blog
 blog copied to clipboard
blog copied to clipboard
六十行代码完成 四则运算 语法解析器
syntax-parser 是完全利用 JS 编写的词法解析+语法解析引擎,所以完全支持在浏览器、NodeJS 环境执行。
它可以帮助你快速生成 词法解析器,亦或进一步生成 语法解析器,将字符串解析成语法树,语法解析器还支持下一步智能提示功能,输入光标位置,给出输入推荐。
目前 syntax-parser 功能逐渐稳定,内核性能还在逐步优化中,我们会利用 syntax-parser 引擎的能力,完成一些令人惊喜的小 DEMO,如果与你的业务场景恰好契合,欢迎使用!
这次的 DEMO 是:利用 syntax-parser 快速完成四则运算语法解析器!
1. 生成词法解析器
通过下面 20 行配置,生成一个能解析英文、数字、加减乘除、左右括号的词法解析器,so easy!
import { createLexer } from 'syntax-parser'
const myLexer = createLexer([
{
type: 'whitespace',
regexes: [/^(\s+)/],
ignore: true
},
{
type: 'word',
regexes: [/^([a-zA-Z0-9]+)/] // 解析数字
},
{
type: 'operator',
regexes: [
/^(\(|\))/, // 解析 ( )
/^(\+|\-|\*|\/)/ // 解析 + - * /
]
}
]);
我们可以使用 myLexer 将字符串解析为一个个 Token:
myLexer('1 + 2 - 3 * b / (x + y)')
不过这次的目的是生成语法树,所以我们会把 myLexer 作为参数传给语法解析器。
2. 生成语法解析器
五个文法,20 行代码搞定,表示四则运算的文法,可以参考 此文。
利用 chain ,可以高效表示每一个文法表达式要匹配的字符串、表示匹配次数,还支持嵌入新的文法函数。这些相互依赖的文法组成了一个文法链条,完整表达了四则运算的逻辑:
import { chain, createParser, many, matchTokenType } from 'syntax-parser'
const root = () => chain(term, many(addOp, root))(parseTermAst);
const term = () => chain(factor, many(mulOp, root))(parseTermAst);
const mulOp = () => chain(['*', '/'])(ast => ast[0].value);
const addOp = () => chain(['+', '-'])(ast => ast[0].value);
const factor = () => chain([
chain('(', root, ')')(ast => ast[1]),
chain(matchTokenType('word'))(ast => ast[0].value)
])(ast => ast[0]);
const myParser = createParser(
root, // Root grammar.
myLexer // Created in lexer example.
);
createParser 函数第一个参数接收根文法表达式,第二个参数是词法解析器,我们将上面创建的 myLexer 传入。 parseTermAst 函数单独提出来,目的是辅助生成语法树,一共 20 行代码:
const parseTermAst = (ast: any) =>
ast[1]
? ast[1].reduce(
(obj: any, next: any) =>
next[0]
? {
operator: next[0],
left: obj || ast[0],
right: next[1]
}
: {
operator: next[1] && next[1].operator,
left: obj || ast[0],
right: next[1] && next[1].right
},
null
)
: ast[0];
这个函数是为了将语法树变得更规整,否则得到的 AST 解析将会是数组,而不是像 left right operator 这么有含义的对象。
PS:本文的 DEMO 没有考虑乘除高优先级问题。
3. 运行词法解析器
最后得到的 myParser 就是语法解析器了!直接执行就能拿到语法树结果!
const result = myParser('1 + 2 - (3 - 4 + 5) * 6 / 7');
console.log(result.ast)
我们打印出语法树,运行结果如下:
{
"operator": "/",
"left": {
"operator": "-",
"left": {
"operator": "+",
"left": "1",
"right": "2"
},
"right": {
"operator": "*",
"left": {
"operator": "+",
"left": {
"operator": "-",
"left": "3",
"right": "4"
},
"right": "5"
},
"right": "6"
}
},
"right": "7"
}
4. 错误提示
不仅语法树,我们构造一个错误的输入试试!
const result = myParser('1 + 2 - (3 - 4 + 5) * 6 / ');
console.log(result.error)
这次我们打印错误信息:
{
"suggestions": [
{
"type": "string",
"value": "("
},
{
"type": "special",
"value": "word"
}
],
"token": {
"type": "operator",
"value": "/",
"position": [
24,
25
]
},
"reason": "incomplete"
}
精准的提示了最后一个 / 位置不完整,建议是填写 ( 或者一个单词。这都是根据文法自动生成的建议,提示不多一个,不少一个!
5. 任意位置输入提示
最精髓的功能到了,这个语法解析器就是为了做自动提示,所以支持多传一个参数,告诉我当前你光标的位置:
const result = myParser('1 + 1', 5)
console.log(result.nextMatchings)
假设语句写到这里,我们光标位置定位到 5 的位置,也就是最后一个 1 后面,nextMatchings 属性会告诉我们后面的可能情况:
[
{
"type": "string",
"value": "-"
},
{
"type": "string",
"value": "+"
},
{
"type": "string",
"value": "/"
},
{
"type": "string",
"value": "*"
}
]
6. 结合业务,用在文本编辑器
笔者拿 monaco-editor 举例,利用上面的语法树解析,我们可以轻松完成下面的效果:
光标智能补全

错误提示
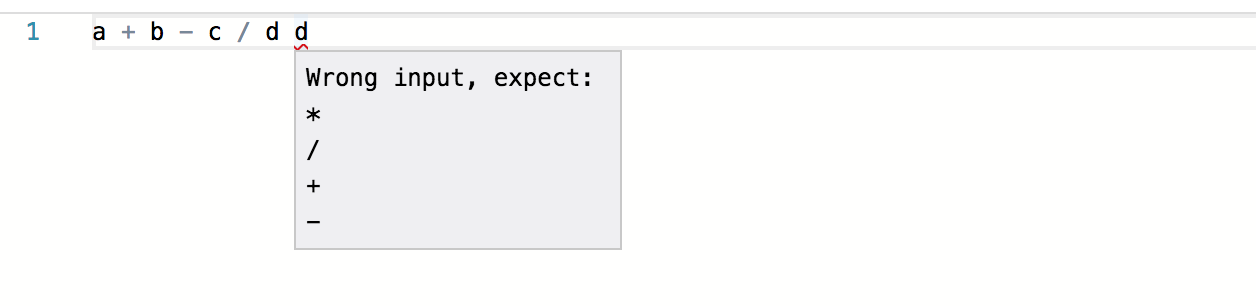
无论是智能补全,还是错误提示都是 100% 精准无误的(根据上面编写的文法表达式)。
相比普通的语法解析器在解析错误时直接抛出错误,syntax-parser 不仅提供语法树,还能根据文法智能提示光标位置的输入推荐,哪怕是输入错误的情况下,是不是解决了大家的痛点呢?如果觉得好用,欢迎给 syntax-parser 提 建议 或者 pr !