Awesome-Controllable-Diffusion
 Awesome-Controllable-Diffusion copied to clipboard
Awesome-Controllable-Diffusion copied to clipboard
Papers and resources on Controllable Generation using Diffusion Models, including ControlNet, DreamBooth, IP-Adapter.
Awesome Controllable Generation
![]()
![]()

Papers and Resources on Adding Conditional Controls to Deep Generative Models in the Era of AIGC.
Dive into the cutting-edge of controllable generation in diffusion models, a field revolutionized by pioneering works like ControlNet [1] and DreamBooth [2]. This repository is invaluable for those interested in advanced techniques for fine-grained synthesis control, ranging from subject-driven generation to intricate layout manipulations. While ControlNet and DreamBooth are key highlights, the collection spans a broader spectrum, including recent advancements and applications in image, video, and 3D generation.
Updated daily
Contents
-
Papers
- Diffusion Models
- Consistency Models
- Other Resources
- Other Awesome Lists
- Contributing
Papers
Diffusion Models
-
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation.
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman. CVPR'23. 🔥

-
Adding Conditional Control to Text-to-Image Diffusion Models.
Lvmin Zhang, Anyi Rao, Maneesh Agrawala. ICCV'23. 🔥
-
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie. Preprint 2023. 🔥
-
Subject-driven Text-to-Image Generation via Apprenticeship Learning.
Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Ruiz, Xuhui Jia, Ming-Wei Chang, William W. Cohen. NeurIPS'23.
-
InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning.
Jing Shi, Wei Xiong, Zhe Lin, Hyun Joon Jung. Preprint 2023.
-
Dongxu Li, Junnan Li, Steven C.H. Hoi. NeurIPS'23. 🔥
-
ControlVideo: Conditional Control for One-shot Text-driven Video Editing and Beyond.
Min Zhao, Rongzhen Wang, Fan Bao, Chongxuan Li, Jun Zhu. Preprint 2023.
-
StyleDrop: Text-to-Image Generation in Any Style.
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, Yuan Hao, Irfan Essa, Michael Rubinstein, Dilip Krishnan. NeurIPS'23. 🔥
-
Face0: Instantaneously Conditioning a Text-to-Image Model on a Face.
Dani Valevski, Danny Wasserman, Yossi Matias, Yaniv Leviathan. SIGGRAPH Asia'23.
-
Controlling Text-to-Image Diffusion by Orthogonal Finetuning.
Zeju Qiu, Weiyang Liu, Haiwen Feng, Yuxuan Xue, Yao Feng, Zhen Liu, Dan Zhang, Adrian Weller, Bernhard Schölkopf. NeruIPS'23.
-
Zero-shot spatial layout conditioning for text-to-image diffusion models.
Guillaume Couairon, Marlène Careil, Matthieu Cord, Stéphane Lathuilière, Jakob Verbeek. ICCV'23.
-
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models.
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, Wei Yang. Preprint 2023. 🔥
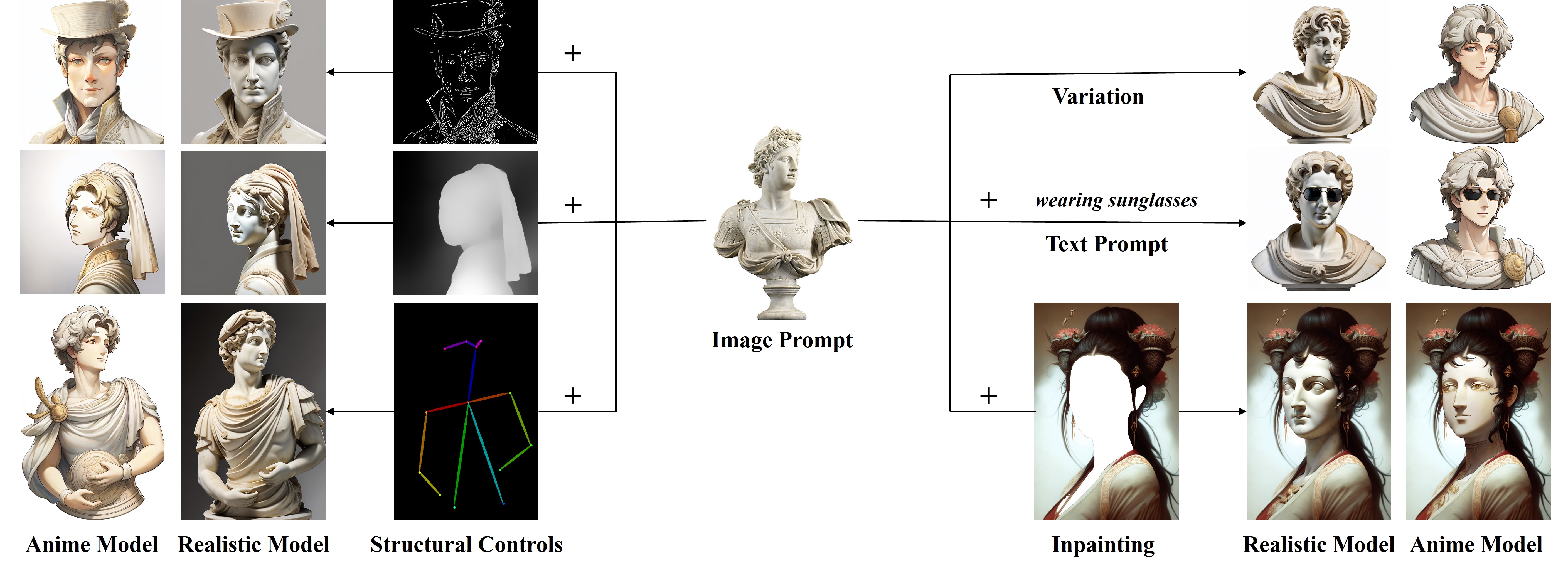
-
StyleAdapter: A Single-Pass LoRA-Free Model for Stylized Image Generation.
Zhouxia Wang, Xintao Wang, Liangbin Xie, Zhongang Qi, Ying Shan, Wenping Wang, Ping Luo. Preprint 2023.
-
DreamStyler: Paint by Style Inversion with Text-to-Image Diffusion Models.
Namhyuk Ahn, Junsoo Lee, Chunggi Lee, Kunhee Kim, Daesik Kim, Seung-Hun Nam, Kibeom Hong. AAAI 2023.
-
Kosmos-G: Generating Images in Context with Multimodal Large Language Models
Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng, Wenhu Chen, Furu Wei. Preprint 2023. 🔥
-
Chen Jin, Ryutaro Tanno, Amrutha Saseendran, Tom Diethe, Philip Teare. Preprint 2023.
-
Ziyang Yuan, Mingdeng Cao, Xintao Wang, Zhongang Qi, Chun Yuan, Ying Shan. Preprint 2023.
-
Cross-Image Attention for Zero-Shot Appearance Transfer.
Yuval Alaluf, Daniel Garibi, Or Patashnik, Hadar Averbuch-Elor, Daniel Cohen-Or. Preprint 2023.
-
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models.
Omri Avrahami, Amir Hertz, Yael Vinker, Moab Arar, Shlomi Fruchter, Ohad Fried, Daniel Cohen-Or, Dani Lischinski. Preprint 2023.
-
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer.
Di Chang, Yichun Shi, Quankai Gao, Jessica Fu, Hongyi Xu, Guoxian Song, Qing Yan, Xiao Yang, Mohammad Soleymani. Preprint 2023.
-
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs.
Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svetlana Lazebnik, Yuanzhen Li, Varun Jampani. Preprint 2023.
-
StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter.
Gongye Liu, Menghan Xia, Yong Zhang, Haoxin Chen, Jinbo Xing, Xintao Wang, Yujiu Yang, Ying Shan. Preprint 2023.
-
Style Aligned Image Generation via Shared Attention.
Amir Hertz, Andrey Voynov, Shlomi Fruchter, Daniel Cohen-Or. Preprint 2023. 🔥

-
FaceStudio: Put Your Face Everywhere in Seconds.
Yuxuan Yan, Chi Zhang, Rui Wang, Yichao Zhou, Gege Zhang, Pei Cheng, Gang Yu, Bin Fu. Preprint 2023.
-
Context Diffusion: In-Context Aware Image Generation.
Ivona Najdenkoska, Animesh Sinha, Abhimanyu Dubey, Dhruv Mahajan, Vignesh Ramanathan, Filip Radenovic. Preprint 2023.
-
PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding.
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming-Ming Cheng, Ying Shan. Preprint 2023. 🔥

-
SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing.
Zeyinzi Jiang, Chaojie Mao, Yulin Pan, Zhen Han, Jingfeng Zhang. Preprint 2023.
-
DreamTuner: Single Image is Enough for Subject-Driven Generation.
Miao Hua, Jiawei Liu, Fei Ding, Wei Liu, Jie Wu, Qian He. Preprint 2023.
-
PALP: Prompt Aligned Personalization of Text-to-Image Models.
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen. Preprint 2024.
-
InstantID: Zero-shot Identity-Preserving Generation in Seconds.
Moab Arar, Andrey Voynov, Amir Hertz, Omri Avrahami, Shlomi Fruchter, Yael Pritch, Daniel Cohen-Or, Ariel Shamir. Preprint 2024. 🔥

-
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs.
Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui. Preprint 2024. 🔥

Text prompt: A beautiful landscape with a river in the middle the left of the river is in the evening and in the winter with a big iceberg and a small village while some people are skating on the river and some people are skiing, the right of the river is in the summer with a volcano in the morning and a small village while some people are playing. -
UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion.
Wei Li, Xue Xu, Jiachen Liu, Xinyan Xiao. Preprint 2024 🔥

-
Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with Prototypical Embedding
Jianxiang Lu, Cong Xie, Hui Guo. Preprint 2024.
-
Training-Free Consistent Text-to-Image Generation
Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, Yuval Atzmon. Preprint 2024.
-
InstanceDiffusion: Instance-level Control for Image Generation
Xudong Wang, Trevor Darrell, Sai Saketh Rambhatla, Rohit Girdhar, Ishan Misra. Preprint 2024.
-
Text2Street: Controllable Text-to-image Generation for Street Views
Jinming Su, Songen Gu, Yiting Duan, Xingyue Chen, Junfeng Luo. Preprint 2024.
-
λ-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent Space
Maitreya Patel, Sangmin Jung, Chitta Baral, Yezhou Yang. Preprint 2024.
-
ComFusion: Personalized Subject Generation in Multiple Specific Scenes From Single Image
Yan Hong, Jianfu Zhang. Preprint 2024.
-
Direct Consistency Optimization for Compositional Text-to-Image Personalization
Kyungmin Lee, Sangkyung Kwak, Kihyuk Sohn, Jinwoo Shin. Preprint 2024. 🔥
-
MuLan: Multimodal-LLM Agent for Progressive Multi-Object Diffusion
Sen Li, Ruochen Wang, Cho-Jui Hsieh, Minhao Cheng, Tianyi Zhou. Preprint 2024.
-
Xinchen Zhang, Ling Yang, Yaqi Cai, Zhaochen Yu, Jiake Xie, Ye Tian, Minkai Xu, Yong Tang, Yujiu Yang, Bin Cui. Preprint 2024.
-
Visual Style Prompting with Swapping Self-Attention
Jaeseok Jeong, Junho Kim, Yunjey Choi, Gayoung Lee, Youngjung Uh. Preprint 2024.
-
Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition
Chun-Hsiao Yeh, Ta-Ying Cheng, He-Yen Hsieh, Chuan-En Lin, Yi Ma, Andrew Markham, Niki Trigoni, H.T. Kung, Yubei Chen. Preprint 2024.
-
Multi-LoRA Composition for Image Generation
Ming Zhong, Yelong Shen, Shuohang Wang, Yadong Lu, Yizhu Jiao, Siru Ouyang, Donghan Yu, Jiawei Han, Weizhu Chen. Preprint 2024. 🔥

-
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Vincent Tao Hu, Björn Ommer. Preprint 2024. 🔥

Consistency Models
-
CCM: Adding Conditional Controls to Text-to-Image Consistency Models
Jie Xiao, Kai Zhu, Han Zhang, Zhiheng Liu, Yujun Shen, Yu Liu, Xueyang Fu, Zheng-Jun Zha. Preprint 2023.
-
PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models
Junsong Chen, Yue Wu, Simian Luo, Enze Xie, Sayak Paul, Ping Luo, Hang Zhao, Zhenguo Li. Preprint 2024.
Other Resources
- Regional Prompter Set a prompt to a divided region.
Other Awesome Lists
- Awesome-LLM-Reasoning Collection of papers and resources on Reasoning in Large Language Models.
Contributing
- Add a new paper or update an existing paper, thinking about which category the work should belong to.
- Use the same format as existing entries to describe the work.
- Add the abstract link of the paper (
/abs/format if it is an arXiv publication).
Don't worry if you do something wrong, it will be fixed for you!