Antonin RAFFIN
Antonin RAFFIN
Duplicate of https://github.com/Stable-Baselines-Team/stable-baselines3-contrib/issues/76 @dylanprins I would happy to share the link in the doc if you could open source your implementation ;)
> Now that the lstm_states come directly from the buffer, rather than being computed from the start, doesn't that mean that the backpropagation though time procedure merely goes back for...
> But I'm still a little confused, because from my perspective, the sampled obs should be of the shape (batch_size, history_length, obs_dim), Actually no, the main reason is that you...
Hello, good point, i did that mainly to save space, but you are right, we should give the ability to save each checkpoint stats too. The other thing is that...
> Saving each checkpoint stats may cost space and, in general, is not necessary. Probably, It is reasonable and practical to save the stats of best_model.zip and {env_id}.zip. I would...
Hello, it depends on what you want. For instance, if you return `best_mean_reward`, it will favor trials that reaches high values but are not necessary stable: 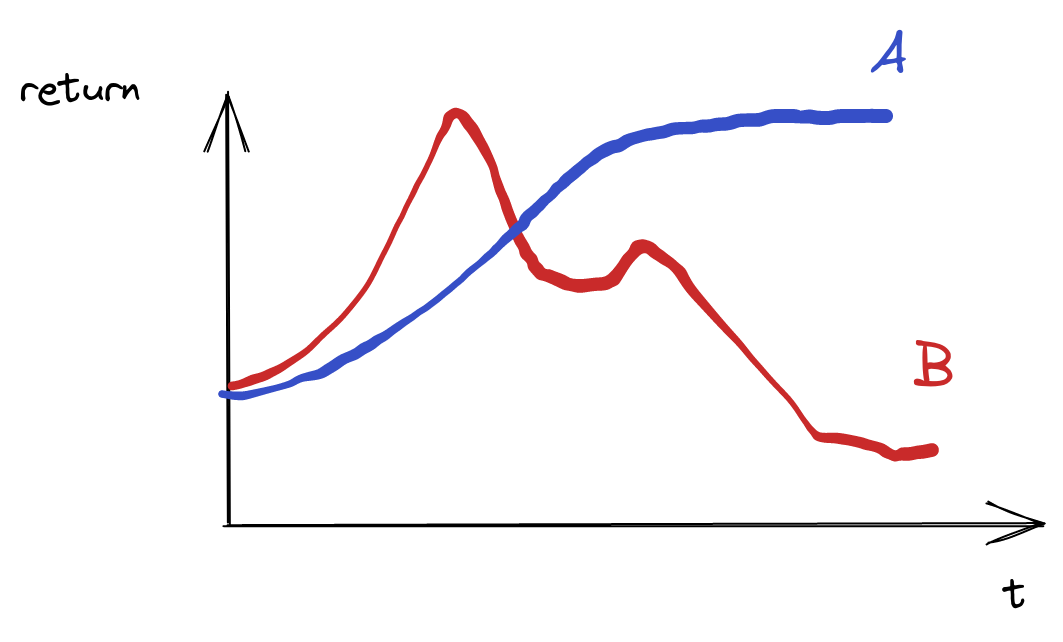 Returning `best_mean_reward` will...
> Indeed I agree it should be user-configurable. I would be happy to receive a PR that adds this parameter ;)
> I've been customizing exp_manager for my application, so adding early stopping to TrialEvalCallback you should be able to do that directly in the yaml file, no need to modify...
Replying from https://github.com/DLR-RM/stable-baselines3/issues/1045 > The default value for "deterministic_eval = not self.is_atari(env_id)" in exp_manager.py is True for my own custom env. So >evaluating for more episodes will give the same...
> l. Therefore when enjoying the best_model, it will load the last pkl and give a very different reward if the statistics in the two pkls differ too much. Related...