bazel-buildfarm
 bazel-buildfarm copied to clipboard
bazel-buildfarm copied to clipboard
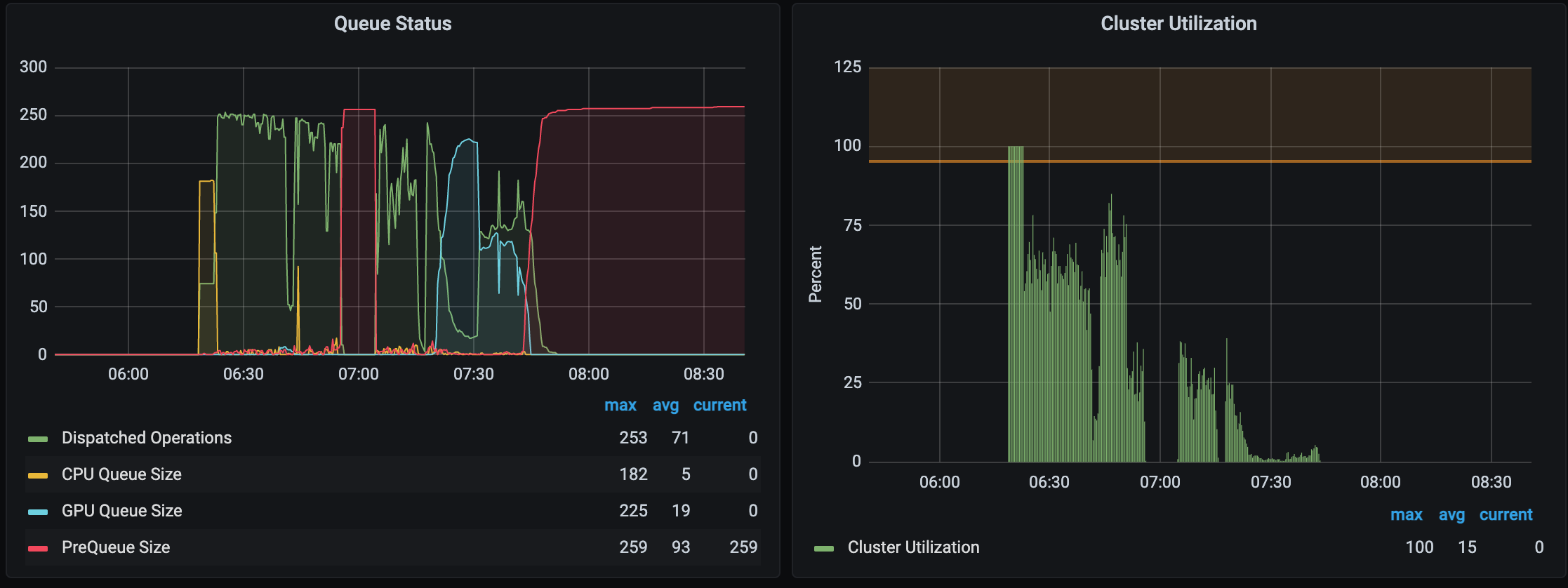
Builds hanging with prequeue runaway
There exists a case where a build will hang indefinitly with preque going up until it hits the maximum set. During this time, no executions are being performed.
Rebooting stuck server container immediatelly unlocks it and the executions resume.
[x / x] x / x tests; 261 actions running; last test: //x; 3688s remote
| x; 3688s remote
| Testing //.../x; 3688s remote
| .../x; 3688s remote
| Testing //.../x; 3688s remote
| ..._x; 3688s remote
| Testing //.../x; 3688s remote
| .../x; 3688s remote ...
Jstack output attached.
high_prequeue_jstack_bf_server.txt
high_prequeue_jstack_client.txt
I can replicate this fairly consistently. What I'm observing is that this happens when we lose one or more workers (but doesn't happen EVERY time we lose a worker). So I think there is a state where the worker lose causes a scheduler to get stuck. I do observe this happen more in our dev environment as it runs a long build with only a single scheduler, so when that scheduler locks up, the whole cluster is locked up until after the build is terminated.
https://github.com/werkt/bazel-buildfarm/tree/transform-token-timeout has the beginning of a failsafe for this condition.
The transform tokens are exhausted - we cannot put any more onto its fixed size queue for tracking outstanding movement from prequeue to queue:
"Thread-2" #65 [69] prio=5 os_prio=0 cpu=286868.45ms elapsed=72763.09s tid=0x00007fec91692500 nid=69 waiting on condition [0x00007febdca2c000]
java.lang.Thread.State: WAITING (parking)
at jdk.internal.misc.Unsafe.park([email protected]/Native Method)
- parking to wait for <0x00000000a01a3630> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park([email protected]/LockSupport.java:371)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionNode.block([email protected]/AbstractQueuedSynchronizer.java:506)
at java.util.concurrent.ForkJoinPool.unmanagedBlock([email protected]/ForkJoinPool.java:3744)
at java.util.concurrent.ForkJoinPool.managedBlock([email protected]/ForkJoinPool.java:3689)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await([email protected]/AbstractQueuedSynchronizer.java:1625)
at java.util.concurrent.LinkedBlockingQueue.put([email protected]/LinkedBlockingQueue.java:343)
at build.buildfarm.instance.shard.ShardInstance$1.run(ShardInstance.java:452)
at java.lang.Thread.run([email protected]/Thread.java:1589)
By switching this over from put to offer with a timeout, we get to observe a condition where a single transform cannot be added for a period of time that will hopefully indicate that the service is uniquely in the 'locked up' state, and will benefit from being terminated and restarted (the result of hitting that condition on the scheduler side).
This is the nuclear option for schedulers and at least prevents us from sitting forever with nothing being transformed. As to where these things are actually stuck, we will need to dig into with non-frame based observation of pending activity, since open grpc async requests do not sit with threads waiting on their results.