CaGNetv2-Zero-Shot-Semantic-Segmentation
 CaGNetv2-Zero-Shot-Semantic-Segmentation copied to clipboard
CaGNetv2-Zero-Shot-Semantic-Segmentation copied to clipboard
Code for "From Pixel to Patch: Synthesize Context-aware Features for Zero-shot Semantic Segmentation".
CaGNetv2: From Pixel to Patch (accpeted by TNNLS)
Code for "From Pixel to Patch: Synthesize Context-aware Features for Zero-shot Semantic Segmentation".
Created by Zhangxuan Gu, Siyuan Zhou, Li Niu*, Zihan Zhao, Liqing Zhang*.
Paper Link: [arXiv]
Note
This work is an extension of our previous CaGNet [arXiv, github].
Visualization on Pascal-VOC

Introduction
Zero-shot learning has been actively studied for image classification task to relieve the burden of annotating image labels. Interestingly, semantic segmentation task requires more labor-intensive pixel-wise annotation, but zero-shot semantic segmentation has only attracted limited research interest. Thus, we focus on zero-shot semantic segmentation, which aims to segment unseen objects with only category-level semantic representations provided for unseen categories. In this paper, we propose a novel Context-aware feature Generation Network (CaGNetv2), which can synthesize context-aware pixel-wise visual features for unseen categories based on category-level semantic representations and pixel-wise contextual information. The synthesized features are used to finetune the classifier to enable segmenting unseen objects. Furthermore, we extend pixel-wise feature generation and finetuning to patch-wise feature generation and finetuning, which additionally considers inter-pixel relationship. Experimental results on Pascal-VOC, Pascal-Context, and COCO-stuff show that our method significantly outperforms the existing zero-shot semantic segmentation methods.
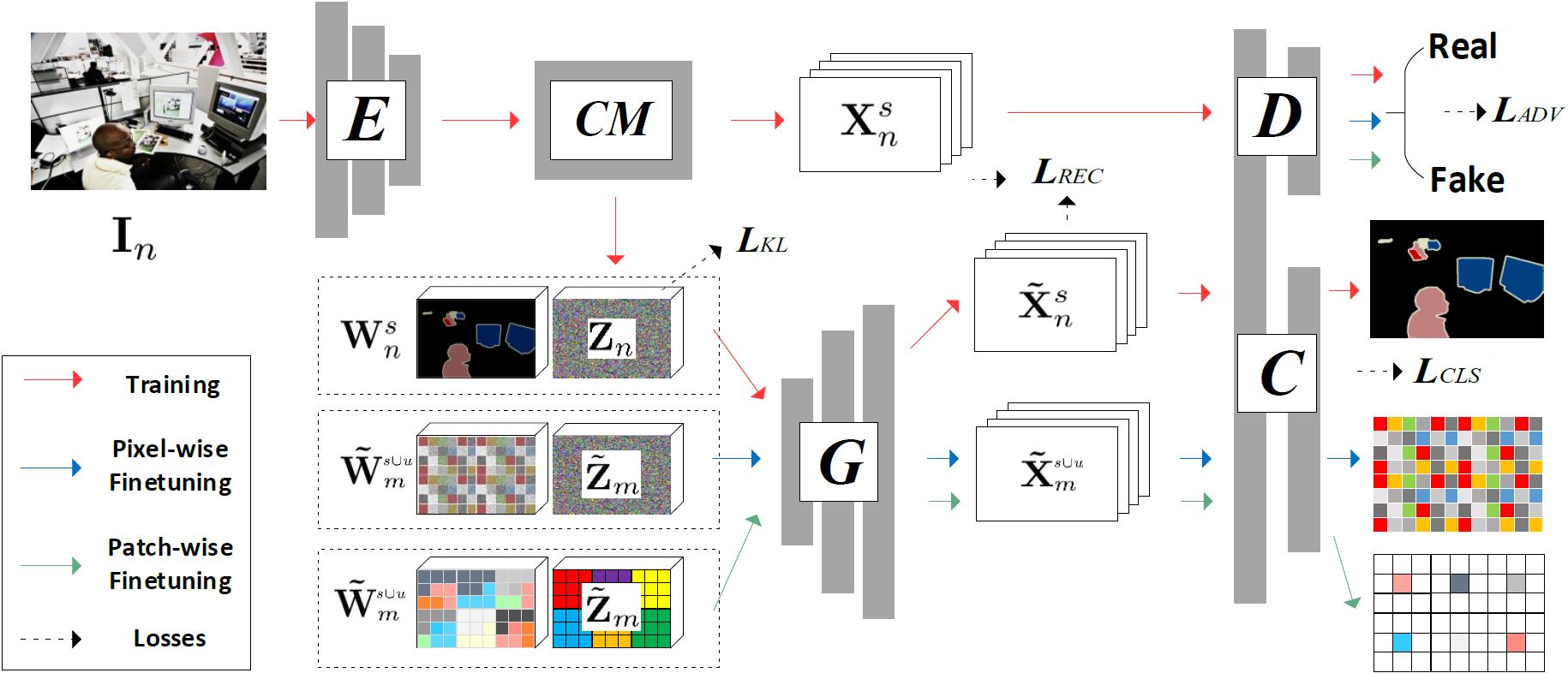
Experimental Results
We compare our CaGNetv2 with SPNet [github, paper] and ZS3Net [github, paper].
“ST” in the following tables stands for self-training mentioned in ZS3Net.
Our Results on Pascal-VOC dataset
| Method | hIoU | mIoU | PA | MA | S-mIoU | U-mIoU | U-PA | U-MA |
|---|---|---|---|---|---|---|---|---|
| SPNet | 0.0002 | 0.5687 | 0.7685 | 0.7093 | 0.7583 | 0.0001 | 0.0007 | 0.0001 |
| SPNet-c | 0.2610 | 0.6315 | 0.7755 | 0.7188 | 0.7800 | 0.1563 | 0.2955 | 0.2387 |
| ZS3Net | 0.2874 | 0.6164 | 0.7941 | 0.7349 | 0.7730 | 0.1765 | 0.2147 | 0.1580 |
| CaGNet(pi) | 0.3972 | 0.6545 | 0.8068 | 0.7636 | 0.7840 | 0.2659 | 0.4297 | 0.3940 |
| CaGNet(pa) | 0.4326 | 0.6623 | 0.8068 | 0.7643 | 0.7814 | 0.2990 | 0.5176 | 0.4710 |
| ZS3Net+ST | 0.3328 | 0.6302 | 0.8095 | 0.7382 | 0.7802 | 0.2115 | 0.3407 | 0.2637 |
| CaGNet(pi)+ST | 0.4366 | 0.6577 | 0.8164 | 0.7560 | 0.7859 | 0.3031 | 0.5855 | 0.5071 |
| CaGNet(pa)+ST | 0.4528 | 0.6657 | 0.8036 | 0.7650 | 0.7813 | 0.3188 | 0.5939 | 0.5417 |
Our Results on COCO-Stuff dataset
| Method | hIoU | mIoU | PA | MA | S-mIoU | U-mIoU | U-PA | U-MA |
|---|---|---|---|---|---|---|---|---|
| SPNet | 0.0140 | 0.3164 | 0.5132 | 0.4593 | 0.3461 | 0.0070 | 0.0171 | 0.0007 |
| SPNet-c | 0.1398 | 0.3278 | 0.5341 | 0.4363 | 0.3518 | 0.0873 | 0.2450 | 0.1614 |
| ZS3Net | 0.1495 | 0.3328 | 0.5467 | 0.4837 | 0.3466 | 0.0953 | 0.2275 | 0.2701 |
| CaGNet(pi) | 0.1819 | 0.3345 | 0.5658 | 0.4845 | 0.3549 | 0.1223 | 0.2545 | 0.2701 |
| CaGNet(pa) | 0.1984 | 0.3327 | 0.5632 | 0.4909 | 0.3468 | 0.1389 | 0.2962 | 0.3132 |
| ZS3Net+ST | 0.1620 | 0.3372 | 0.5631 | 0.4862 | 0.3489 | 0.1055 | 0.2488 | 0.2718 |
| CaGNet(pi)+ST | 0.1946 | 0.3372 | 0.5676 | 0.4854 | 0.3555 | 0.1340 | 0.2670 | 0.2728 |
| CaGNet(pa)+ST | 0.2269 | 0.3456 | 0.5711 | 0.4629 | 0.3617 | 0.1654 | 0.3702 | 0.2567 |
Our Results on Pascal-Context dataset
| Method | hIoU | mIoU | PA | MA | S-mIoU | U-mIoU | U-PA | U-MA |
|---|---|---|---|---|---|---|---|---|
| SPNet | 0 | 0.2938 | 0.5793 | 0.4486 | 0.3357 | 0 | 0 | 0 |
| SPNet-c | 0.0718 | 0.3079 | 0.5790 | 0.4488 | 0.3514 | 0.0400 | 0.1673 | 0.1361 |
| ZS3Net | 0.1246 | 0.3010 | 0.5710 | 0.4442 | 0.3304 | 0.0768 | 0.1922 | 0.1532 |
| CaGNet(pi) | 0.2061 | 0.3347 | 0.5975 | 0.4900 | 0.3610 | 0.1442 | 0.3976 | 0.3248 |
| CaGNet(pa) | 0.2135 | 0.3243 | 0.5816 | 0.5082 | 0.3718 | 0.1498 | 0.3981 | 0.3412 |
| ZS3Net+ST | 0.1488 | 0.3102 | 0.5842 | 0.4532 | 0.3398 | 0.0953 | 0.3030 | 0.1721 |
| CaGNet(pi)+ST | 0.2252 | 0.3352 | 0.5951 | 0.4962 | 0.3644 | 0.1630 | 0.4038 | 0.4214 |
| CaGNet(pa)+ST | 0.2478 | 0.3364 | 0.5832 | 0.4964 | 0.3482 | 0.1923 | 0.4075 | 0.4023 |
Please note that our reproduced results of SPNet on Pascal-VOC dataset are obtained using their released model and code with careful tuning, but still lower than their reported results.
Code
COMING SOON !