Yunchao He
![]()
![]()
Yunchao He
The same problem here. Looking forward to get the reply.
Oh my God. I have trained on the multi-GPU version for one week with all of my four GPUs. In the `params/flowavenet/` dir, only one checkpoint was generated. Thanks for...
For example, from [Baidu TTS online demo](https://ai.baidu.com/tech/speech/tts), it can be found from the spectrogram the audio is enhanced apparently by a post-processing tech to reduce the noise.  [Baidu-TTS-sample.zip](https://github.com/mozilla/LPCNet/files/2904729/Baidu-TTS.zip)
@tsungruihon I think the LPCNet (train on your own dataset) is better than Griffin Lim both on quality and speed, especially when some post-processing algorithm could be applied.
I think a better way to solve this problem is to wrap the torch.stft with `autocast(enabled=off)` inside the mel_spectrogram_torch function. Here is the code: ``` def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate,...
How about your training data speed?
My results have a good (maybe) spectrogram, but the content is bad. Anyone knows why? 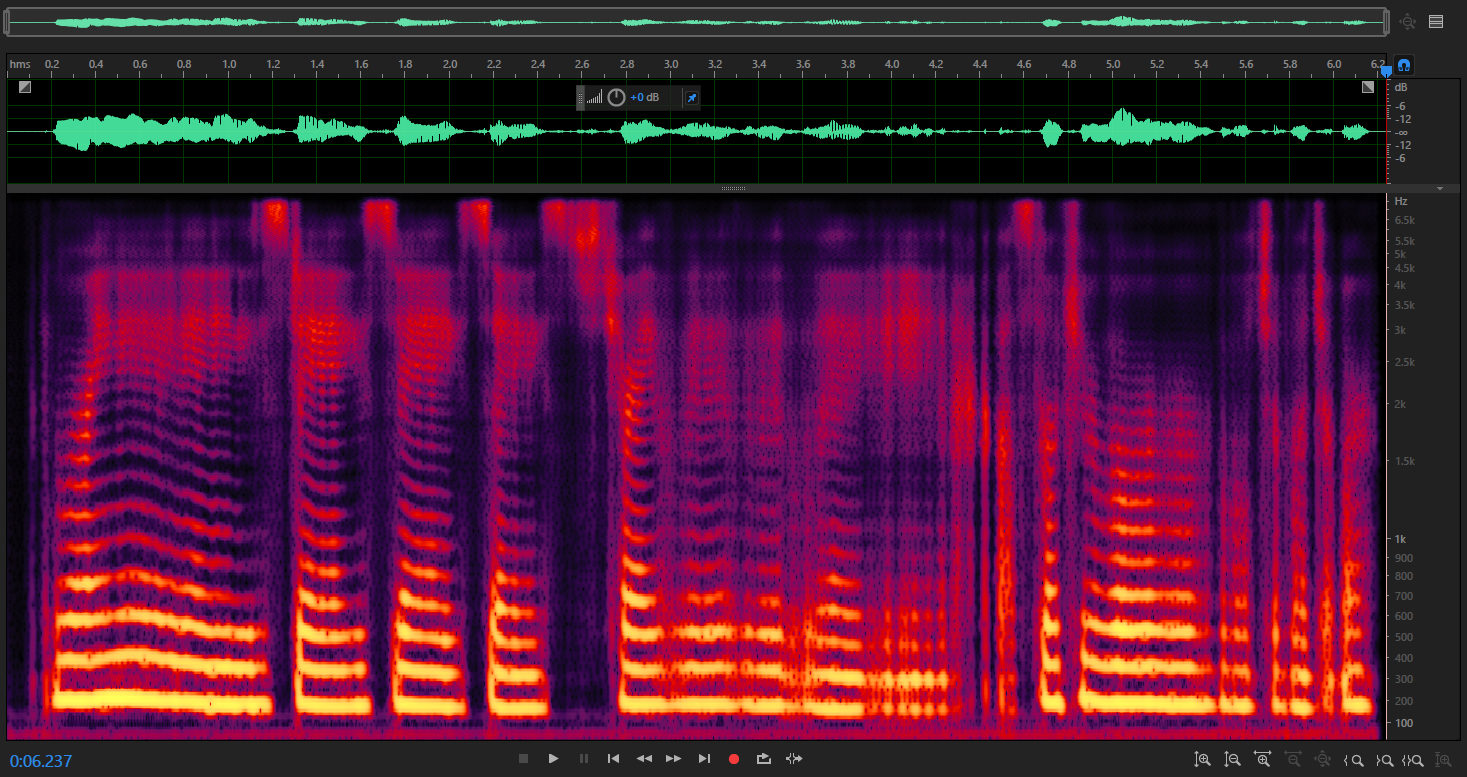 More: https://cnbj1.fds.api.xiaomi.com/tts/tts/result/20170627/samples.zip
Yes, I think your understanding is right. There should be no prenet in post-processing. Some days ago, I pulled a requests to remove it, https://github.com/Kyubyong/tacotron/pull/52 But as the dimension is...
@Kyubyong Yes, it is true that the table 1 from the original paper shows that, the second Conv1D projections layer is `conv-3-128-Linear`. And the paper also mentions that _batch-norm is...