Whisper_auto2lrc
 Whisper_auto2lrc copied to clipboard
Whisper_auto2lrc copied to clipboard
Use Whisper to convert audio files into LRC subtitle files in bulk. 使用whisper实现将音频文件批量转换为lrc字幕文件
Whisper_auto2lrc
![]()



English | 中文
Whisper_auto2lrc is a tool that uses the whisper model and a Python program to convert all audio files in a folder (and its subfolders) into .lrc subtitle files. If an lrc subtitle file already exists, it will be automatically skipped.
Now integrated with Faster Whisper for faster inference and lower memory usage! (Approximately 4 times faster inference speed and half the memory requirement)
Recommended to use Faster Whisper
What can this program do?
It uses the whisper speech-to-text model released by OpenAI. Users can specify the audio file folder to be processed, and the program will automatically recursively search for all audio files in the folder and transcribe them into lrc format subtitle files.
It is suitable for users who need to transcribe a large number of audio files into subtitles.
Automatic translation will be added in the future.
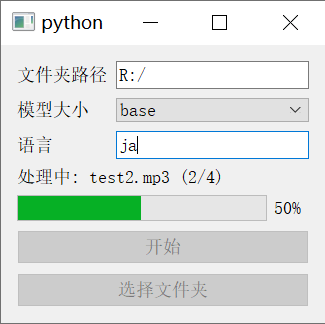
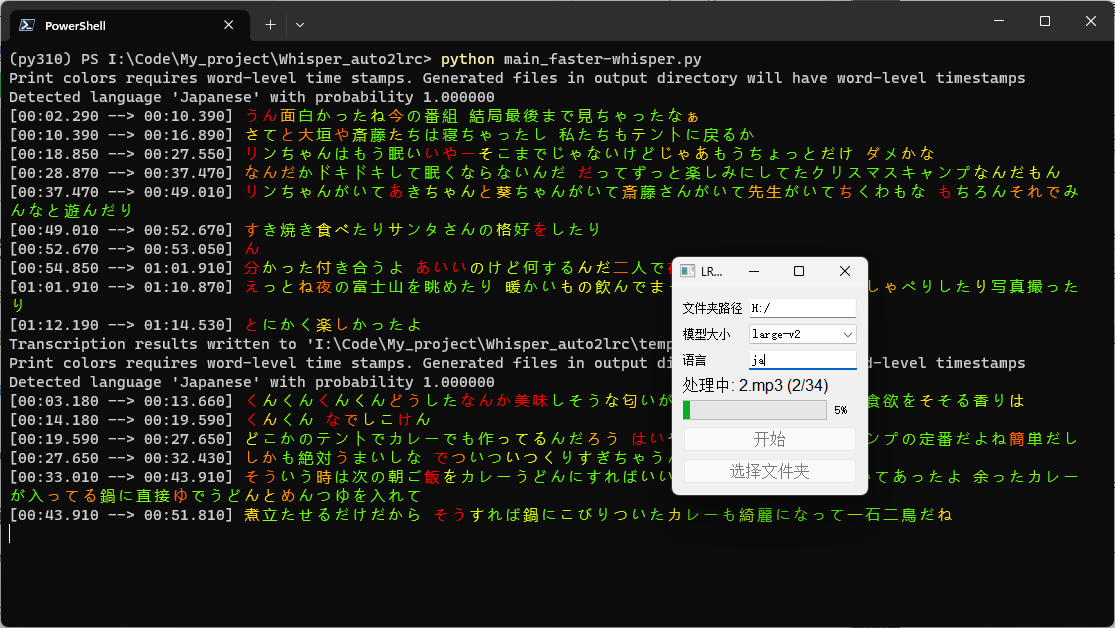
Screenshots
Using Faster Whisper
How to install
First, install Python, which has been tested on Python 3.10.11.
Then, install the Python dependencies required by whisper openai/whisper:
pip install git+https://github.com/openai/whisper.git
If you want to use Faster Whisper, you need to install the dependencies of the Faster Whisper command line version Softcatala/whisper-ctranslate2
pip install -U whisper-ctranslate2
How to use
Using the source code program
Pull this repo and install the Python dependencies:
git clone https://github.com/bai0012/Whisper_auto2lrc
cd Whisper_auto2lrc
pip install -r requirements.txt
With the terminal at the base of the project folder, run
python main.py
If you want to use Faster Whisper, run
python main_faster-whisper.py
(Faster Whisper has the Silero VAD filter turned on by default to skip blank audio segments over two seconds, and uses colors to indicate the confidence level of each character, with red indicating low confidence and green indicating high confidence)
In the window, select the folder path, choose the model size to use, enter the language of the audio files to be processed, and click start.
Troubleshooting
What's the difference between Faster Whisper and the original Whisper?
Faster-whisper is a reimplementation of OpenAI's Whisper model using CTranslate2, a fast inference engine for Transformer models.
This implementation is 4 times faster than openai/whisper, uses less memory and VRAM, and has the same accuracy.
According to guillaumekln/faster-whisper, the performance improvement of using the large-v2 model on NVIDIA Tesla V100S is shown in the following table:
| Implementation | Precision | Beam size | Time required | Maximum GPU memory required | Maximum memory required |
|---|---|---|---|---|---|
| openai/whisper | fp16 | 5 | 4m30s | 11325MB | 9439MB |
| faster-whisper | fp16 | 5 | 54s | 4755MB | 3244MB |
| faster-whisper | int8 | 5 | 59s | 3091MB | 3117MB |
Why is my Whisper only using the CPU?
Whisper can call GPUs that support CUDA. If you are sure that your GPU has been correctly installed and supports CUDA, try the following steps:
pip uninstall torch
pip cache purge
Then install the latest PyTorch using the command on the PyTorch official website
For example:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
You should be able to call the graphics card normally.
Why is ffmpeg giving an error when I use it?
You can try the following steps to reinstall ffmpeg:
pip uninstall ffmpeg
pip uninstall ffmpeg-python
pip install ffmpeg-python
Which model should I choose and what are the differences between each model?
Refer to openai/whisper
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
Choose the model based on the size of the VRAM on your GPU. Generally, the larger the model, the faster the speed and the lower the error rate.
(For example, if you have an RTX3060 12G, you can choose the large model, but if you have a GTX 1050ti 4G, you can only use the small model)
Faster Whisper uses the same models but requires less VRAM, so try it out for yourself.
(Faster Whisper can even run the large model on a 1050ti 4G, although it sometimes runs out of VRAM, so a 6G VRAM should be enough to run the large model)
What should I enter in the language input box?
Whisper supports speech-to-text in multiple languages, commonly used ones include:
| Language | Code |
|---|---|
| Chinese | zh |
| English | en |
| Russian | ru |
| Japanese | ja |
| Korean | ko |
| German | de |
| Italian | it |
For more languages, refer to: whisper/tokenizer.py
Star History
(This program was completed under the guidance of GPT 4)