arXivTimes

arXivTimes copied to clipboard
Pix2seq: A Language Modeling Framework for Object Detection
一言でいうと
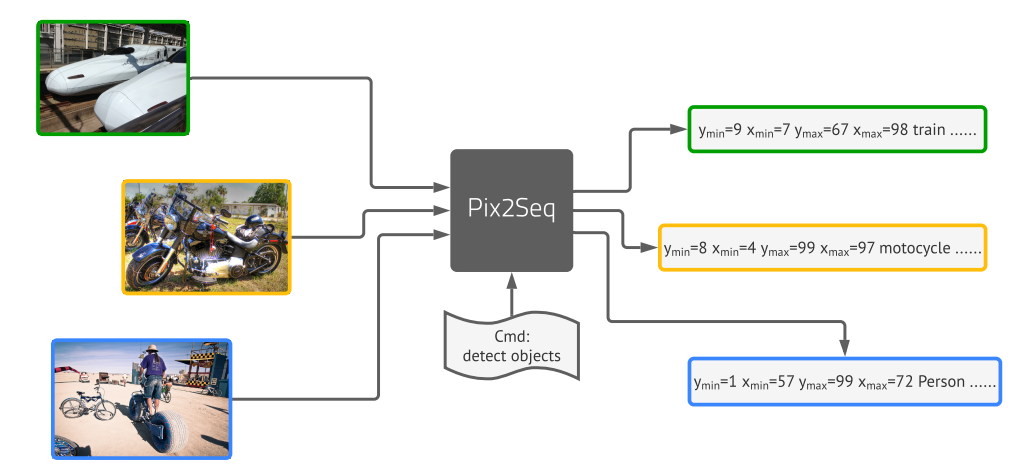
物体検出を言語モデルの枠組みで解いた研究。bounding boxとラベルをテキスト記述とする(位置は連続値であるため、区間(bin)で区切り離散化する)。Encoder/Decoderの構造で、画像をEncodeした結果からDecoderで検出結果記述を生成。Faster R-CNN/DETRと同等精度を達成。
論文リンク
https://arxiv.org/abs/2109.10852
著者/所属機関
Ting Chen, Saurabh Saxena, Lala Li, David J. Fleet, Geoffrey Hinton
- Google Research,
投稿日付(yyyy/MM/dd)
2021/9/22