auto-sklearn
 auto-sklearn copied to clipboard
auto-sklearn copied to clipboard
Accuracy of autosklearn can be improved with Intel® Extension for Scikit-learn
Accuracy of autosklearn can be improved with Intel® Extension for Scikit-learn
What is this?
Intel® Extension for Scikit-learn provides drop-in replacement patching functionality for a seamless way to speed up Scikit-learn application.
Our results
I used automlbenchmarks on large datasets to compare accuracy of autosklearn with patching and without.
| datasetName | library | acc | auc | balacc | logloss |
|---|---|---|---|---|---|
| Airlines | autosklearn w patching | 0.667087 | 0.720931 | 0.654484 | 0.664864 |
| Albert | autosklearn w patching | 0.677265 | 0.738089 | 0.677265 | 0.642248 |
| Covertype | autosklearn w patching | 0.918092 | 0.835118 | 0.214061 | |
| Airlines | autosklearn w/o pathcing | 0.654552 | 0.696719 | 0.663029 | 0.686289 |
| Albert | autosklearn w/o patching | 0.652432 | 0.706782 | 0.652432 | 0.691148 |
| Covertype | autosklearn w/o patching | 0.908678 | 0.829109 | 0.252917 |
The table below represent the difference of autosklearn with patching and w/o patching
| datasetName | diff accuracy | diff auc | diff balacc | diff logloss |
|---|---|---|---|---|
| Airlines | 0.012535 | 0.024212 | -0.008545 | -0.02132 |
| Albert | 0.024833 | 0.031307 | 0.024833 | -0.0489 |
| Covertype | 0.009414 | 0 | 0.006009 | -0.03886 |
Accuracy was improved because the number of trained models was increased. The full list of algorithms, that can be accelerated with intel extension for scikit-learn can be founded here.
| datasetName | Airlines | Albert | Covertype |
|---|---|---|---|
| total number of models w patching | 154 | 180 | 118 |
| total number of models w/o patching | 130 | 142 | 110 |
How to reproduce our results
To add the intel extension for scikit-learn to the benchmark, you just need to add 2 lines at the beginning of the autosklearn exec file:
from sklearnex import patch_sklearn
patch_sklearn()
and add scikit-learn-intelex to the requirements.
I also change constraints for a more honest comparison:
test:
folds: 2
max_runtime_seconds: 1800
cores: 72
And remove environment settings from autosklearn exec file.
os.environ['OPENBLAS_NUM_THREADS'] = '1'
os.environ['MKL_NUM_THREADS'] = '1'
All measurements were done on AWS c5.18xlarge instance (Intel Xeon Platinum with 36 cores)
Some benefits of Intel® Extension for Scikit-learn
- Library uses all capabilities of the hardware, which allows you to get a significant performance boost for the classic machine learning algorithms. Check their patching section and medium articles for more details.
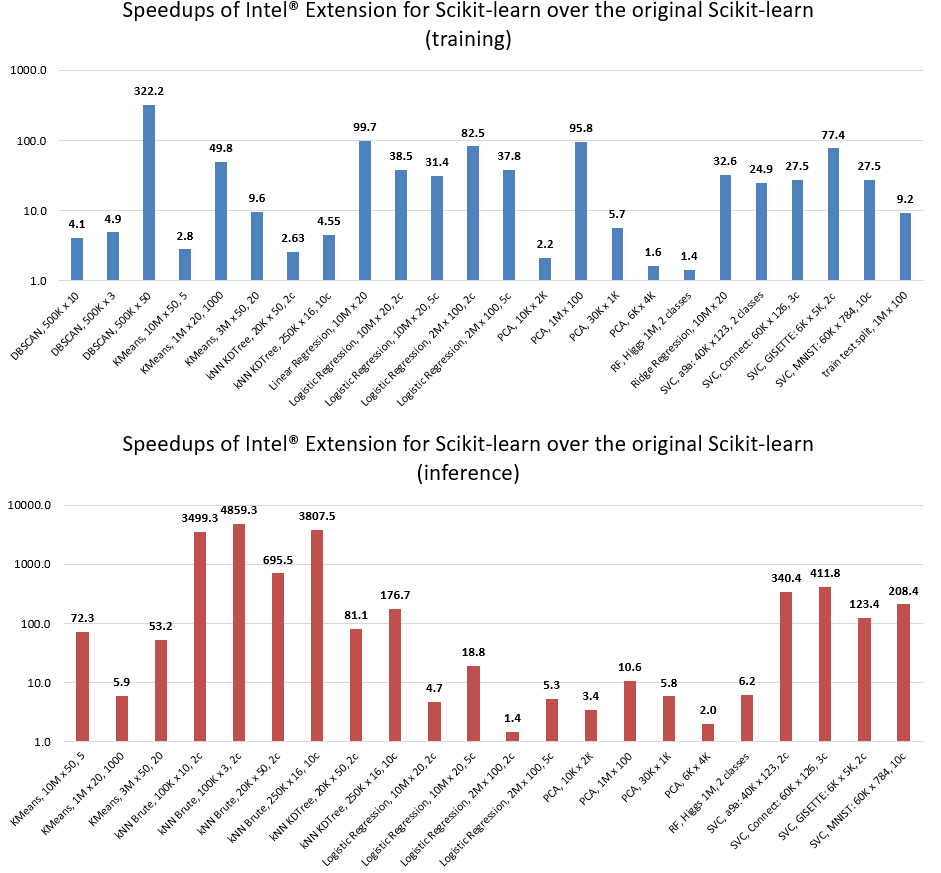
- All optimizations can be easily integrated into scikit-learn application by changing one line of code. Check their get started section for more details.
I also think, that Intel® Extension for Scikit-learn can help to solve these problems: https://github.com/automl/auto-sklearn/issues/445, https://github.com/automl/auto-sklearn/issues/923, https://github.com/automl/auto-sklearn/issues/1153
What do you think?
Hi @PivovarA, we appreciate the detailed analysis of improvements and it certainly is very helpful to made aware of!
While this certainly seems like a cheap way to improve performance by being able to evaluate more models as you say, it does limit their configuration spaces as advertised here.
For example, their restriction:
All parameters except warm_start = True, cpp_alpha != 0, criterion != ‘gini’, oob_score = True.
... would prevent the default 'entropy' criterion in random_forest (here).
The question is then whether a restriction on the searched parameter space is worth the improvements, perhaps this could cause catastrophic failure on other datasets. This would largely depend on the datasets used in a benchmark and would require a lot of testing.
While in practice this could be turned off and on within autosklearn itself, a user could just enable this themselves if they really wanted to?
Given that you've run this and done your own testing, were there any issues with just adding:
from sklearnex import patch_sklearn
patch_sklearn()
.. and then running the automlbenchmark?
I will inform other maintainers for their opinion.
@eddiebergman, just to clarify, if sklearnex doesn't support some parameter (like entropy for RF) - it doesn't crash or skip this parameter. In this case the extension will just call original scikit-learn with entropy parameter as expected, there is no speedup in this case, but it makes sklearnex conformant with original version.
Also, we are growing # of supported algorithms and parameters each release, and entropy is in plans.
Given that you've run this and done your own testing, were there any issues with just adding .. and then running the automlbenchmark?
Yes, just call these lines before all sklearn imports. You can also check that all required algorithms were patched: https://intel.github.io/scikit-learn-intelex/verbose.html
While in practice this could be turned off and on within autosklearn itself, a user could just enable this themselves if they really wanted to?
To be honest, we need to run auto-sklearn tests + do more benchmarking. Do you have own benches? If it's okay, just an option, we can enable sklearnex as an optional dependency and document this. It's implemented in AutoGluon already. Like this:
pip install auto-sklearn[sklearnex]
P.S. we also can enable expensive algos like SVM, which is extremely faster with sklearnex: Save Time and Money with Intel Extension for Scikit-learn From Hours to Minutes: 600x Faster SVM
@SmirnovEgorRu Okay, thanks for the clarifications on that, appreciate it!
There are some more internal tests that we do but no where near comprehensive enough. However if this is purely a speed optimization and does not provide any restrictions on configurations, I do not see this causing any significant performance drops in all but the outermost edge case.
I also agree that an optional dependency along with a brief note documenting this addition would make the most sense, making it an opt-in feature instead of opt-out.
Seeing as there is no real downsides, this will be discussed soon and we will get back to you then!
@SmirnovEgorRu Allo again,
After some discussion, we have decided not to integrate this into the library itself. Instead, we will provide unit-test support for using Intel® Extension for Scikit-learn as well as provide easily accessible documentation on how a user can improve performance if they want to install this extra requirement.
This has been documented as an issue which you can find here (#1184). It is however not an immediate priority but if you wish to provide help with the issue, we would be happy to help out.
Reasons for not wanting to integrate it into the core library:
- This is an extra dependency that is not used by any
autosklearncode directly. -
Intel® Extension for Scikit-learnis very readily accessible and has an impressive 'plug-and-play' feature that we believe is best left for a user to enable, but only if they wish. - This would open the door to considering other 'plug-and-play' performance improvements which is not in the plan for
autosklearnat the moment. - Being tied to Intel may be okay for now but not incorporating this library allows for greater flexibility in licensing if anything were to change for
autosklearnor forIntel® Extension for Scikit-learn.