RNN-for-Joint-NLU
 RNN-for-Joint-NLU copied to clipboard
RNN-for-Joint-NLU copied to clipboard
关于 initial_fn,sample_fn,next_inputs_fn 三个函数的介绍 求助

我理解的attention。这样理解对吗?
Kevin Chan 能简单介绍下这三个函数的用处吗? 我对 helper 这块的代码看不懂。
另外 谢谢你昨天的回复
你好,Kevin Chan 大佬。 我想知道 T B D 是代表什么意思? 谢谢了
你好, 分别代表Time_step, Batch_size, Hidden_size。 不要叫大佬,一起交流哈。 另外有问题直接在github上发issue,我会尽快回答。
initialize_fn:返回finished,next_inputs。其中finished不是scala,是一个一维向量。这个函数即获取第一个时间节点的输入。
sample_fn:接收参数(time, outputs, state) 返回sample_ids。即,根据每个cell的输出,如何sample。
next_inputs_fn:接收参数(time, outputs, state, sample_ids) 返回 (finished, next_inputs, next_state),根据上一个时刻的输出,决定下一个时刻的输入。
这个sample_ids 是什么意思
代码中好多.keys() 使得代码生成字典的时间变长了好多。其实直接 in就好了 不用keys会快, 加了keys()反而变成了不是hash查找了。
decoder的output是每个词的概率,具体要生成哪个词,可以采用不同的策略.直接选择概率最大的,就是greedy,还可以用beam search的策略,可以了解下。decoder中把每一个时刻产生的输出重新embedding,作为下一个时刻的输入之一。至于你说的keys()问题,谢谢指出,有时间我会修改下。
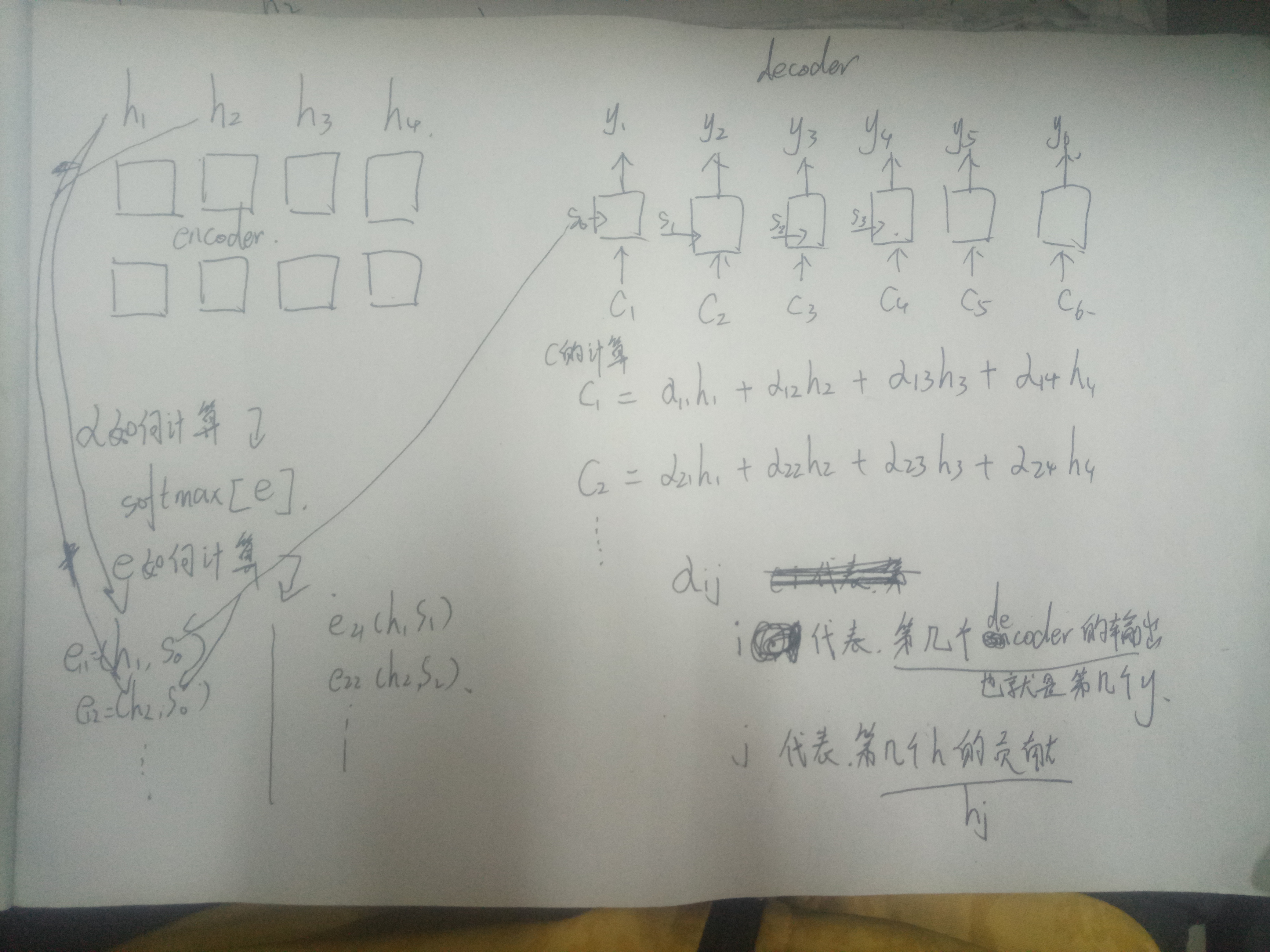
 大佬看下图 我的流程有没有错
大佬看下图 我的流程有没有错
@applenob 有个问题很迷惑,麻烦帮助解答一下。 1、在CustomHelper的三个方法中,我的理解initial_fn定义decode的初始输入状态,sample_fn方法根据当前step的rnn cell的outputs确定该step的最终输出,next_inputs_fn根据当前step的相关信息确定下一个step的输入。 2、在每一个step,rnn cell的输出shape为(?, 16, 122),其中第一维等于设定的decode_step大小,最后一维大小与slot的词表大小一致,我的理解最后一维是当前step输出每个slot的概率,根据概率即可获取到当前step的对应的slot的值,不知是否有问题。 3、在next_inputs_fn方法中,请问参数sample_ids表示的是什么呢,是sample_fn返回的值也就是当前step的输出对应的slot的id吗?在您的代码中下一个step的输入包括根据sample_ids获取的embedding,那么这个sample_ids应该是词表的id才对,和前面的假设就矛盾了。如果这个sample_ids是表示word的id,那么这个word是如何确定的呢? 以上问题还请帮助解答,谢谢!
@zldeng 我看到文档 是这样子写的 sample_fn: callable that takes (time, outputs, state) and emits tensor sample_ids. 也就是 那个 sample_idx 是那个 sample_fn 输出最大数字的下标。。也就是是slot值。。。
@bringtree 我也认为只有把 slot 的 embedding和 输入的embedding都混合在embedding中才能解释的通,也就是说在该模型中slot也训练了对应的embedding。而且还必须保证slot的index必须在整个vocab中的范围是[0,slot_cnt-1],文本单词的index其实下标从slt_cnt开始,否则就会有问题。因为decode的sample_ids范围是[0,slot_cnt)
@applenob 再请教下 initial_fn和next_inputs_fn这两个函数中的state,为什么只包含了 上一个时刻的输出y_(i-1) 和 对应的h_i, 而不包含context vector c_i和上一个时刻的隐状态 s_i?
@zldeng Joint Embedding of Words and Labels for Text Classification(ACL2018, Wang et al)
@NiceMartin "initial_fn和next_inputs_fn这两个函数中的state,为什么只包含了 上一个时刻的输出y_(i-1) 和 对应的h_i, 而不包含context vector c_i和上一个时刻的隐状态 s_i?" that is my question too, could you get the answer?
@NiceMartin "initial_fn和next_inputs_fn这两个函数中的state,为什么只包含了 上一个时刻的输出y_(i-1) 和 对应的h_i, 而不包含context vector c_i和上一个时刻的隐状态 s_i?" that is my question too, could you get the answer?
I guess that the attention mechanism code is no here. the attention mechanism code
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(
num_units=self.hidden_size, memory=memory,
memory_sequence_length=self.encoder_inputs_actual_length)
cell = tf.contrib.rnn.LSTMCell(num_units=self.hidden_size * 2)
attn_cell = tf.contrib.seq2seq.AttentionWrapper(
cell, attention_mechanism, attention_layer_size=self.hidden_size)