bottlerocket
 bottlerocket copied to clipboard
bottlerocket copied to clipboard
Bottlerocket boot performance appears to be bimodal
Platform I'm building on:
aws-k8s-1.25
I'm launching EC2 instances on m5.xlarge and recording the boot time using systemd-analyze.
What I expected to happen: I would expect for the boot time distribution to be a normal distribution, or possibly skewed right.
What actually happened:
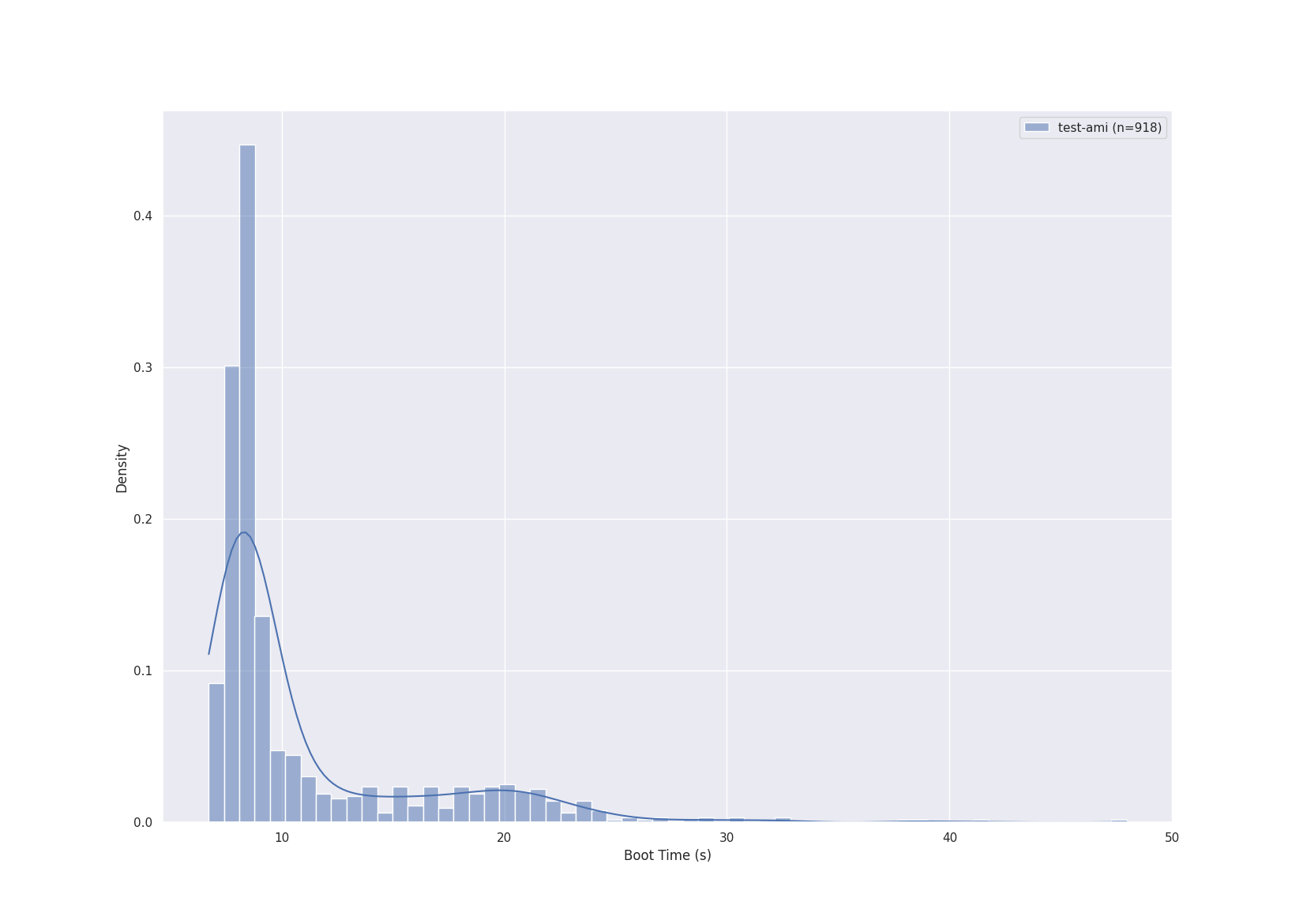
Data I've collected seems to indicate a bimodal distribution. This suggests that there may be some degraded mode of execution during the boot process in some situations.
This issue is to determine whether or not this distribution is due to flawed or undesirable behavior on Bottlerocket, or if this is just a circumstance of running in EC2.
Hmm, did you randomize instance types, regions, and Bottlerocket versions? Or did you use the same parameters in all your executions? The distribution is so weird if you didn't change the parameters at all :octocat:
It's the same parameters! My guess is there's some timeout pattern in Bottlerocket that should be changed, or we may be seeing variances in heterogeneous hardware in EC2.
It seems that in most cases that are in the second cohort it takes kubelet a very long time to start, anywhere between 6 and 15 seconds. Occasionally this is also coupled with high runtimes of sundog.service (~2 seconds), settings-applier.service (~2 seconds), and sometimes host-containerd.service (~2 seconds).
In a few examples that I investigated, it seemed that kubelet would be started but then not emit logs for an extended period of time after the pause container seemed to have completed being pulled (up to 10 seconds). I notice that the system is typically attempting to cache the pause container and the bottlerocket-control container simultaneously, and kubelet requires the pause container to be cached before starting.
One theory: long image pull of the pause container image contributes to a slow start for kubelet. This could possibly be due to network hiccups, resource contention while the bottlerocket-control container is pulled, degraded IO performance on the disk, or any other number of reasons.
Some possible solutions I'm looking at right now:
- I noticed containerd emitting a message about the lack of available pigz. Funnily enough, #2896 was also just opened about the same issue (thanks, @ohkinozomu!). This could help.
- It might be prudent to delay pulling host containers until after the orchestrator has successfully started.
- Getting finer-grain resource utilization metrics with e.g. systemd-bootchart could help illuminate what the blocking resource is here. I have a fork with a start at building this for Bottlerocket, but have been tripped up by what appears to be misbehaving build scripts.
If time to pull is an issue, the recent release of containerd 1.7.0 has improved pull performance through the use of minio/sha256-simd. https://github.com/containerd/containerd/pull/7732 It may help.
Honestly, issues like this and this should a part of an automatic test suite and never even make it into a release. For a general purpose distro fast startup may be "nice to have", but for the one focused on running containers it is a core feature.