The retransmission of a confirmed uplink message is treated as an error.
-
[x] The issue is present in the latest release.
-
[x] I have searched the issues of this repository and believe that this is not a duplicate.
What happened?
The retransmission of a confirmed uplink message from LoRaWAN device is treated as an error called "frame-counter did not increment". I believe that ACK should be returned for retransmission as well.
What did you expect?
Fix this problem, please.
Steps to reproduce this issue
Steps:
Could you share your log output?
I used "Netvox R718A" as a LoRaWAN device.
== device log == [ { "type": "error", "payload": { "applicationID": "1", "applicationName": "ABP_TEST", "deviceName": "netvox1", "devEUI": "ABN6EAAAJwo=", "type": "UPLINK_FCNT_RETRANSMISSION", "error": "frame-counter did not increment", "fCnt": 7887, "tags": {} } }, { "type": "error", "payload": { "applicationID": "1", "applicationName": "ABP_TEST", "deviceName": "netvox1", "devEUI": "ABN6EAAAJwo=", "type": "UPLINK_FCNT_RETRANSMISSION", "error": "frame-counter did not increment", "fCnt": 7887, "tags": {} } }, { "type": "up", "payload": { "applicationID": "1", "applicationName": "ABP_TEST", "deviceName": "netvox1", "devEUI": "ABN6EAAAJwo=", "rxInfo": [], "txInfo": { "frequency": 923200000, "modulation": "LORA", "loRaModulationInfo": { "bandwidth": 125, "spreadingFactor": 10, "codeRate": "4/5", "polarizationInversion": false } }, "adr": true, "dr": 2, "fCnt": 7887, "fPort": 6, "data": "AQsBJAnIFJ8AAAA=", "objectJSON": "", "tags": {}, "confirmedUplink": true, "devAddr": "AAAnCg==" } } ]
== gateway log == [ { "uplinkMetaData": { "rxInfo": [ { "gatewayID": "AACAApwMCo0=", "time": null, "timeSinceGPSEpoch": null, "rssi": -30, "loRaSNR": 9.8, "channel": 3, "rfChain": 0, "board": 0, "antenna": 0, "location": { "latitude": 0, "longitude": 0, "altitude": 0, "source": "UNKNOWN", "accuracy": 0 }, "fineTimestampType": "NONE", "context": "RiMttA==", "uplinkID": "56KdqakmSDK2WKQXnrD8fg==", "crcStatus": "CRC_OK" } ], "txInfo": { "frequency": 923400000, "modulation": "LORA", "loRaModulationInfo": { "bandwidth": 125, "spreadingFactor": 10, "codeRate": "4/5", "polarizationInversion": false } } }, "phyPayload": { "mhdr": { "mType": "ConfirmedDataUp", "major": "LoRaWANR1" }, "macPayload": { "fhdr": { "devAddr": "0000270a", "fCtrl": { "adr": true, "adrAckReq": false, "ack": false, "fPending": false, "classB": false }, "fCnt": 7889, "fOpts": null }, "fPort": 6, "frmPayload": [ { "bytes": "2Ms/XTioP57LdBQ=" } ] }, "mic": "35f9709f" } }, { "uplinkMetaData": { "rxInfo": [ { "gatewayID": "AACAApwMCo0=", "time": null, "timeSinceGPSEpoch": null, "rssi": -30, "loRaSNR": 9.3, "channel": 3, "rfChain": 0, "board": 0, "antenna": 0, "location": { "latitude": 0, "longitude": 0, "altitude": 0, "source": "UNKNOWN", "accuracy": 0 }, "fineTimestampType": "NONE", "context": "Rda6DA==", "uplinkID": "yBruPV2VQ0u/llx5pen2Qw==", "crcStatus": "CRC_OK" } ], "txInfo": { "frequency": 923400000, "modulation": "LORA", "loRaModulationInfo": { "bandwidth": 125, "spreadingFactor": 10, "codeRate": "4/5", "polarizationInversion": false } } }, "phyPayload": { "mhdr": { "mType": "ConfirmedDataUp", "major": "LoRaWANR1" }, "macPayload": { "fhdr": { "devAddr": "0000270a", "fCtrl": { "adr": true, "adrAckReq": false, "ack": false, "fPending": false, "classB": false }, "fCnt": 7889, "fOpts": null }, "fPort": 6, "frmPayload": [ { "bytes": "2Ms/XTioP57LdBQ=" } ] }, "mic": "35f9709f" } }, { "downlinkMetaData": { "gatewayID": "000080029c0c0a8d", "txInfo": { "frequency": 923200000, "power": 14, "modulation": "LORA", "loRaModulationInfo": { "bandwidth": 125, "spreadingFactor": 10, "codeRate": "4/5", "polarizationInversion": true }, "board": 0, "antenna": 0, "timing": "DELAY", "delayTimingInfo": { "delay": "1s" }, "context": "Rbn4RA==" } }, "phyPayload": { "mhdr": { "mType": "UnconfirmedDataDown", "major": "LoRaWANR1" }, "macPayload": { "fhdr": { "devAddr": "0000270a", "fCtrl": { "adr": true, "adrAckReq": false, "ack": true, "fPending": false, "classB": false }, "fCnt": 204, "fOpts": null }, "fPort": 0, "frmPayload": [ { "bytes": "7VEWxYOSFITrkb7h62AbXCWseD592/I=" } ] }, "mic": "014395b1" } }, { "uplinkMetaData": { "rxInfo": [ { "gatewayID": "AACAApwMCo0=", "time": null, "timeSinceGPSEpoch": null, "rssi": -29, "loRaSNR": 8.5, "channel": 2, "rfChain": 0, "board": 0, "antenna": 0, "location": { "latitude": 0, "longitude": 0, "altitude": 0, "source": "UNKNOWN", "accuracy": 0 }, "fineTimestampType": "NONE", "context": "Rbn4RA==", "uplinkID": "22631yo8Q8OH3NM4jYB54g==", "crcStatus": "CRC_OK" } ], "txInfo": { "frequency": 923200000, "modulation": "LORA", "loRaModulationInfo": { "bandwidth": 125, "spreadingFactor": 10, "codeRate": "4/5", "polarizationInversion": false } } }, "phyPayload": { "mhdr": { "mType": "ConfirmedDataUp", "major": "LoRaWANR1" }, "macPayload": { "fhdr": { "devAddr": "0000270a", "fCtrl": { "adr": true, "adrAckReq": false, "ack": false, "fPending": false, "classB": false }, "fCnt": 7889, "fOpts": null }, "fPort": 6, "frmPayload": [ { "bytes": "2Ms/XTioP57LdBQ=" } ] }, "mic": "35f9709f" } } ]
Your Environment
| Component | Version |
|---|---|
| Application Server | v3.12.2 |
| Network Server | v3.10.0 |
| Gateway Bridge | |
| Chirpstack API | |
| Geolocation | |
| Concentratord |
I believe that ACK should be returned for retransmission as well.
I believe it should not, at least not for LoRaWAN 1.0.x devices. In LoRaWAN 1.0.x there is no difference between a replay attack and a re-transmission. Therefore allowing this would mean it will be easy for an adversary to attack your network by re-transmitting confirmed uplinks. As this would require the NS to re-transmit the ACK, it would be easy to steal airtime. Even worse, an adversary could do the re-transmission using SF12, meaning more airtime is required to re-transmit the ACK. Note that most gateways are half-duplex, so this attack means that during the re-transmission of the ACKs, the gateway can't receive during the transmission.
Previously, the LoRaWAN 1.0.x standard was worded in a way that prohibited the network server from retransmitting acknowledgements. Now that LoRaWAN 1.0.4 allows the network server to retransmit the ACK up to nbtrans times, would your view on this matter change in any way?
@sp193 could you let me know which part of the 1.0.4 spec describes that the NS can re-transmit an ACK? Because I see also this:

I interpreted that part as meaning that we shall not retransmit a downlink frame (retransmission of data frames initiated from the network server). But we can still retransmit the acknowledgement for an uplink frame, but using a new frame counter value.
Let's consider the original clause in 1.0.3, which prohibits us from retransmitting the acknowledgement:
4.3.1.2 Message acknowledge bit and acknowledgement procedure (ACKin FCtrl)
...
Acknowledgements are only sent in response to the latest message received and are never retransmitted
Now in 1.0.4, that clause has been changed to:
4.3.1.2 Frame acknowledge bit and acknowledgment procedure (ACK in FCtrl)
...
Acknowledgments SHALL only be sent in response to the latest frame received and SHALL NOT be transmitted more than NbTrans times. The Network SHALL only send an acknowledgment in the Class A receive windows (RX1/RX2) of the confirmed uplink that requested it.
Imagine the following scenario:
- Uplink FCnt 20
- Downlink FCnt 10
- NbTrans is 3
- There are 3 application payloads in the device queue (queue is managed by the NS, the encryption is done by the AS, the downlink FCnt is one of the parameters)
- PL1 encrypted with FCnt 10
- PL2 encrypted with FCnt 11
- PL3 encrypted with FCnt 12
Then what happens:
- DEVICE: sends confirmed uplink with FCnt 20
- NS: sends ACK + PL1 with FCnt 10
- DEVICE / REPLAY-ATTACK: re-transmits FCnt 20
- NS: sends new ACK + PL2 with FCnt 11 (as it can not re-use the same downlink FCnt 10 and it can not re-transmit PL1 as it is encrypted with FCnt 10 as one of the encryption parameters)
- DEVICE / REPLAY-ATTACK: re-transmits FCnt 20
- NS: sends new ACK + PL3 with FCnt 12
As there is no difference between a re-transmit and replay-attack, this gives any adversary the power to drain your device queue. Assuming that after 2. your device did receive the ACK + PL1, a replay-attack could still pop the next 2 items from the device-queue.
An alternative is that the NS does re-transmit PL1 in step 4. and 6. but this means that the NS must send all the device-queue items back to the AS (as the AS has the application-session key) for re-encryption using new frame-counters. This is something that I will support (as in LoRaWAN 1.0.4 mac-commands have priority over application payloads), but this would give any adversary the power to constantly trigger a re-encryption of your device queues by performing replay-attacks.
Also, it will have the following effect:
- Confirmed uplink FCnt 20 / ACKed with FCnt 10 (received by device)
- 2x replay-attack FCnt 20 / ACKed with FCnt 11 and FCnt 12
- Confirmed uplink FCnt 21 / ACKed with FCnt 13 (received by device)
Now a replay-attack created artificial packet-loss as the downlink frame-counter jumped from 10 to 13.
I think the main issue is that the NS can not distinguish a re-transmission from a replay-attack with LoRaWAN 1.0.x (which has been fixed by LoRaWAN 1.1.x). Please let me know if you think there is a secure way to implement this.
I personally think your alternative flow would be more appropriate and I would have probably done the same: retransmissions of the acknowledgement would entail a new frame getting generated for the sole purpose of making another attempt at conveying the acknowledgement, without any application payload involved. Even if the network server's frame counter ends up getting increased through making retransmissions (whether caused by replays or not), I don't suppose it is necessarily a bad thing - since the device will still accept new frames that have a higher FCntDown. The specification limits the number of retransmissions that the device may request to nbtrans times, but older devices may not comply with this - so we probably need to use a different limit when dealing with LoRaWAN 1.0.3 and earlier.
I work on a proprietary network server. The encryption of the message was shifted to right before the frame is about to be sent, to allow additional MAC commands to be possibly inserted - given that MAC commands may be generated due to changes in the device state or configuration. To avoid having to encrypt, decrypt and re-encrypt the unsent messages to make adjustments, my message queue contains the components (FOpts, FRMPayload etc) of messages in plaintext, rather than pre-encrypted messages. I am not sure how useful this information will be for Chirpstack.
In my network server, consecutive retransmissions beyond a certain number by the device will be flagged as a replay attack, which I think looks rather ominous to the uninitiated. So I've been exploring the possibility of classifying it differently or even preventing the root cause (the acknowledgement getting lost). I've also been considering whether it's even necessarily a bad thing - since it has been starting to sound like security is just an utmost priority in LoRaWAN.
Thanks for your feedback @sp193!
The encryption of the message was shifted to right before the frame is about to be sent, to allow additional MAC commands to be possibly inserted
This would be ideal, but I don't think this would be possible in case of ChirpStack, because the ChirpStack Network Server does not have knowledge of the AppSKey, only the Application Server has this key. In older versions, it was exactly like this (and the NS would poll the AS after an uplink), but this was before Class-B and Class-C (in which case the ChirpStack Network Server is constantly looking in the queue for downlinks to forward to the gateways).
The specification limits the number of retransmissions that the device may request to nbtrans times, but older devices may not comply with this - so we probably need to use a different limit when dealing with LoRaWAN 1.0.3 and earlier.
If we decide to implement the alternative flow, then my suggestion would be to just enforce the NbTrans as limit, as it is specified for LoRaWAN 1.0.4 for all devices. We don't have control over how a devices behaves, but we can consider a re-transmission count > NbTrans as replay-attack and just drop it.
Personally I'm not yet convinced if the alternative flow is a good thing. Ideally an adversary should not have any power over the state of the device in the NS. With this flow, an adversary does get some "limited" power, namely incrementing the downlink frame-counter and triggering the re-encryption of application payloads.
While I would still need to implement this, note that LoRaWAN 1.1.x does provide the fix for this at the protocol level. The uplink channel is a property of the MIC generation. Since the re-transmission must be using a different channel, it will result into a different MIC for the same uplink frame-counter. This gives the NS the possibility to distinguish a re-transmission from a replay-attack.
Hello!
We have the same issue. Our end node devices was developed based on "LoRaWAN 1.0.3 Specification".
According to sections:

 and illustrated example:
and illustrated example:
 Such end device perform retransmissions of confirmed uplink with the same Frame Counter.
We found incorrect behavior of network server that not acknowledge correctly retransmitted uplink packets from end nodes:
Such end device perform retransmissions of confirmed uplink with the same Frame Counter.
We found incorrect behavior of network server that not acknowledge correctly retransmitted uplink packets from end nodes:
 Imagine situation of correct use LoRaWAN network without even any adversary with 100 end nodes (v1.0.3) that transmit confirmed uplink packets (1 packet per hour at fully random time inside hour for example).
Any random collision at the moment of transmitting acknowledge from Network Server to 1 of 100 end node cause situation of retransmissions uplink packets from this node.
We actually see that many of devices perform redundant transmissions too much times and reduce battery life. Obviously, this leads to catastrophic redundant use air time for transmit useless data.
At the Application layer of end node firmware was implemented protection by performing new OTAA procedure.
We also find that at “LoRaWAN® L2 1.0.4 Specification” end nodes must retransmit confirmed uplink packets with the same Frame Counter only up to NbTrans times (as correctly noted by @sp193 ):
Imagine situation of correct use LoRaWAN network without even any adversary with 100 end nodes (v1.0.3) that transmit confirmed uplink packets (1 packet per hour at fully random time inside hour for example).
Any random collision at the moment of transmitting acknowledge from Network Server to 1 of 100 end node cause situation of retransmissions uplink packets from this node.
We actually see that many of devices perform redundant transmissions too much times and reduce battery life. Obviously, this leads to catastrophic redundant use air time for transmit useless data.
At the Application layer of end node firmware was implemented protection by performing new OTAA procedure.
We also find that at “LoRaWAN® L2 1.0.4 Specification” end nodes must retransmit confirmed uplink packets with the same Frame Counter only up to NbTrans times (as correctly noted by @sp193 ):
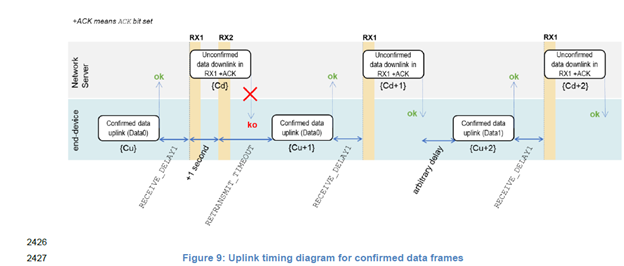 But support of 1.0.4 version of specification will added only at future versions of end node firmwares.
Now we found that Network server that discarding retransmitted uplink frames implement version 1.0.4 of LoRaWAN specification.
Is it will be honest to declare that Chirpstack does not correctly support 1.0.3 End Nodes?
But support of 1.0.4 version of specification will added only at future versions of end node firmwares.
Now we found that Network server that discarding retransmitted uplink frames implement version 1.0.4 of LoRaWAN specification.
Is it will be honest to declare that Chirpstack does not correctly support 1.0.3 End Nodes?
I was busy with various things, so I didn't write a response earlier. Anyway, for completeness, I would like to add on.
I don't think the existing behaviour is wrong for a LoRaWAN 1.0.3-compliant LNS. If we consider what the 1.0.3 standard says in 4.3.1.2 Message acknowledge bit and acknowledgement procedure (ACK in FCtrl):
Acknowledgements are only sent in response to the latest message received and are never retransmitted.
This same clause was updated in 1.0.4:
Acknowledgments SHALL only be sent in response to the latest frame received and SHALL NOT be transmitted more than NbTrans times
So while the original design is perhaps not so great, being strictly compliant with 1.0.3 and before would mean not resending acknowledgements.
On a side note, older devices not compliant with 1.0.4 may also end up retransmitting the confirmed uplink more than nbtrans times, as there was no such clause in 1.0.3 and earlier.