Test: Add checkpoint conversion test code
This PR addresses #114 to check that Megatron-DS to Hugging Face transformers works as intended.
ok, so the 2 LayerNorm implementations diverge a lot under fp16 (while very little under fp32)
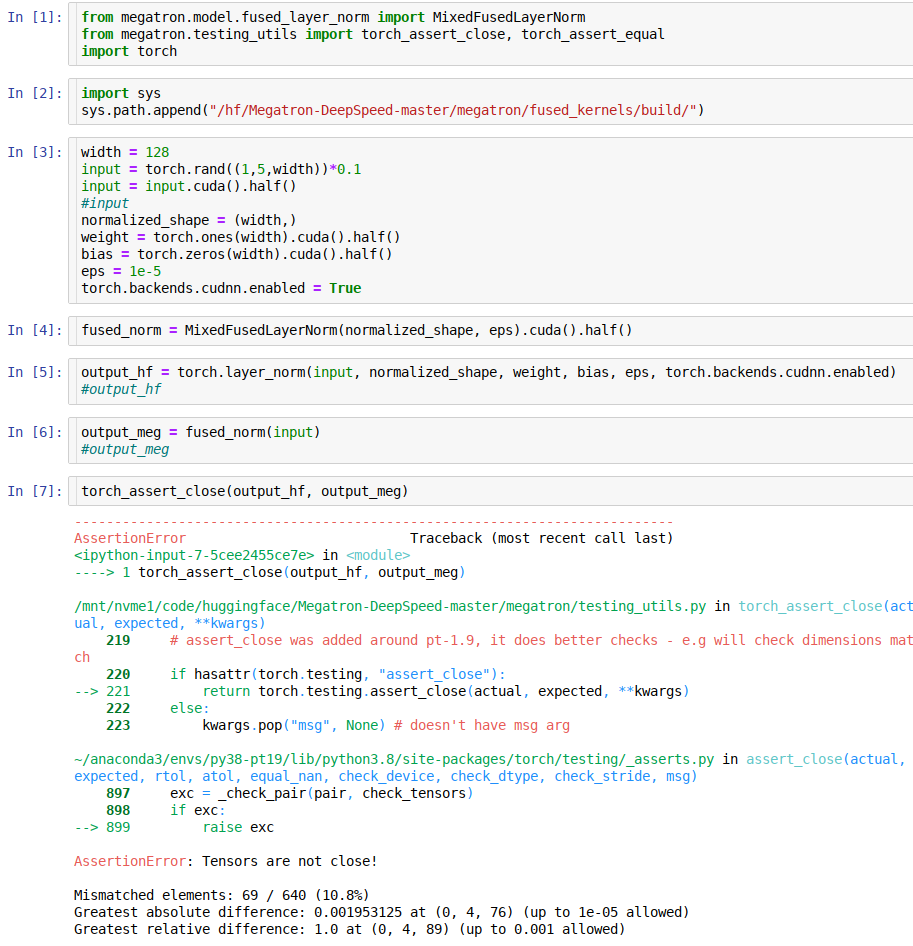
I have some outstanding changes to the test where I switched to using tokenizers to compare both sides for extra validation, but I will wait with those until we decide what to do about this issue.
To update on where we are at with the test:
- as I posted in the channel we need to clone
GPT2on the HF side to something likeGPTMeg(no name yet). - Then modify it to match Meg's outputs.
- Then we fix the conversion script to set this to a new arch
- The we use it in our test and it should just work
I create an Issue for someone to work on 1+2 https://github.com/bigscience-workshop/Megatron-DeepSpeed/issues/138
Update: @sIncerass cloned GPT2 to GPTMeg at https://github.com/huggingface/transformers/pull/14084
I will try now to integrate it into this test.
(I committed my wip which needs a lot of clean up which I will do once this is working, there is just a lot of debug code in there, just want to make sure it doesn't get lost)
Just to crosslink - here is a related work happening in pytorch core wrt layer_norm under fp16: https://github.com/pytorch/pytorch/pull/66920
At some point we ought to complete this line of work. Otherwise we can't release the 13B model.
The main question is whether we actually need 99.999% exactness and require a special HF transformers gpt2 arch variant. To answer this question we shouldn't compare logits but use some quality metrics instead.
For the prefix-lm and possible other additions like embed layer norm for the upcoming trainings, we will either have to add these features as configurable options in the existing HF transformers GPT2 model arch, or create a new arch.
What would completing this line of work entail? Evaluating the converted HF checkpoint on lm-eval-harness and making sure that resulting metrics are within reasonable bounds with that obtained from Meg-DS checkpoint?
We may have to wait until the experimental dust settles and see what new features we end up having in the models we trained at BigScience. If all these models absolutely require a new arch on the HF side perhaps it could be a single arch GPT2BigScience with all the different options enabled via model config, so not to interfere with the "normal" GPT2.
So one config option so far can be
- "megatron_mode" which enables all the fp16 mixed precision nuances we added to https://github.com/huggingface/transformers/pull/14084.
This mode is here to stay for 13B-ml and 200B trainings.
Then we might have the following features:
-
embed_norm -
PrefixLM -
pos_embed: rotary or alibi - activations:
GeGLU
So gpt2-13B-en config will have just (1) enabled.
Thank you for the clarification. So I assume this PR will get back on the pedestal once ongoing experiments are run to completion and we can derive meaningful conclusions to inform our decisions on the final architecture. Do you think it makes sense for me to start poking around the arch-config setup, or would it be more efficient to wait for the dust to settle down so to speak?