Parsr
 Parsr copied to clipboard
Parsr copied to clipboard
Transforms PDF, Documents and Images into Enriched Structured Data

**Summary** When using param 'wait_till_finished' on ParsClient, error raised `--------------------------------------------------------------------------- NameError Traceback (most recent call last) in ----> 1 res = parsr.send_document( 2 file_path="BariatricSurgery.pdf", 3 config_path='defaultConfig.json', 4 document_name='The Readme', 5...
**Summary** Function `send_document` throws `NameError: name 'file' is not defined` in when `wait_till_finished=True` and `silent=False`. When `wait_till_finished=True` and `silent=True` it falls into an infinite loop instead. I can see, that...
Thanks for this amazing piece of software! Is there any way to delete processed documents? I just want to process documents, save the JSON and images, and delete the processed...
**Is your feature request related to a problem? Please describe.** To have more optional OCR engines makes the tool more flexible **Describe the solution you'd like** Add PaddleOCR engine as...
**Is your feature request related to a problem? Please describe.** The current table detector only works for text based PDFs **Describe the solution you'd like** Parsr will try to detect...
**Summary** Send a PDF using default config crash module Cleaner.js **Steps To Reproduce** 1. Send multipage PDF using curl 2. Check logs 3. See error ``` [2021-01-22T11:06:41] ERROR (parsr-api/6 on...
**Is your feature request related to a problem? Please describe.** I have a collection of PDFs with input fields, and the data from those fields is not extracted. **Describe the...
**Summary** Docker run returns *exec format error* **Steps To Reproduce** Steps to reproduce the behavior: 1. docker pull axarev/parsr 2. docker run -p 3001:3001 axarev/parsr **Expected behavior** Works without error...
**Summary** I have some pdf files that contains measurements (eye measurement, like astigmatism) The format would look like this: `K1: 46,11 D @ 153º` screnshot from the pdf: 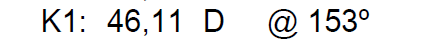 The...
**Summary** When using pdfminer with mupdf to extract image, the source of the image is never found. **Expected behavior** I expect to retrieve the source path of images (it works...