rerope
 rerope copied to clipboard
rerope copied to clipboard
Rectified Rotary Position Embeddings
Rectified Rotary Position Embeddings (ReRoPE)
Using ReRoPE, we can more effectively extend the context length of LLM without the need for fine-tuning.
Blog
- https://kexue.fm/archives/9706 (Chinese)
- https://kexue.fm/archives/9708 (Chinese)
- https://normxu.github.io/Rethinking-Rotary-Position-Embedding-2/ (English by @NormXU)
- https://normxu.github.io/Rethinking-Rotary-Position-Embedding-3/ (English by @NormXU)
Idea
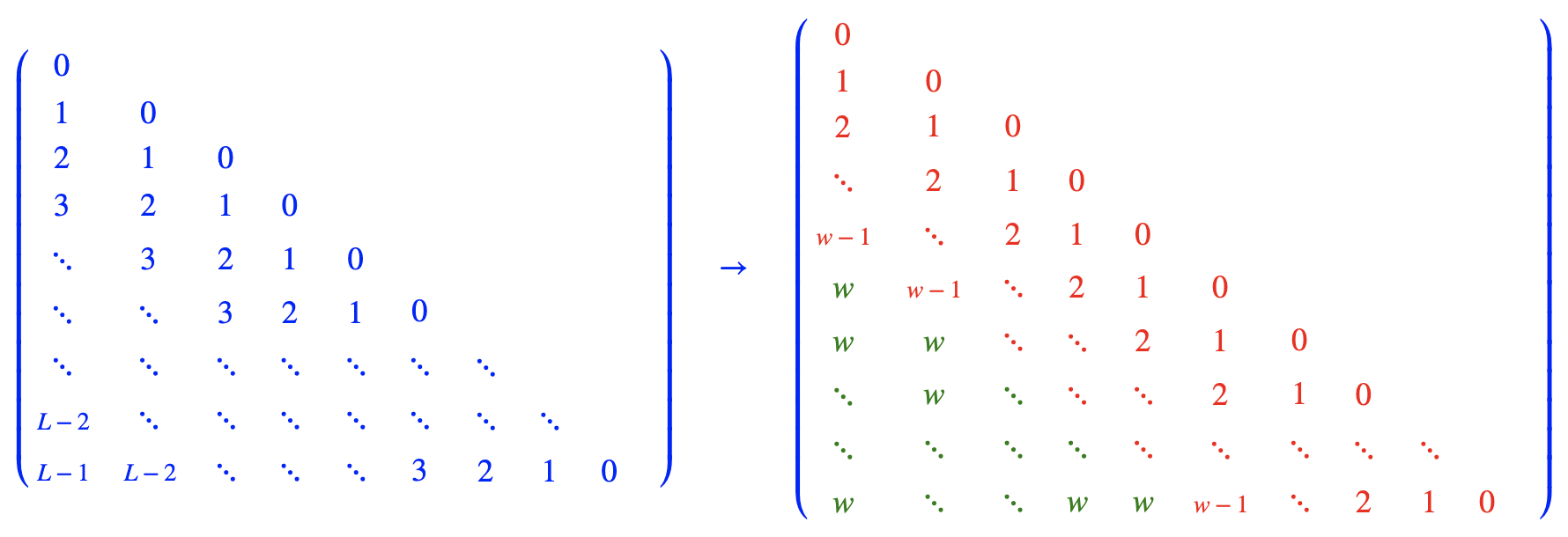
Results
Calculated the loss on llama2-13b with samples_15k.jsonl:
| Method | loss |
|---|---|
| RoPE-4k(original llama2-13b) | 1.4967 |
| RoPE-8k(original llama2-13b) | 8.8615 |
| NTK-RoPE-4k(not dynamic) | 1.6081 |
| NTK-RoPE-8k(not dynamic) | 1.5417 |
| NTK-RoPE-16k(not dynamic) | 1.5163 |
| ReRoPE-w1024-4k | 1.4996 |
| ReRoPE-w1024-8k | 1.4267 |
| ReRoPE-w1024-16k | 1.4001 |
ReRoPE's performance at training length (4k) has hardly decreased, and it possesses the ideal property of "longer context, lower loss".
Usage
Dependency: transformers 4.31.0
Run python test.py to test chatting or run python eval_loss.py to calculate loss with llama2.
From here and here, we can see what modifications ReRoPE/Leaky ReRoPE has made compared to the original llama implementation.
Other
Triton Implementation of ReRoPE: https://gist.github.com/chu-tianxiang/4307937fd94b49c75b61a6967716bae9
Cite
@misc{rerope2023,
title={Rectified Rotary Position Embeddings},
author={Jianlin Su},
year={2023},
howpublished={\url{https://github.com/bojone/rerope}},
}
Communication
QQ discussion group: 67729435, for WeChat group, please add the robot WeChat ID spaces_ac_cn