LaTeXML
 LaTeXML copied to clipboard
LaTeXML copied to clipboard
Performance with large mathematical tables
Bruce and I had discussed in the first half of 2021 that certain documents in arXiv are not what we traditionally think of as "articles", or even "manuscripts", but are closer to "reference resources". In modern words, one could say they are "data structures pretending to be articles".
Sadly, latexml can be exceedingly inefficient with handling large documents with tens of thousands of formulas, even when it successfully parses all of them. This issue is meant to brainstorm and head towards improvements that will make it possible to convert such reference resources in under an hour.
Here is a motivating example: arXiv:quant-ph/0504002, which contains over 20,000 math formulas. How is that possible? A screenshot explains:

So, we are talking about a document which is mostly a single table, spanning 200 pages, with a handful of near-identical formulas per row.
Running with the regular arXiv setup and latexmlc, I terminated the conversion after 120 minutes (2 hours), in the Scan post-processing phase. Before it even got to the math post-processors. I certainly wish we could take the full run to HTML down to 30 minutes in this example, at least in the mid-term future.
An obvious path on a modern machine would be to do some of the phases in parallel. Scan, in particular, is very tempting to imagine as a parallel process.
Math parsing would be greatly sped up if run in parallel as well. That ought to be possible too, as the phase is entirely after the TeX phase is over, and we are working on a standalone XML input. But one would have to make sure the top-level parsing entry point is self-contained and doesn't modify the tree outside of the formula node it is provided.
In any case, I know that Bruce had asked me to send him a document of this nature if I stumbled on one, so here it is! Until we figure this out, it will remain a "timeout Fatal" in the arXiv conversion runs.
To defer opening yet another issue related to performance in math parsing, I found a valuable example from arXiv today, where a single formula can take upto an hour to get parsed.
The content in question is the minimal:
\documentclass{article}
\begin{document}
$\big\langle|n\rangle\langle n| a^\dagger_1 a^\dagger_2 a_3 a_4 \big\rangle= \big(\big\langle|n\rangle\langle n| a^\dagger_1 a_4 \big\rangle \big\langle|n\rangle\langle n| a^\dagger_2 a_3\big\rangle- \big\langle|n\rangle\langle n|a^\dagger_1 a_3 \big\rangle \big\langle|n\rangle\langle n| a^\dagger_2 a_4\big\rangle\big)/p_n$
\end{document}
Rendered in PDF:
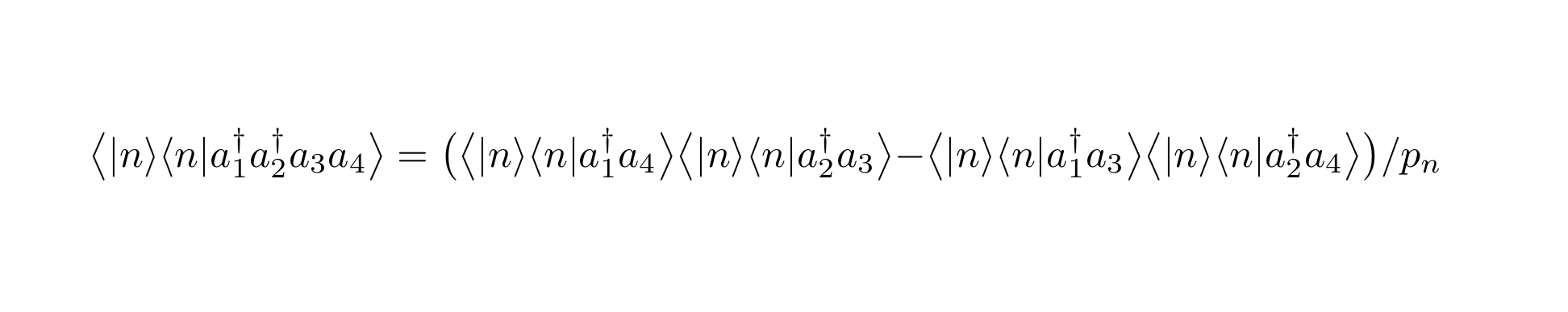
Update: I waited and got the exact runtime of time latexmlc on this mini document. It's just under 2 hours, which I find incredible:
real 118m6.537s
user 117m57.370s
sys 0m2.951s
I trimmed the formula to about half the size, and then mathparser can finish in about ~30 seconds. But the entire expression times out even with the 45 minute timeout I use in arXiv. So there likely is a good optimization possible.
The full article from where this originated is arXiv:0904.3454
Possibly related, another formula that takes seemingly forever to parse (causing a timeout), from arXiv:2401.15968
\documentclass{article}
\begin{document}
\begin{equation}
n_1(t+1) = n_1(t)\, \biggl [ \alpha\, f_1(t) + \biggl (1-\alpha\, f_1(t)\biggl )\biggl (\frac{q}{2}+ (1-q)\, f_1(t) \biggl ) \biggl ] + (N-n_1(t)) \bigl (1-\alpha(1-f_1(t))\bigl) \biggl(\frac{q}{2}+(1-q)f_1(t) \biggl ) \ .
\end{equation}
\end{document}
Note the somewhat sinister use of exclusively \biggl, without ever balancing it with \biggr.