python 3 支持以下几种数字类型:
-
int (整数)
-
float (浮点型)
-
complex(复数)
-
bool (布尔)
数字类型的使用很简单,也很直观,如下所示:
# int
q = 1
# float
w = 2.3
# bool
e = True
# complex
r = 1 + 3j
print(q, w, e, r) # 1 2.3 True (1+3j)
# 内置的 type() 函数可以用来查询变量所指的对象类型
print(type(q)) # <class 'int'>
print(type(w)) # <class 'float'>
print(type(e)) # <class 'bool'>
print(type(r)) # <class 'complex'>
# 也可以采用 isinstance()
# isinstance 和 type 的区别在于:type()不会认为子类是一种父类类型,isinstance()会认为子类是一种父类类型
print(isinstance(q, int)) # True
print(isinstance(q, float)) # False
对于数字的运算,包括基本的加减乘除,其中除法包含两个运算符,/ 返回一个浮点数,而 // 则是得到整数,去掉小数点后的数值。而且在混合计算的时候, Python 会把整数转换为浮点数。
# 加
print('2 + 3 =', 2 + 3) # 2 + 3 = 5
# 减
print('3 - 2 =', 3 - 2) # 3 - 2 = 1
# 乘
print('5 * 8 =', 5 * 8) # 5 * 8 = 40
# 除
# 得到浮点数,完整的结果
print('5 / 2 =', 5 / 2) # 5 / 2 = 2.5
# 得到一个整数
print('5 // 2 =', 5 // 2) # 5 // 2 = 2
# 取余
print('5 % 2 =', 5 % 2) # 5 % 2 = 1
# 乘方
print('5 ** 2 =', 5 ** 2) # 5 ** 2 = 25
字符串
字符串或串(String)是由数字、字母、下划线组成的一串字符。一般是用单引号 '' 或者 "" 括起来。
注意,Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。并且,Python 字符串是不可变,向一个索引位置赋值,如 strs[0]='m' 会报错。
可以通过索引值或者切片来访问字符串的某个或者某段元素,注意索引值从 0 开始,例子如下所示:

切片的格式是 [start:end],实际取值范围是 [start:end) ,即不包含 end 索引位置的元素。还会除了正序访问,还可以倒序访问,即索引值可以是负值。
具体示例如下所示:
s1 = "talk is cheap"
s2 = 'show me the code'
print(s1)
print(s2)
# 索引值以 0 为开始值,-1 为从末尾的开始位置
print('输出 s1 第一个到倒数第二个的所有字符: ', s1[0:-1]) # 输出第一个到倒数第二个的所有字符
print('输出 s1 字符串第一个字符: ', s1[0]) # 输出字符串第一个字符
print('输出 s1 从第三个开始到第六个的字符: ', s1[2:6]) # 输出从第三个开始到第六个的字符
print('输出 s1 从第三个开始的后的所有字符:', s1[2:]) # 输出从第三个开始的后的所有字符
# 加号 + 是字符串的连接符
# 星号 * 表示复制当前字符串,紧跟的数字为复制的次数
str = "I love python "
print("连接字符串:", str + "!!!")
print("输出字符串两次:", str * 2)
# 反斜杠 \ 转义特殊字符
# 若不想让反斜杠发生转义,可以在字符串前面添加一个 r
print('I\nlove\npython')
print("反斜杠转义失效:", r'I\nlove\npython')
注意:
- 1、反斜杠可以用来转义,使用 r 可以让反斜杠不发生转义。
- 2、字符串可以用 + 运算符连接在一起,用 * 运算符重复。
- 3、Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
- 4、Python 中的字符串不能改变。
字符串包含了很多内置的函数,这里只介绍几种非常常见的函数:
-
strip(x):当包含参数
x表示删除句首或者句末x的部分,否则,就是删除句首和句末的空白字符,并且可以根据需要调用lstrip()和rstrip(),分别删除句首和句末的空白字符; - split():同样可以包含参数,如果不包含参数就是将字符串变为单词形式,如果包含参数,就是根据参数来划分字符串;
- join():主要是将其他类型的集合根据一定规则变为字符串,比如列表;
-
replace(x, y):采用字符串
y代替x - index():查找指定字符串的起始位置
- startswith() / endswith():分别判断字符串是否以某个字符串为开始,或者结束;
- find():查找某个字符串;
- upper() / lower() / title():改变字符串的大小写的三个函数
下面是具体示例代码:
# strip()
s3 = " I love python "
s4 = "show something!"
print('输出直接调用 strip() 后的字符串结果: ', s3.strip())
print('lstrip() 删除左侧空白后的字符串结果: ', s3.lstrip())
print('rstrip() 删除右侧空白后的字符串结果: ', s3.rstrip())
print('输出调用 strip(\'!\')后的字符串结果: ', s4.strip('!'))
# split()
s5 = 'hello, world'
print('采用split()的字符串结果: ', s5.split())
print('采用split(\',\')的字符串结果: ', s5.split(','))
# join()
l1 = ['an', 'apple', 'in', 'the', 'table']
print('采用join()连接列表 l1 的结果: ', ''.join(l1))
print('采用\'-\'.join()连接列表 l1 的结果: ', '-'.join(l1))
# replace()
print('replace(\'o\', \'l\')的输出结果: ', s5.replace('o', 'l'))
# index()
print('s5.index(\'o\')的输出结果: ', s5.index('o'))
# startswith() / endswith()
print('s5.startswith(\'h\')的输出结果: ', s5.startswith('h'))
print('s5.endswith(\'h\')的输出结果: ', s5.endswith('h'))
# find()
print('s5.find(\'h\')的输出结果: ', s5.find('h'))
# upper() / lower() / title()
print('upper() 字母全大写的输出结果: ', s5.upper())
print('lower() 字母全小写的输出结果: ', s5.lower())
print('title() 单词首字母大写的输出结果: ', s5.title())
列表
列表是 Python 中使用最频繁的数据类型,它可以完成大多数集合类的数据结构实现,可以包含不同类型的元素,包括数字、字符串,甚至列表(也就是所谓的嵌套)。
和字符串一样,可以通过索引值或者切片(截取)进行访问元素,索引也是从 0 开始,而如果是倒序,则是从 -1 开始。列表截取的示意图如下所示:

另外,还可以添加第三个参数作为步长:
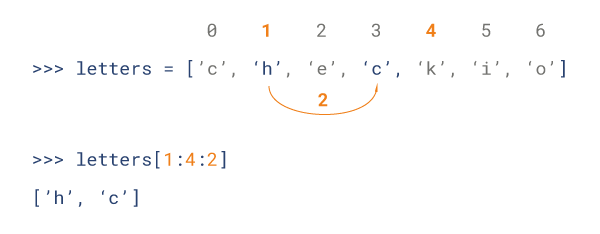
同样,列表也有很多内置的方法,这里介绍一些常见的方法:
- len(list):返回列表的长度
- append(obj) / insert(index, obj) / extend(seq):增加元素的几个方法
- pop() / remove(obj) / del list[index] / clear():删除元素
- reverse() / reversed:反转列表
- sort() / sorted(list):对列表排序,注意前者会修改列表内容,后者返回一个新的列表对象,不改变原始列表
- index():查找给定元素第一次出现的索引位置
初始化列表的代码示例如下:
# 创建空列表,两种方法
list1 = list()
list2 = []
# 初始化带有数据
list3 = [1, 2, 3]
list4 = ['a', 2, 'nb', [1, 3, 4]]
print('list1:', list1)
print('list2:', list2)
print('list3:', list3)
print('list4:', list4)
print('len(list4): ', len(list4))
添加元素的代码示例如下:
# 末尾添加元素
list1.append('abc')
print('list1:', list1)
# 末尾添加另一个列表,并合并为一个列表
list1.extend(list3)
print('list1.extend(list3), list1:', list1)
list1.extend((1, 3))
print('list1.extend((1,3)), list1:', list1)
# 通过 += 添加元素
list2 += [1, 2, 3]
print('list2:', list2)
list2 += list4
print('list2:', list2)
# 在指定位置添加元素,原始位置元素右移一位
list3.insert(0, 'a')
print('list3:', list3)
# 末尾位置添加,原来末尾元素依然保持在末尾
list3.insert(-1, 'b')
print('list3:', list3)
删除元素的代码示例如下:
# del 删除指定位置元素
del list3[-1]
print('del list3[-1], list3:', list3)
# pop 删除元素
pop_el = list3.pop()
print('list3:', list3)
print('pop element:', pop_el)
# pop 删除指定位置元素
pop_el2 = list3.pop(0)
print('list3:', list3)
print('pop element:', pop_el2)
# remove 根据值删除元素
list3.remove(1)
print('list3:', list3)
# clear 清空列表
list3.clear()
print('clear list3:', list3)
查找元素和修改、访问元素的代码示例如下:
# index 根据数值查询索引
ind = list1.index(3)
print('list1.index(3),index=', ind)
# 访问列表第一个元素
print('list1[0]: ', list1[0])
# 访问列表最后一个元素
print('list1[-1]: ', list1[-1])
# 访问第一个到第三个元素
print('list1[:3]: ', list1[:3])
# 访问第一个到第三个元素,步长为2
print('list1[:3:2]: ', list1[:3:2])
# 复制列表
new_list = list1[:]
print('copy list1, new_list:', new_list)
排序的代码示例如下:
list5 = [3, 1, 4, 2, 5]
print('list5:', list5)
# use sorted
list6 = sorted(list5)
print('list6=sorted(list5), list5={}, list6={}'.format(list5, list6))
# use list.sort()
list5.sort()
print('list5.sort(), list5: ', list5)
sorted() 都不会改变列表本身的顺序,只是对列表临时排序,并返回一个新的列表对象;
相反,列表本身的 sort() 会永久性改变列表本身的顺序。
另外,如果列表元素不是单纯的数值类型,如整数或者浮点数,而是字符串、列表、字典或者元组,那么还可以自定义排序规则,这也就是定义中最后两行,例子如下:
# 列表元素也是列表
list8 = [[4, 3], [5, 2], [1, 1]]
list9 = sorted(list8)
print('list9 = sorted(list8), list9=', list9)
# sorted by the second element
list10 = sorted(list8, key=lambda x: x[1])
print('list10 = sorted(list8, key=lambda x:x[1]), list10=', list10)
list11 = sorted(list8, key=lambda x: (x[1], x[0]))
print('list11 = sorted(list8, key=lambda x:(x[1],x[0])), list11=', list11)
# 列表元素是字符串
list_str = ['abc', 'pat', 'cda', 'nba']
list_str_1 = sorted(list_str)
print('list_str_1 = sorted(list_str), list_str_1=', list_str_1)
# 根据第二个元素排列
list_str_2 = sorted(list_str, key=lambda x: x[1])
print('list_str_2 = sorted(list_str, key=lambda x: x[1]), list_str_2=', list_str_2)
# 先根据第三个元素,再根据第一个元素排列
list_str_3 = sorted(list_str, key=lambda x: (x[2], x[0]))
print('list_str_3 = sorted(list_str, key=lambda x: (x[2], x[0])), list_str_3=', list_str_3)
反转列表的代码示例如下:
# 反转列表
list5.reverse()
print('list5.reverse(), list5: ', list5)
list7 = reversed(list5)
print('list7=reversed(list5), list5={}, list7={}'.format(list5, list7))
#for val in list7:
# print(val)
# 注意不能同时两次
list7_val = [val for val in list7]
print('采用列表推导式, list7_val=', list7_val)
list8 = list5[::-1]
print('list5 = {}\nlist_reversed = list5[::-1], list_reversed = {}'.format(list5, list_reversed))
reverse() 方法会永久改变列表本身,而 reversed() 不会改变列表对象,它返回的是一个迭代对象,如例子输出的 <list_reverseiterator object at 0x000001D0A17C5550> , 要获取其排序后的结果,需要通过 for 循环,或者列表推导式,但需要注意,它仅仅在第一次遍历时候返回数值。
以及,一个小小的技巧,利用切片实现反转,即 <list> = <list>[::-1]。
元组
元组和列表比较相似,不同之处是元组不能修改,然后元组是写在小括号 () 里的。
元组也可以包含不同的元素类型。简单的代码示例如下:
t1 = tuple()
t2 = ()
t3 = (1, 2, '2', [1, 2], 5)
# 创建一个元素的元祖
t4 = (7, )
t5 = (2)
print('创建两个空元组:t1={}, t2={}'.format(t1, t2))
print('包含不同元素类型的元组:t3={}'.format(t3))
print('包含一个元素的元祖: t4=(7, )={}, t5=(2)={}'.format(t4, t5))
print('type(t4)={}, type(t5)={}'.format(type(t4), type(t5)))
print('输出元组的第一个元素:{}'.format(t3[0]))
print('输出元组的第二个到第四个元素:{}'.format(t3[1:4]))
print('输出元祖的最后一个元素: {}'.format(t3[-1]))
print('输出元祖两次: {}'.format(t3 * 2))
print('连接元祖: {}'.format(t3 + t4))
元祖和字符串也是类似,索引从 0 开始,-1 是末尾开始的位置,可以将字符串看作一种特殊的元组。
此外,从上述代码示例可以看到有个特殊的例子,创建一个元素的时候,必须在元素后面添加逗号,即如下所示:
tup1 = (2,) # 输出为 (2,)
tup2 = (2) # 输出是 2
print('type(tup1)={}'.format(type(tup1))) # 输出是 <class 'tuple'>
print('type(tup2)={}'.format(type(tup2))) # 输出是 <class 'int'>
还可以创建一个二维元组,代码例子如下:
# 创建一个二维元组
tups = (1, 3, 4), ('1', 'abc')
print('二维元组: {}'.format(tups)) # 二维元组: ((1, 3, 4), ('1', 'abc'))
然后对于函数的返回值,如果返回多个,实际上就是返回一个元组,代码例子如下:
def print_tup():
return 1, '2'
res = print_tup()
print('type(res)={}, res={}'.format(type(res), res)) # type(res)=<class 'tuple'>, res=(1, '2')
元组不可修改,但如果元素可修改,那可以修改该元素内容,代码例子如下所示:
tup11 = (1, [1, 3], '2')
print('tup1={}'.format(tup11)) # tup1=(1, [1, 3], '2')
tup11[1].append('123')
print('修改tup11[1]后,tup11={}'.format(tup11)) # 修改tup11[1]后,tup11=(1, [1, 3, '123'], '2')
因为元组不可修改,所以仅有以下两个方法:
- count(): 计算某个元素出现的次数
- index(): 寻找某个元素第一次出现的索引位置
代码例子:
# count()
print('tup11.count(1)={}'.format(tup11.count(1)))
# index()
print('tup11.index(\'2\')={}'.format(tup11.index('2')))
字典
字典也是 Python 中非常常用的数据类型,具有以下特点:
- 它是一种映射类型,用
{}标识,是无序的 键(key): 值(value) 的集合; - 键(key) 必须使用不可变类型;
- 同一个字典中,键必须是唯一的;
创建字典的代码示例如下,总共有三种方法:
# {} 形式
dic1 = {'name': 'python', 'age': 20}
# 内置方法 dict()
dic2 = dict(name='p', age=3)
# 字典推导式
dic3 = {x: x**2 for x in {2, 4, 6}}
print('dic1={}'.format(dic1)) # dic1={'age': 20, 'name': 'python'}
print('dic2={}'.format(dic2)) # dic2={'age': 3, 'name': 'p'}
print('dic3={}'.format(dic3)) # dic3={2: 4, 4: 16, 6: 36}
常见的三个内置方法,keys(), values(), items() 分别表示键、值、对,例子如下:
print('keys()方法,dic1.keys()={}'.format(dic1.keys()))
print('values()方法, dic1.values()={}'.format(dic1.values()))
print('items()方法, dic1.items()={}'.format(dic1.items()))
其他对字典的操作,包括增删查改,如下所示:
# 修改和访问
dic1['age'] = 33
dic1.setdefault('sex', 'male')
print('dic1={}'.format(dic1))
# get() 访问某个键
print('dic1.get(\'age\', 11)={}'.format(dic1.get('age', 11)))
print('访问某个不存在的键,dic1.get(\'score\', 100)={}'.format(dic1.get('score', 100)))
# 删除
del dic1['sex']
print('del dic1[\'sex\'], dic1={}'.format(dic1))
dic1.pop('age')
print('dic1.pop(\'age\'), dic1={}'.format(dic1))
# 清空
dic1.clear()
print('dic1.clear(), dic1={}'.format(dic1))
# 合并两个字典
print('合并 dic2 和 dic3 前, dic2={}, dic3={}'.format(dic2, dic3))
dic2.update(dic3)
print('合并后,dic2={}'.format(dic2))
# 遍历字典
dic4 = {'a': 1, 'b': 2}
for key, val in dic4.items():
print('{}: {}'.format(key, val))
# 不需要采用 keys()
for key in dic4:
print('{}: {}'.format(key, dic4[key]))
最后,因为字典的键必须是不可改变的数据类型,那么如何快速判断一个数据类型是否可以更改呢?有以下两种方法:
- id():判断变量更改前后的 id,如果一样表示可以更改,不一样表示不可更改。
- hash():如果不报错,表示可以被哈希,就表示不可更改;否则就是可以更改。
首先看下 id() 方法,在一个整型变量上的使用结果:
i = 2
print('i id value=', id(i))
i += 3
print('i id value=', id(i))
输出结果,更改前后 id 是更改了,表明整型变量是不可更改的。
i id value= 1758265872
i id value= 1758265968
然后在列表变量上进行同样的操作:
l1 = [1, 3]
print('l1 id value=', id(l1))
l1.append(4)
print('l1 id value=', id(l1))
输出结果,id 并没有改变,说明列表是可以更改的。
l1 id value= 1610679318408
l1 id value= 1610679318408
然后就是采用 hash() 的代码例子:
# hash
s = 'abc'
print('s hash value: ', hash(s))
l2 = ['321', 1]
print('l2 hash value: ', hash(l2))
输出结果如下,对于字符串成功输出哈希值,而列表则报错 TypeError: unhashable type: 'list',这也说明了字符串不可更改,而列表可以更改。
s hash value: 1106005493183980421
TypeError: unhashable type: 'list'
集合
集合是一个无序的不重复元素序列,采用大括号 {} 或者 set() 创建,但空集合必须使用 set() ,因为 {} 创建的是空字典。
创建的代码示例如下:
# 创建集合
s1 = {'a', 'b', 'c'}
s2 = set()
s3 = set('abc')
print('s1={}'.format(s1)) # s1={'b', 'a', 'c'}
print('s2={}'.format(s2)) # s2=set()
print('s3={}'.format(s3)) # s3={'b', 'a', 'c'}
注意上述输出的时候,每次运行顺序都可能不同,这是集合的无序性的原因。
利用集合可以去除重复的元素,如下所示:
s4 = set('good')
print('s4={}'.format(s4)) # s4={'g', 'o', 'd'}
集合也可以进行增加和删除元素的操作,代码如下所示:
# 增加元素,add() 和 update()
s1.add('dd')
print('s1.add(\'dd\'), s1={}'.format(s1)) # s1.add('dd'), s1={'dd', 'b', 'a', 'c'}
s1.update('o')
print('添加一个元素,s1={}'.format(s1)) # 添加一个元素,s1={'dd', 'o', 'b', 'a', 'c'}
s1.update(['n', 1])
print('添加多个元素, s1={}'.format(s1)) # 添加多个元素, s1={1, 'o', 'n', 'a', 'dd', 'b', 'c'}
s1.update([12, 33], {'ab', 'cd'})
print('添加列表和集合, s1={}'.format(s1)) # 添加列表和集合, s1={1, 33, 'o', 'n', 'a', 12, 'ab', 'dd', 'cd', 'b', 'c'}
# 删除元素, pop(), remove(), clear()
print('s3={}'.format(s3)) # s3={'b', 'a', 'c'}
s3.pop()
print('随机删除元素, s3={}'.format(s3)) # 随机删除元素, s3={'a', 'c'}
s3.clear()
print('清空所有元素, s3={}'.format(s3)) # 清空所有元素, s3=set()
s1.remove('a')
print('删除指定元素,s1={}'.format(s1)) # 删除指定元素,s1={1, 33, 'o', 'n', 12, 'ab', 'dd', 'cd', 'b', 'c'}
此外,还有专门的集合操作,包括求取两个集合的并集、交集
# 判断是否子集, issubset()
a = set('abc')
b = set('bc')
c = set('cd')
print('b是否a的子集:', b.issubset(a)) # b是否a的子集: True
print('c是否a的子集:', c.issubset(a)) # c是否a的子集: False
# 并集操作,union() 或者 |
print('a 和 c 的并集:', a.union(c)) # a 和 c 的并集: {'c', 'b', 'a', 'd'}
print('a 和 c 的并集:', a | c) # a 和 c 的并集: {'c', 'b', 'a', 'd'}
# 交集操作,intersection() 或者 &
print('a 和 c 的交集:', a.intersection(c)) # a 和 c 的交集: {'c'}
print('a 和 c 的交集:', a & c) # a 和 c 的交集: {'c'}
# 差集操作,difference() 或者 - ,即只存在一个集合的元素
print('只在a中的元素:', a.difference(c)) # 只在a中的元素:: {'b', 'a'}
print('只在a中的元素:', a - c) # 只在a中的元素:: {'b', 'a'}
# 对称差集, symmetric_difference() 或者 ^, 求取只存在其中一个集合的所有元素
print('对称差集:', a.symmetric_difference(c)) # 对称差集: {'a', 'd', 'b'}
print('对称差集:', a ^ c) # 对称差集: {'a', 'd', 'b'}
数据类型的转换
有时候我们需要对数据类型进行转换,比如列表变成字符串等,这种转换一般只需要将数据类型作为函数名即可。下面列举了这些转换函数:
-
int(x, [,base]):将 x 转换为整数,
base表示进制,默认是十进制 -
float(x):将 x 转换为一个浮点数
-
complex(x, [,imag]):创建一个复数,
imag表示虚部的数值,默认是0 -
str(x):将对象 x 转换为字符串
-
repr(x): 将对象 x 转换为表达式字符串
-
eval(str): 用来计算在字符串中的有效 Python 表达式,并返回一个对象
-
tuple(s): 将序列 s 转换为一个元组
-
list(s): 将序列 s 转换为一个列表
-
set(s):转换为可变集合
-
dict(d): 创建一个字典。d 必须是一个序列 (key,value)元组
-
frozenset(s): 转换为不可变集合
-
chr(x):将一个整数转换为一个字符
-
ord(x):将一个字符转换为它的整数值
-
hex(x):将一个整数转换为一个十六进制字符串
-
oct(x):将一个整数转换为一个八进制字符串
3. 条件语句和迭代循环
1. 条件语句
Python 的条件语句就是通过一条或者多条语句的执行结果(判断 True 或者 False)来决定执行的代码块。
整体上可以分为四种语句:
- if 语句
- if-else 语句
- if-elif-else 语句
- 嵌套语句(多个 if 语句)
if 语句
给定一个二元条件,满足条件执行语句 A,不满足就跳过,代码例子如下:
a = 3
# if 语句
if a > 0:
print('a =', a)
if-else 语句
同样是给定二元条件,满足条件执行语句 A,不满足执行语句 B,代码例子如下:
a = 3
# if-else
if a > 2:
print('a is ', a)
else:
print('a is less 2')
if-elif-else 语句
给定多元条件,满足条件1,执行语句1,满足条件2,执行语句2,依次类推,简单的代码例子如下:
a = 3
# if-elif-else
if a > 5:
print('a>5')
elif a > 3:
print('a>3')
else:
print('a<=3')
嵌套语句
嵌套语句中可以包含更多的 if 语句,或者是 if-else 、if-elif-else 的语句,简单的代码例子如下所示:
a = 3
# 嵌套语句
if a < 0:
print('a<0')
else:
if a > 3:
print('a>3')
else:
print('0<a<=3')
2. 迭代循环
Python 中的循环语句主要是两种,while 循环和 for 循环,然后并没有 do-while 循环。
while 循环
一个简单的 while 循环如下,while 循环的终止条件就是 while 后面的语句不满足,即为 False 的时候,下面的代码例子中就是当 n=0 的时候,会退出循环。
n = 3
while n > 0:
print(n)
n -= 1
另一个例子,用于输入的时候让用户不断输入内容,直到满足某个条件后,退出。
promt = "\ninput something, and repeat it."
promt += "\nEnter 'q' to end the program.\n"
message = ""
while message != 'q':
message = input(promt)
print(message)
for 循环
for 循环可以显式定义循环的次数,并且通常经常用于列表、字典等的遍历。一个简单的例子如下:
# for
l1 = [i for i in range(3)]
for v in l1:
print(v)
上述例子其实用了两次 for 循环,第一次是用于列表推导式生成列表 l1 ,并且就是采用 range 函数,指定循环次数是 3 次,第二次就是用于遍历列表。
对于 range 函数,还有以下几种用法:
l2 = ['a', 'b', 'c', 'dd', 'nm']
# 指定区间
for i in range(2, 5):
print(i)
# 指定区间,并加入步长为 10
for j in range(10, 30, 10):
print(j)
# 结合 len 来遍历列表
for i in range(len(l2)):
print('{}: {}'.format(i, l2[i]))
另外,对于列表的循环,有时候希望同时打印当前元素的数值和索引值,可以采用 enumerate 函数,一个坚定例子如下:
l2 = ['a', 'b', 'c', 'dd', 'nm']
for i, v in enumerate(l2):
print('{}: {}'.format(i, v))
break 和 continue 以及循环语句中的 else 语句
break 语句用于终止循环语句,例子如下:
# break
for a in range(5):
if a == 3:
break
print(a)
这里就是如果 a = 3 ,就会终止 for 循环语句。
continue 用于跳过当前一次的循环,进入下一次的循环,例子如下:
# continue
for a in range(5):
if a == 3:
continue
print(a)
循环语句可以有 else 子句,它在穷尽列表(以 for 循环)或条件变为 false (以 while 循环)导致循环终止时被执行,但循环被 break 终止时不执行。例子如下:
# else
for a in range(5):
print(a)
else:
print('finish!')
4. 函数
定义:函数是组织好的,可重复使用,用于实现单一或者相关联功能的代码段。
在 Python 中既有内建函数,比如 print()、sum() ,也可以用户自定义函数。
4.1 定义函数
自定义一个函数需要遵守一些规则:
- 函数代码块必须以 def 关键词开头,然后是函数标识符名称(函数名)和圆括号 ();
- 圆括号内部用于定义参数,并且传入参数和自变量也是存放在圆括号内;
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
-
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的
return语句相当于返回None。
一个函数的一般格式如下:
def 函数名(参数列表):
函数体
默认情况下,参数值和参数名称是按照函数声明中定义的顺序匹配的。
简单的定义和调用函数的例子如下所示:
def hello():
print("Hello, world!")
# 计算面积的函数
def area(width, height):
return width * height
hello()
width = 2
height = 3
print('width={}, height={}, area={}'.format(width, height, area(width, height)))
输出结果:
Hello, world!
width=2, height=3, area=6
上述例子定义了两个函数,第一个是没有参数的 hello(), 而第二个函数定义了两个参数。
4.2 参数传递
在 python 中,类型属于对象,变量是没有类型的:
a = [1, 2, 3]
a = "abc"
上述代码中,[1,2,3] 是 List 类型,"abc" 是 String 类型,但变量 a 是没有类型的,它仅仅是一个对象的引用(一个指针),可以指向 List 类型,也可以指向 String 类型。
可更改(mutable)与不可更改(immutable)对象
python 中,strings, tuples, numbers 是不可更改对象,而 list, dict 是可修改的对象。
-
不可变类型:上述例子中
a先赋值为 5,然后赋值为 10,实际上是生成一个新对象,赋值为 10,然后让a指向它,并且抛弃了 5,并非改变了a的数值; -
可变类型:对于
list类型,变量la=[1,2,3],然后令la[2]=5,此时并没有改变变量la,仅仅改变了其内部的数值。
在之前的第二节介绍变量类型中,介绍了如何判断数据类型是否可变,介绍了两种方法:
- id()
- hash()
这里用 id() 的方法来做一个简单的例子,代码如下:
# 判断类型是否可变
a = 5
print('a id:{}, val={}'.format(id(a), a))
a = 3
print('a id:{}, val={}'.format(id(a), a))
la = [1, 2, 3]
print('la id:{}, val={}'.format(id(la), la))
la[2] = 5
print('la id:{}, val={}'.format(id(la), la))
输出结果,可以发现变量 a 的 id 是发生了变化,而列表变量 la 的 id 没有变化,这证明了 a 的类型 int 是不可变的,而 list 是可变类型。
a id:1831338608, val=5
a id:1831338544, val=3
la id:1805167229448, val=[1, 2, 3]
la id:1805167229448, val=[1, 2, 5]
然后在 Python 中进行函数参数传递的时候,根据传递的变量是否可变,也需要分开讨论:
-
不可变类型:类似
c++的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在fun(a)内部修改a的值,只是修改另一个复制的对象,不会影响a本身。 -
可变类型:类似
c++的**引用传递,**如 列表,字典。如fun(la),则是将la真正的传过去,修改后fun外部的la也会受影响。
当然了,Python 中一切都是对象,这里应该说是传递可变对象和不可变对象,而不是引用传递和值传递,但必须注意应该慎重选择传递可变对象的参数,下面会分别给出传递两种对象的例子。
首先是传递不可变对象的实例:
# 传递不可变对象的实例
def change_int(a):
a = 10
b = 2
print('origin b=', b)
change_int(b)
print('after call function change_int(), b=', b)
输出结果,传递的变量 b 并没有发生改变。
origin b= 2
after call function change_int(), b= 2
接着,传递可变对象的例子:
# 传递可变对象的实例
def chang_list(la):
"""
修改传入的列表参数
:param la:
:return:
"""
la.append([2, 3])
print('函数内部: ', la)
return
la = [10, 30]
print('调用函数前, la=', la)
chang_list(la)
print('函数外取值, la=', la)
输出结果,可以看到在函数内部修改列表后,也会影响在函数外部的变量的数值。
调用函数前, la= [10, 30]
函数内部: [10, 30, [2, 3]]
函数外取值, la= [10, 30, [2, 3]]
当然,这里如果依然希望传递列表给函数,但又不希望修改列表本来的数值,可以采用传递列表的副本给函数,这样函数的修改只会影响副本而不会影响原件,最简单实现就是切片 [:] ,例子如下:
# 不修改 lb 数值的办法,传递副本
lb = [13, 21]
print('调用函数前, lb=', lb)
chang_list(lb[:])
print('传递 la 的副本给函数 change_list, lb=', lb)
输出结果:
调用函数前, lb= [13, 21]
函数内部: [13, 21, [2, 3]]
传递 lb 的副本给函数 change_list, lb= [13, 21]
4.3 参数类型
参数的类型主要分为以下四种类型:
- 位置参数
- 默认参数
- 可变参数
- 关键字参数
- 命名关键字参数
位置参数
**位置参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。**其定义如下,arg 就是位置参数,docstring 是函数的说明,一般说明函数作用,每个参数的含义和类型,返回类型等;statement 表示函数内容。
def function_name(arg):
"""docstring"""
statement
下面是一个例子,包括一个正确调用例子,和两个错误示例
# 位置参数
def print_str(str1, n):
"""
打印输入的字符串 n 次
:param str1: 打印的字符串内容
:param n: 打印的次数
:return:
"""
for i in range(n):
print(str1)
strs = 'python '
n = 3
# 正确调用
print_str(strs, n)
# 错误例子1
print_str()
# 错误例子2
print_str(n, strs)
对于正确例子,输出:
python python python
错误例子1--print_str(),也就是没有传入任何参数,返回错误:
TypeError: print_str() missing 2 required positional arguments: 'str1' and 'n'
错误例子1--print_str(n, strs),也就是传递参数顺序错误,返回错误:
TypeError: 'str' object cannot be interpreted as an integer
默认参数
默认参数定义如下,其中 arg2 就是表示默认参数,它是在定义函数的时候事先赋予一个默认数值,调用函数的时候可以不需要传值给默认参数。
def function_name(arg1, arg2=v):
"""docstring"""
statement
代码例子如下:
# 默认参数
def print_info(name, age=18):
'''
打印信息
:param name:
:param age:
:return:
'''
print('name: ', name)
print('age: ', age)
print_info('jack')
print_info('robin', age=30)
输出结果:
name: jack
age: 18
name: robin
age: 30
注意:默认参数必须放在位置参数的后面,否则程序会报错。
可变参数
可变参数定义如下,其中 arg3 就是表示可变参数,顾名思义就是输入参数的数量可以是从 0 到任意多个,它们会自动组装为元组。
def function_name(arg1, arg2=v, *arg3):
"""docstring"""
statement
这里是一个使用可变参数的实例,代码如下:
# 可变参数
def print_info2(name, age=18, height=178, *args):
'''
打印信息函数2
:param name:
:param age:
:param args:
:return:
'''
print('name: ', name)
print('age: ', age)
print('height: ', height)
print(args)
for language in args:
print('language: ', language)
print_info2('robin', 20, 180, 'c', 'javascript')
languages = ('python', 'java', 'c++', 'go', 'php')
print_info2('jack', 30, 175, *languages)
输出结果:
name: robin
age: 20
height: 180
('c', 'javascript')
language: c
language: javascript
name: jack
age: 30
height: 175
('python', 'java', 'c++', 'go', 'php')
language: python
language: java
language: c++
language: go
language: php
这里需要注意几点:
- 首先如果要使用可变参数,那么传递参数的时候,默认参数应该如上述例子传递,不能如
print_info2('robin', age=20, height=180, 'c', 'javascript'),这种带有参数名字的传递是会出错的; - 可变参数有两种形式传递:
-
直接传入函数,如上述例子第一种形式,即
print_info2('robin', 20, 180, 'c', 'javascript'); - 先组装为列表或者元组,再传入,并且必须带有
*,即类似func(*[1, 2,3])或者func(*(1,2,3)),之所以必须带*,是因为如果没有带这个,传入的可变参数会多嵌套一层元组,即(1,2,3)变为((1,2,3))
关键字参数
关键字参数定义如下,其中 arg4 就是表示关键字参数,关键字参数其实和可变参数类似,也是可以传入 0 个到任意多个,不同的是会自动组装为一个字典,并且是参数前 ** 符号。
def function_name(arg1, arg2=v, *arg3, **arg4):
"""docstring"""
statement
一个实例如下:
def print_info3(name, age=18, height=178, *args, **kwargs):
'''
打印信息函数3,带有关键字参数
:param name:
:param age:
:param height:
:param args:
:param kwargs:
:return:
'''
print('name: ', name)
print('age: ', age)
print('height: ', height)
for language in args:
print('language: ', language)
print('keyword: ', kwargs)
# 不传入关键字参数的情况
print_info3('robin', 20, 180, 'c', 'javascript')
输出结果如下:
name: robin
age: 20
height: 180
language: c
language: javascript
keyword: {}
传入任意数量关键字参数的情况:
# 传入任意关键字参数
print_info3('robin', 20, 180, 'c', 'javascript', birth='2000/02/02')
print_info3('robin', 20, 180, 'c', 'javascript', birth='2000/02/02', weight=125)
结果如下:
name: robin
age: 20
height: 180
language: c
language: javascript
keyword: {'birth': '2000/02/02'}
name: robin
age: 20
height: 180
language: c
language: javascript
keyword: {'birth': '2000/02/02', 'weight': 125}
第二种传递关键字参数方法--字典:
# 用字典传入关键字参数
keys = {'birth': '2000/02/02', 'weight': 125, 'province': 'Beijing'}
print_info3('robin', 20, 180, 'c', 'javascript', **keys)
输出结果:
name: robin
age: 20
height: 180
language: c
language: javascript
keyword: {'birth': '2000/02/02', 'province': 'Beijing', 'weight': 125}
所以,同样和可变参数相似,也是两种传递方式:
- 直接传入,例如
func(birth='2012') - 先将参数组装为一个字典,再传入函数中,如
func(**{'birth': '2000/02/02', 'weight': 125, 'province': 'Beijing'})
命名关键字参数
命名关键字参数定义如下,其中 *, nkw 表示的就是命名关键字参数,它是用户想要输入的关键字参数名称,定义方式就是在 nkw 前面添加 *, ,这个参数的作用主要是限制调用者可以传递的参数名。
def function_name(arg1, arg2=v, *arg3, *,nkw, **arg4):
"""docstring"""
statement
一个实例如下:
# 命名关键字参数
def print_info4(name, age=18, height=178, *, weight, **kwargs):
'''
打印信息函数4,加入命名关键字参数
:param name:
:param age:
:param height:
:param weight:
:param kwargs:
:return:
'''
print('name: ', name)
print('age: ', age)
print('height: ', height)
print('keyword: ', kwargs)
print('weight: ', weight)
print_info4('robin', 20, 180, birth='2000/02/02', weight=125)
输出结果如下:
name: robin
age: 20
height: 180
keyword: {'birth': '2000/02/02'}
weight: 125
这里需要注意:
- 加入命名关键字参数后,就不能加入可变参数了;
- 对于命名关键字参数,传递时候必须指明该关键字参数名字,否则可能就被当做其他的参数。
参数组合
通过上述的介绍,Python 的函数参数分为 5 种,位置参数、默认参数、可变参数、关键字参数以及命名关键字参数,而介绍命名关键字参数的时候,可以知道它和可变参数是互斥的,是不能同时出现的,因此这些参数可以支持以下两种组合及其子集组合:
- 位置参数、默认参数、可变参数和关键字参数
- 位置参数、默认参数、关键字参数以及命名关键字参数
一般情况下,其实只需要位置参数和默认参数即可,通常并不需要过多的组合参数,否则函数会很难懂。
4.4 匿名函数
上述介绍的函数都属于同一种函数,即用 def 关键字开头的正规函数,Python 还有另一种类型的函数,用 lambda 关键字开头的匿名函数。
它的定义如下,首先是关键字 lambda ,接着是函数参数 argument_list,其参数类型和正规函数可用的一样,位置参数、默认参数、关键字参数等,然后是冒号 :,最后是函数表达式 expression ,也就是函数实现的功能部分。
lambda argument_list: expression
一个实例如下:
# 匿名函数
sum = lambda x, y: x + y
print('sum(1,3)=', sum(1, 3))
输出结果:
sum(1,3)= 4
4.5 变量作用域
Python 中变量是有作用域的,它决定了哪部分程序可以访问哪个特定的变量,作用域也相当于是变量的访问权限,一共有四种作用域,分别是:
- L(Local):局部作用域
- E(Enclosing):闭包函数外的函数中
- G(Global):全局作用域
- B(Built-in):内置作用域(内置函数所在模块的范围)
寻找的规则是 L->E->G->B ,也就是优先在局部寻找,然后是局部外的局部(比如闭包),接着再去全局,最后才是内置中寻找。
下面是简单介绍这几个作用域的例子,除内置作用域:
g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
# 闭包函数 inner()
def inner():
i_count = 2 # 局部作用域
内置作用域是通过一个名为 builtin 的标准模块来实现的,但这个变量名本身没有放入内置作用域,需要导入这个文件才可以使用它,使用代码如下,可以查看预定义了哪些变量:
import builtins
print(dir(builtins))
输出的预定义变量如下:
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
注意:只有模块(module),类(class)以及函数(def, lambda)才会引入新的作用域,其他代码块(比如 if/elif/else、try/except、for/while)是不会引入新的作用域,在这些代码块内定义的变量,外部也可以使用。
下面是两个例子,一个在函数中新定义变量,另一个在 if 语句定义的变量,在外部分别调用的结果:
g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
# 闭包函数 inner()
def inner():
i_count = 2 # 局部作用域
if 1:
sa = 2
else:
sa = 3
print('sa=', sa)
print('o_count=', o_count)
输出结果,对于在 if 语句定义的变量 sa 是可以正常访问的,但是函数中定义的变量 o_count 会报命名错误 NameError ,提示该变量没有定义。
sa= 2
NameError: name 'o_count' is not defined
全局变量和局部变量
全局变量和局部变量的区别主要在于定义的位置是在函数内部还是外部,也就是在函数内部定义的是局部变量,在函数外部定义的是全局变量。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
# 局部变量和全局变量
total = 3 # 全局变量
def sum_nums(arg1, arg2):
total = arg1 + arg2 # total在这里是局部变量.
print("函数内是局部变量 : ", total)
return total
# 调用 sum_nums 函数
sum_nums(10, 20)
print("函数外是全局变量 : ", total)
输出结果:
函数内是局部变量 : 30
函数外是全局变量 : 3
global 和 nonlocal 关键字
如果在内部作用域想修改外部作用域的变量,比如函数内部修改一个全局变量,那就需要用到关键字 global 和 nonlocal 。
这是一个修改全局变量的例子:
# 函数内部修改全局变量
a = 1
def print_a():
global a
print('全局变量 a=', a)
a = 3
print('修改全局变量 a=', a)
print_a()
print('调用函数 print_a() 后, a=', a)
输出结果:
全局变量 a= 1
修改全局变量 a= 3
调用函数 print_a() 后, a= 3
而如果需要修改嵌套作用域,也就是闭包作用域,外部并非全局作用域,则需要用关键字 nonlocal ,例子如下:
# 修改闭包作用域中的变量
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print('闭包函数中 num=', num)
inner()
print('调用函数 inner() 后, num=',num)
outer()
输出结果:
闭包函数中 num= 100
调用函数 inner() 后, num= 100
4.6 从模块中导入函数
一般我们会需要导入一些标准库的函数,比如 os、sys ,也有时候是自己写好的一个代码文件,需要在另一个代码文件中导入使用,导入的方式有以下几种形式:
# 导入整个模块
import module_name
# 然后调用特定函数
module_name.func1()
# 导入特定函数
from module_name import func1, func2
# 采用 as 给函数或者模块指定别名
import module_name as mn
from module_name import func1 as f1
# * 表示导入模块中所有函数
from module_name import *
上述几种形式都是按照实际需求来使用,但最后一种方式并不推荐,原因主要是 Python 中可能存在很多相同名称的变量和函数,这种方式可能会覆盖相同名称的变量和函数。最好的导入方式还是导入特定的函数,或者就是导入整个模块,然后用句点表示法调用函数,即 module_name.func1() 。
本节的代码例子:https://github.com/ccc013/Python_Notes/blob/master/Practise/function_example.py