containers-roadmap
 containers-roadmap copied to clipboard
containers-roadmap copied to clipboard
[EKS] [request]: Insufficient information when nodegroup upgrade fails
Community Note
- Please vote on this issue by adding a 👍 reaction to the original issue to help the community and maintainers prioritize this request
- Please do not leave "+1" or "me too" comments, they generate extra noise for issue followers and do not help prioritize the request
- If you are interested in working on this issue or have submitted a pull request, please leave a comment
Tell us about your request Currently the information returned to EKS is insufficient to act upon.
Which service(s) is this request for? EKS
Tell us about the problem you're trying to solve. What are you trying to do, and why is it hard?
The message below is from cloudformation but is the same for EKS.
ResourceStatusReason": "Update failed due to [{ErrorCode: PodEvictionFailure,ErrorMessage: Reached max retries while trying to evict pods from nodes in node group prod-nodegroup,ResourceIds: [ip-10-233-150-169.eu-west-1.compute.internal]}]",
It would be handy to know on which pod it's failing.
Are you currently working around this issue?
Additional context
Attachments
Thanks for the feedback, we'll include the pod name that failed to be evicted
@mikestef9 I'm sorry to do it this way, but this is really becoming an issue. I have inconsistent failing production upgrades, and I have no idea why. I can reproduce the issue in non-production but because it's inconsistent and I can't access any logs I'm a bit out of options. If I do a manual drain of each node it's fine, i've contacted AWS support but when they took a look it did go fine. Can this please be given more priority?
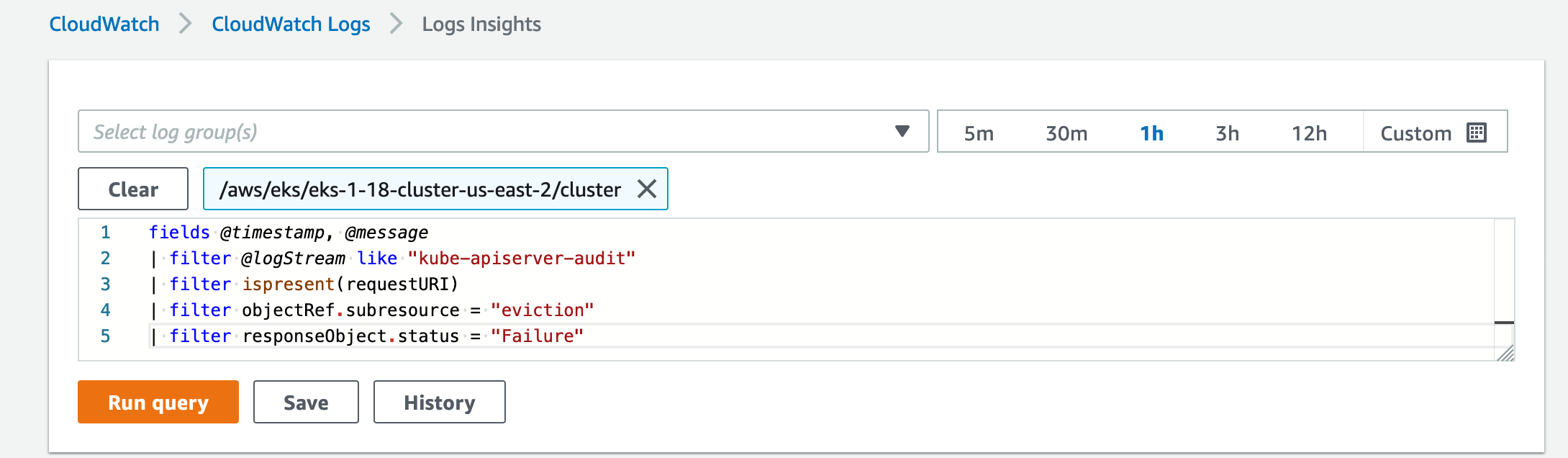
If the EKS controlplane logs are enabled to the respective EKS cluster, you could use cloudwatch logs insights with following filter to understand for which all pods the eviction was a failure.
- Go to cloudwatch logs console, then click on insights.
- Now in the current window, select log groups which corresponds to Cluster Control Plane logs
- Use the below filter to check on all eviction failures that happened to the EKS cluster
fields @timestamp, @message | filter @logStream like "kube-apiserver-audit" | filter ispresent(requestURI) | filter objectRef.subresource = "eviction" | filter responseObject.status = "Failure" - After running the query with above filter, you could see all the eviction failures which includes repeated retries performed by the client.
- The "requestURI" present inside the message in the results of above query will point you on which pods triggered eviction failure.
Further to filter out all such duplicate eviction retries you could use the following query.
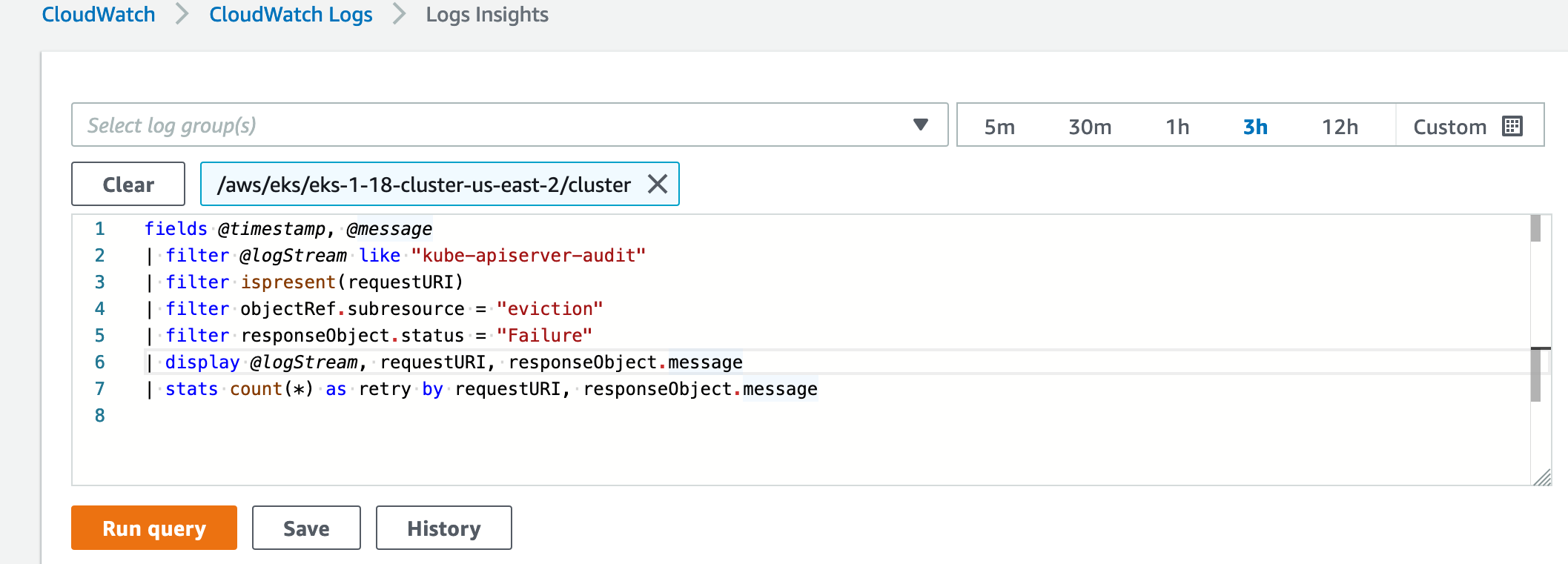
@TheRealGoku
Thanks, but that gives regular pod eviction failure, which happen all the time during an update because of PDB. So it doesn't really pinpoint me to the problem.
Any update on this? I am also facing the same problem. However, I see this problem more frequently if the calico network policy engine is running along with the vpc-cni plugin.
The issue seems to be related to the PDB (Pod Disruption Budget) due to which pods are not getting evicted from the node. Is there any option to forcefully evict the pods, I tried ForcedUpdateEnabled but doesn't help.
@dza89, Are you also having the problem more frequently when running with the calico? Any workaround apart from manually draining the nodes as that might not be feasible in the production setup?
I've been experiencing this issue on our larger clusters (50 nodes). I use terraform to update my cluster and this is the error. However, I was able to drain the node manually. However, newly created nodes are still using the previous version of the cluster so now my cluster nodes are a mix of v1.21 and v1.20 nodes. I used the aws cli to update the nodes specifying the release version and using the force flag but this might cause some downtime to some pods. Another is to create another node group and transfer all the pods to the new one and delete the old.

A side note, I was able to update one of our clusters with 5 nodes with no issues using the same terraform config.
The issue seems to be related to the PDB (Pod Disruption Budget) due to which pods are not getting evicted from the node. Is there any option to forcefully evict the pods, I tried ForcedUpdateEnabled but doesn't help.
aws eks update-nodegroup-version
--cluster-name <your_cluster_name>
--nodegroup-name <your_nodegroup_name>
--kubernetes-version 1.20
--release-version 1.20.7-20211004
--launch-template version=your_launch_template_version,id=your_launch_template_id
--force
I am seeing a very inconsistent behavior in updating nodegroups. Even deleting all the PodDisruptionBudget objects from the cluster, and using the "force" update option, I am still seeing a 1-hour update time on a 2-node nodegroup, which -sometimes- ends up in error.
One of the reasons why --force doesn't not work with PDB (Pod Disruption Budget) is due to this issue. CrashLoopBackOff state is considered in the Running phase and not the Failed phase due to which unready pods are not evicted as they will charge a PDB a disruption.
My workaround was to bring the "desired size" down to zero. Then manually terminate the nodes that refused to quit. It's likely these were the nodes that were preventing the update. On occasion I'll notice stubborn Istio pods.
we also faced same issue while upgrade nodes from 1.23v to 1.24.13 .. we have pdb but those pdb are for different node groups and those node. groups upgraded successfully. can we know the reason and what to fix .. we dont want to run upgrade with force option.
Here we noticed the reason was an istiod impossible-to-evict pod, so after we forced the pod deletion the process continued as expected
Thanks for the feedback, we'll include the pod name that failed to be evicted
Was wondering if this is likely to be implemented?
How about making the maximum number of retries configurable?
PDB are useful to make updates seamless, but sometimes it just takes a (very very) long time to take down the old pod / spin a new one. Would be immensely useful if that parameter "MaxNumberOfRetries" was exposed somehow.
Force update is not OK because it can induce downtime.
Thanks for the feedback, we'll include the pod name that failed to be evicted
Is there any ETA for that? It's been more than 3 years(!) 🤓