Dask Parallelization not resource efficient when the aquisition function evalutions are the bottleneck
Dear all,
I wrote a CustomRandomForest class that augments the hyperparameters with additional metadata features. The computation of the metadata features requires some computation. Therefore, the evaluation of the acquisition function is more expensive than usual. When I parallelize it using the Dask parallelization strategy, the resources are not fully used:
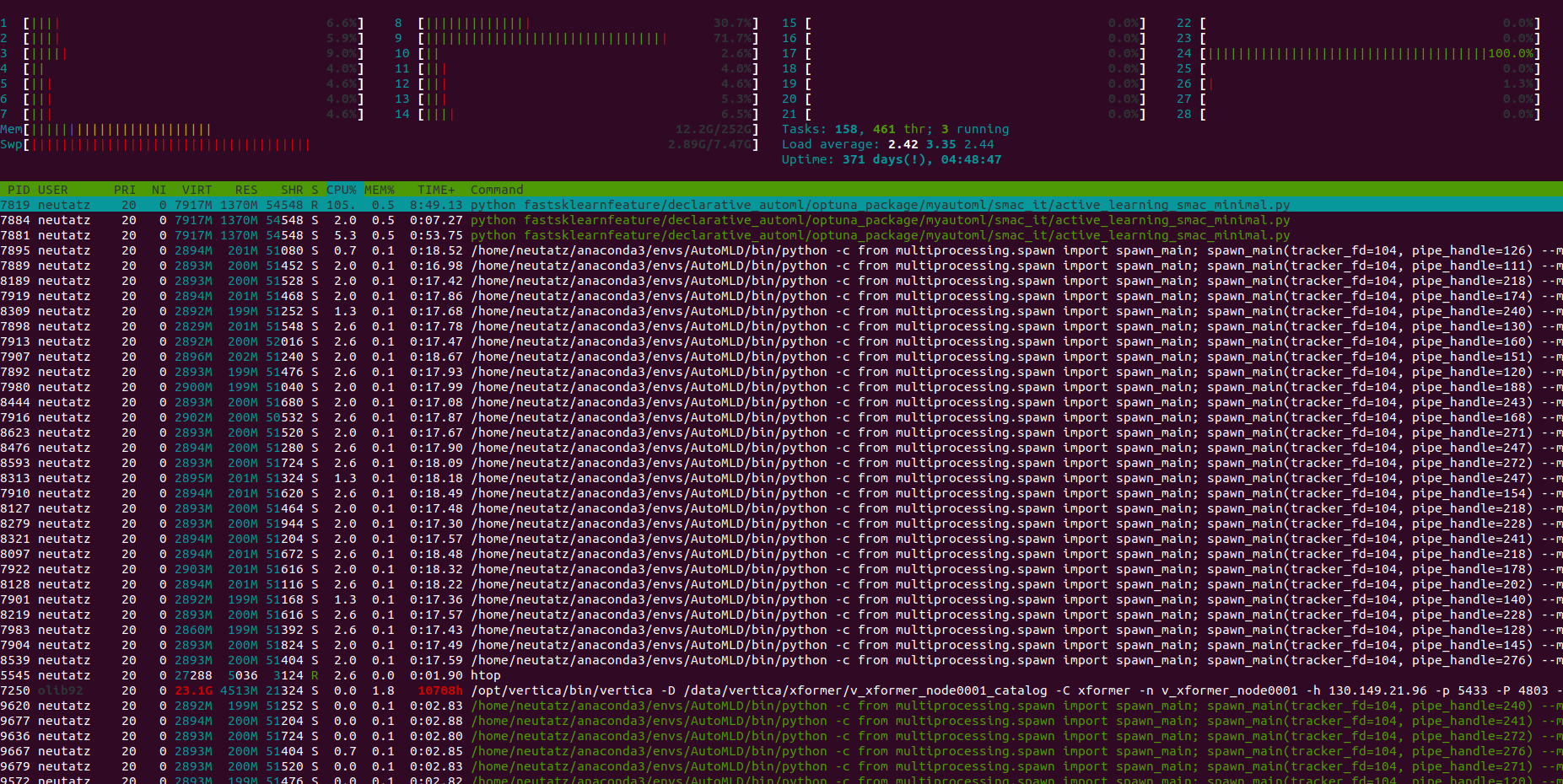
I suspect that the evaluations of the acquisition function are not parallelized?
However, if I use the pSMAC parallelization approach, it can utilize all resources:
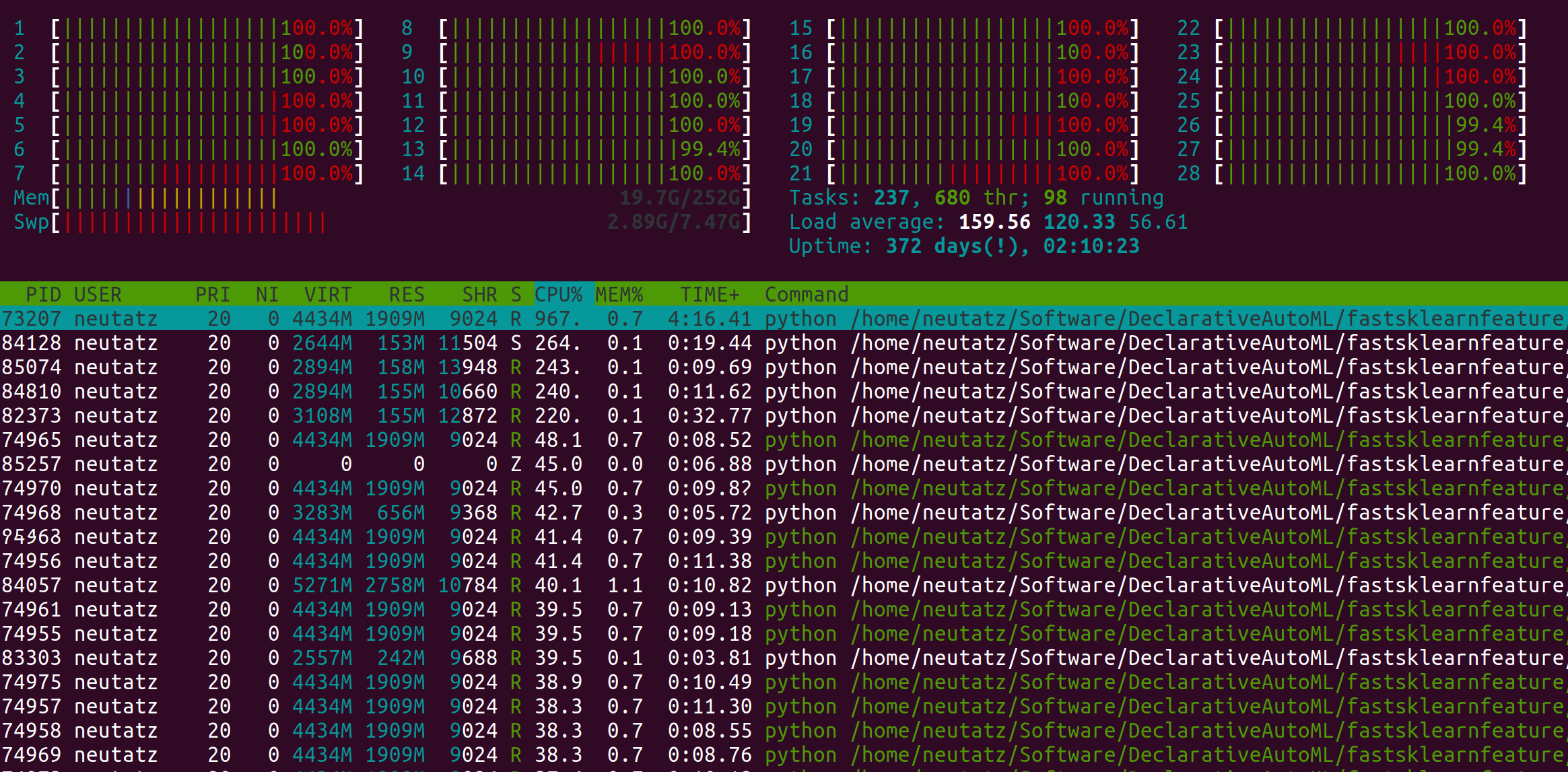
Best regards, Felix
Hi, sorry for the late reply, optimizing the acquisition function values is not parallelized: https://github.com/automl/SMAC3/blob/master/smac/optimizer/ei_optimization.py#L351
DASK is only applied to run your target function parallelly , but not the acquisition optimization part.
PSMAC applied different strategy to do parallel optimization (it creates several SMAC optimizer in parallel and thus will make full use of resources)
Hi, sorry for the late reply, optimizing the acquisition function values are not parallelized: https://github.com/automl/SMAC3/blob/master/smac/optimizer/ei_optimization.py#L351
DASK is only applied to run your target function parallelly , but not the acquisition optimization part.
PSMAC applied different strategy to do parallel optimization (it creates several SMAC optimizer in parallel and thus will make full use of resources)
When you say "run target function parallelly", does that mean running the target function observation with one config or multiple configs?
When you say "run target function parallelly", does that mean running the target function observation with one config or multiple configs?
With multiple configs. However, the current EPM chooser implementation is not designed for batched optimization, the suggested configurations might gather at a very small region.