containers-roadmap
 containers-roadmap copied to clipboard
containers-roadmap copied to clipboard
[EKS] [NodeGroups] [request]: Node Groups take 30 minutes to rotate nodes without reason
Community Note
- Please vote on this issue by adding a 👍 reaction to the original issue to help the community and maintainers prioritize this request
- Please do not leave "+1" or "me too" comments, they generate extra noise for issue followers and do not help prioritize the request
- If you are interested in working on this issue or have submitted a pull request, please leave a comment
Tell us about your request
When we do any updates to Managed Node Group Templates, it's taking nearly 30 minutes to apply any change. For example, if you update tags on Node Group which involves changes to template and replacing instances (not sure why we need to replace instances if we add tags?) it will take around 25 to 30 minutes to replace those instances. This is a huge amount of time for such basic change. Another problem is that in my test cluster where I have just 2 nodes (development and testing) such change will create additional 4 nodes. Those nodes will be in place for around 30 minutes since that change takes so long time. This means during a simple update to tag names or values, we are paying for 4 additional instances without any reason.
Which service(s) is this request for?
EKS Node Groups
Tell us about the problem you're trying to solve. What are you trying to do, and why is it hard? The problem seems to be with bad or delayed communication between AWS and EKS Control Plane. I was looking at this issue some time ago with AWS Support and noticed that:
- We issue tag change or any other change which require update to template version
- EKS goes and tries to update Node Groups and replace nodes inside that Node Group
- During above process which takes around 30 minutes with 1 or 2 nodes I see no communication from AWS to EKS. Nodes are not being cordoned, nor any pods evicted or asking to be evicted. This would mean that there is an issue with Node Draining
- Usually after 20+ minutes all of a sudden we start seeing node draining process start
- Once drain is completed, instances are remove one by one from Auto Scaling Group
I was trying to use Node Termination Handler to help me with this issue. IMDS setup doesn't seem to do anything and other option will require creation of Event Bridge and other resources, which seems like an overkill for something that Node Group was meant to provide by default. I haven't yet tested Queue option so I'm not even sure if this works. I can only confirm that default IMDS option does nothing.
Are you currently working around this issue?
There is no way to solve this problem
Additional context Anything else we should know?
Attachments If you think you might have additional information that you'd like to include via an attachment, please do - we'll take a look. (Remember to remove any personally-identifiable information.)
Hi wojtekszpunar@,
Thanks for reaching out.
In the initial step of EKS Node Group upgrade process, replacement nodes are launched in every availability zone where the nodes are present in the node group. This is done to ensure the evicted stateful pods always get assigned to a node in the same availability zone. Since the existing nodes would drain only once the launch step succeeds, looks like it appears as a delay in drain process at your end.
Once the upgrade completes, additional instances are removed one at a time to safe-guard the workload. This process is also documented in our public doc.
Please let us know if you have any other questions.
Yes, I know this is by design, but I'm afraid this design is incorrect and causes our bill to grow substantially. You are saying that evicted stateful sets always get node, but what if I do not use them? Why do I need to get penalty of having unused nodes for 30 minutes, for which I have to pay without any reason if I do not have those?
The main problem isn't with the amount of nodes, but with the time it's taking to replace them. Take this example. I have 2 worker node cluster (development do not need more atm) and process of replacing nodes takes at best 30 minutes even tho I do not really have many applications and I do not have stateful sets.
Issue is that there is no drain signals being sent to nodes for very long time. I mean, I see the process of adding min 6 nodes (it's always happening, not sometimes like you say in your documentation) which takes around 5 - 6 minutes. Then nothing happens for like 20 minutes (no drain, no no-schedule annotations). After more or less 25 to 30 minutes all of a sudden pods are starting to be evicted and moved to new nodes.
In this case I have 2 or 3 worker node cluster and to update instances I require additional 6 nodes for 30 minutes. If I replace those daily or there is any change which requires update to LaunchTemplate change, my bill goes at least 30% up in a month without any reason. Not to mention during that window instances are running idle for around 20 min. Not to mention adding tag to instance will cause replacement of Nodes and in this case it can take anything in between 30 minutes to 1 hour. It's really looong time for such change, don't you think?
So if you have to spin up those nodes to cover edge cases, then OK. But edge case do not apply to all clusters, and it's not a rule. If you are able to fix communication in between EKS and ASG we can have this problem solved to certain degree. I mean, if we are able to send drain signal to nodes we replace straight after all of those planned 6 nodes are in healthy status in K8s this issue will be mitigated to certain degree.
One more thing to look at is that why nodes being added to cluster one at the time with 2 minutes in between them? If you know that you need 6 nodes, can you not just spin up all 6? Or at least 1 in each AZ node-group is configured to operate in?
Any updates on this? It takes 40 minutes to update 5 nodes and I end up with about 15 instances in the middle of the rolling update
Any updates on this? It takes 40 minutes to update 5 nodes and I end up with about 15 instances in the middle of the rolling update
I'm having similar issues with any kind of managed node group upgrade or launch template update etc etc... it often creates new nodes, then for some reason creates even more new nodes and deletes some of the nodes it just created. Very odd.
For the past year I've tested node groups with 1 and node groups with 3 availability zones. No difference. Also I have tested groups with 1 and up to tens of instances. Result is the same, over 40 minutes of tens of instances getting created and destroyed.
In this picture I'm updating a 1-node and a 2-node groups, both taking more than 40 minutes. I also tested setting the max_unavailable setting, now set to 3 with no improvement. I'll probably switch to karpenter at this point.

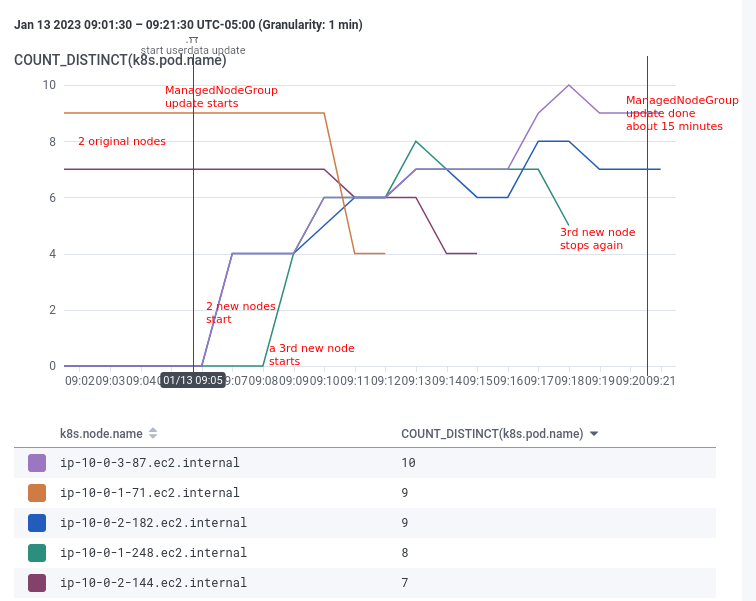
A ManagedNodeGroup update is taking about 15 minutes for me. The new nodes show as ready and start taking on pods within about 3 minutes. The thing that seems most out of place is that in my group of desired=2 max=4 nodes, a 3rd new node starts (for a total of 5 nodes running) and then is later terminated.
It does slow down development for it to take that long, and it's a little inconvenient/costly for an extra node to start and then go away, but overall not that big a deal for me. It would definitely be nice if there were an option for a less cautious, faster rollout.
With the lack of response from AWS on this.
I'm going with the conclusion "its by design, solely to incur those extra charges on customer bills."
For me the issue is mostly the time it takes and the fact that is seems stuck (sometimes it really gets stuck!). These kinds of updates can be stressful, the faster they're done, the faster all services can recover, the better for me. I've been using something like this for 2 years (!) now:
# The upgrade process of AWS managed node groups is bad, this lets Terraform handle everything
# https://github.com/aws/containers-roadmap/labels/EKS%20Managed%20Nodes
resource "random_id" "ng_name_suffix" {
keepers = {
lt_id = aws_launch_template.node_group.id
lt_version = aws_launch_template.node_group.latest_version # Some bugs on AWS's side require recreation when a new launch template version is created:
cluster_name = var.cluster_name
node_role_arn = var.node_role_arn
subnet_ids = join("|", var.subnet_ids)
instance_types = join("|", var.instance_types)
capacity_type = local.capacity_type
}
byte_length = 2
}
resource "aws_eks_node_group" "ng" {
node_group_name = "${var.name}-${random_id.ng_name_suffix.b64_url}"
# [...]
lifecycle {
create_before_destroy = true
}
}
It's a bit brutal since it kills all the nodes at the same time, but it works so much better that what AWS provides :(
For me the issue is mostly the time it takes and the fact that is seems stuck (sometimes it really gets stuck!). These kinds of updates can be stressful, the faster they're done, the faster all services can recover, the better for me. I've been using something like this for 2 years (!) now:
# The upgrade process of AWS managed node groups is bad, this lets Terraform handle everything # https://github.com/aws/containers-roadmap/labels/EKS%20Managed%20Nodes resource "random_id" "ng_name_suffix" { keepers = { lt_id = aws_launch_template.node_group.id lt_version = aws_launch_template.node_group.latest_version # Some bugs on AWS's side require recreation when a new launch template version is created: cluster_name = var.cluster_name node_role_arn = var.node_role_arn subnet_ids = join("|", var.subnet_ids) instance_types = join("|", var.instance_types) capacity_type = local.capacity_type } byte_length = 2 } resource "aws_eks_node_group" "ng" { node_group_name = "${var.name}-${random_id.ng_name_suffix.b64_url}" # [...] lifecycle { create_before_destroy = true } }It's a bit brutal since it kills all the nodes at the same time, but it works so much better that what AWS provides :(
Pretty sure this would create downtime in production...
Pretty sure this would create downtime in production...
Depending on your workload, yes.
More recently I needed to handle updates without disrupting some workloads, for that I have a python script that "decommisions" node groups (terraform rm + eks_clt.update_nodegroup_config([...], taints={...}) ).
I still think that the AWS way of disrupting workloads (creating new nodes) but very slowly is the worst of both worlds.
EDIT for the guy bellow: I meant replacing nodes, not creating
Pretty sure this would create downtime in production...
Depending on your workload, yes.
More recently I needed to handle updates without disrupting some workloads, for that I have a python script that "decommisions" node groups (
terraform rm+eks_clt.update_nodegroup_config([...], taints={...})).I still think that the AWS way of disrupting workloads (creating new nodes) but very slowly is the worst of both worlds.
How can creating new nodes disrupt your workloads?
For me the issue is mostly the time it takes and the fact that is seems stuck (sometimes it really gets stuck!). These kinds of updates can be stressful, the faster they're done, the faster all services can recover, the better for me. I've been using something like this for 2 years (!) now:
# The upgrade process of AWS managed node groups is bad, this lets Terraform handle everything # https://github.com/aws/containers-roadmap/labels/EKS%20Managed%20Nodes resource "random_id" "ng_name_suffix" { keepers = { lt_id = aws_launch_template.node_group.id lt_version = aws_launch_template.node_group.latest_version # Some bugs on AWS's side require recreation when a new launch template version is created: cluster_name = var.cluster_name node_role_arn = var.node_role_arn subnet_ids = join("|", var.subnet_ids) instance_types = join("|", var.instance_types) capacity_type = local.capacity_type } byte_length = 2 } resource "aws_eks_node_group" "ng" { node_group_name = "${var.name}-${random_id.ng_name_suffix.b64_url}" # [...] lifecycle { create_before_destroy = true } }It's a bit brutal since it kills all the nodes at the same time, but it works so much better that what AWS provides :(
Pretty sure this would create downtime in production...
Yeah it seems to me that because of the create_before destroy flag being set you have a guarantee that the new nodes will get provisioned before the old nodes get deprovisioned.
Yeah it seems to me that because of the create_before destroy flag being set you have a guarantee that the new nodes will get provisioned before the old nodes get deprovisioned.
But not before the pods have been moved to the new nodes. So when the first node group is destroyed, any podso that haven't migrated (probably most of them?) will be abruptly terminated and will start spinning up on the new nodes.
If your container images are small and initialize quickly, maybe you'll only have a few seconds of interruption. But if your containers are bloated with long initialization times, it could take many minutes to get the workload back up.
Maybe a pod disruption budget could compensate for that and prevent deletion of the old nodegroup?