pyret-lang
 pyret-lang copied to clipboard
pyret-lang copied to clipboard
confusing new scope
[This is based on a transcript of seeing a student struggle through several iterations of such code.]
t = table: a, b
row: 1, 2
row: 3, 4
end
fun f(col):
sieve t using col:
x == 2
end
end
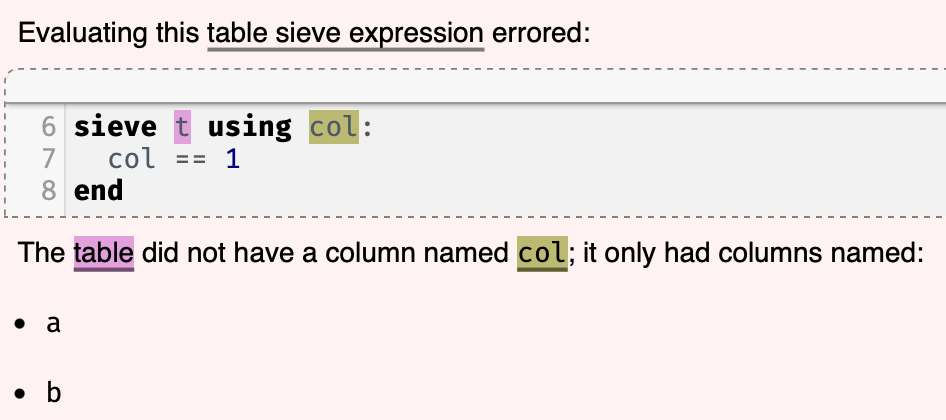
This produces the error

pointing to the col in the sieve line. It's not at all clear that that is introducing a new declaration. To a reader, it looks like it's trying to use an existing declaration.
Thanks for reporting!
What should change? The syntax? The error message? The “that” and “it” in the last two sentences are vague. I'm not sure I believe that different syntax would solve use-vs-def confusions here, given that learning use-vs-def is a learning outcome related to any syntax we'd choose.
Maybe the error message could say more, though. It would be nice if a shadowed variable in a sieve that isn't a column name were reported specially. That's technically super challenging due to when the compiler/runtime know about column names, but it's an improvement I could imagine.
It's not clear to me what the program is intended to do – it looks like it's intended to parameterize over column name (f("a") vs. f("b")).
Correct, the program is actually buggy. It's trying to use col as a variable, not realizing it's actually a constant name.
Speculation: I have wondered if table column names should not be syntactically distinct but interchangeable w/ strings, sort of like symbols vs strings. E.g.,
sieve t using |col|is syntactically valid,sieve t using colis a syntax error becausecolis not written in table column name syntax.
A much nicer and more relevant error, I think, would have been
colis not the name of a column in …
which is the most key issue here. It would (hopefully) help the student realize that col is being treated literally, not as a variable. They might then seek help to understand sieve better.
Even I have some trouble with the current error message. I'm used to seeing this error when I bind the same variable name twice. But I don't really think of sieve as a binding form. I understand that it is (and presumably desugars that way), but I had to do a double-take and think for a little while before I realized why it binds. Certainly, the binding error was far less salient than the "bad column name" error.
More importantly, presenting this as a binding error doesn't help me really fix the problem. Should I rename one of the cols? If the student "alpha"-renames, they're going to be right back here, over and over. Only if they blindly changed one name and not the other might they get to a useful error (like the unbound x in the body, etc.). There is an eventual path where they can get to the "true" (relative to sieve's semantics) error. It's too many steps away, though when it does show up, the error message is fantastic:
It's frustrating how hard it is to do the column error statically.
We could specialize shadowing errors in query binding positions, and do something like this:
"Is "col" the name of a column in the table? If it is, you may need to rename the variable or use shadow col. If not, sieve requires that all names listed after using are the names of columns in t"
I got back and forth on the table-operations syntax quite a bit. With a bare identifier in the using ... position, I can't decide whether I want to read it as a binding position, or as an expression position...and then the implicit binding within the body of the table-operation block is super magical. I think conflating symbols and strings here (as in your speculation comment) is a bad idea, though, because it makes it even harder to tell when something is a binder and when something is an expression. This was some of my unease with the table-operations syntax when we introduced it: it's "punning" col into two distinct roles...
Joe's comment is spot on: shadowing errors are static; detecting that there is no column in t with the literal name col is dynamic, so we cannot produce the second error message you mention.
Strawman proposal: at the risk of introducing more keywords (and more typing verbosity), could we do something like this?
# this is the current semantics: it dynamically selects column named `col` and binds it to the variable `col`,
sieve t using cols col: ... end
# means the same as
t.sieve(lam(r): let col = r.["col"] in ... end)
=============
# proposed: this dynamically selects the column with name equal to the string value of the variable `col`, and binds it to the variable `c`,
sieve t using named-cols col as c: ... end
# means
t.sieve(lam(r): let c = r.[col] in ... end)
I'm adding the keywords cols and named-cols, so that there's an up-front visual distinction between the two binding forms.
I realized, after writing, why my desired error would be hard/impossible.
One thing I've realized is that in general, we need better naming standards. There's a triad of things that are closely related, especially when you use build-column:
- the name of the new column
- the name of the function that will be used to generate that column
- the name of the table that will be created as a result of adding that column
I've seen students invent all sorts of ad hoc notions for these. I've discussed with @kfisler that it would be better to standardize some kind of convention for these (e.g.: for new column C, make-C and with-C).
That's not directly related to this situation, of course. But it would have helped with the long sequence of edits the student made before replacing all their code with a sieve. So there may be other ways to avoid this sort of situation from even occurring. (Using sieve before you get to functions is still very valuable. Once you get to functions, perhaps it is a bit dangerous because of this sort of situation, and we should switch to functions. That requires us making sure we get the names right. Etc.)