swift-collections
 swift-collections copied to clipboard
swift-collections copied to clipboard
Add a priority queue implementation built on top of `Heap`
Description
This introduces a double-ended PriorityQueue as discussed in #3.
Detailed Design
Heap (a min-max heap) is used as the storage. One of the big advantages of using a min-max heap is that we don't need to bifurcate into a min heap or max heap and keep track of which kind is used — you can pop min or max, as needed.
The main difference between Heap and PriorityQueue is that the latter separates the value from the comparable priority of it. This is useful in cases where a type doesn't conform to Comparable directly but it may have a property that does — e.g. Task.priority. It also keeps track of insertion order, so dequeueing of elements with the same priority should happen in FIFO order.
public struct PriorityQueue<Value, Priority: Comparable> {
public typealias Element = (value: Value, priority: Priority)
public var isEmpty: Bool
public var count: Int
// Initializers
public init()
public init<S: Sequence>(_ elements: S) where S.Element == Element
public init(arrayLiteral elements: Element...)
public init(dictionaryLiteral elements: (Value, Priority)...)
// Mutations/querying
public mutating func insert(_ value: Value, priority: Priority)
public func min() -> Value?
public func max() -> Value?
public mutating func popMin() -> Value?
public mutating func popMax() -> Value?
public mutating func removeMin() -> Value
public mutating func removeMax() -> Value
}
To-Do
- [x] Merge @AmanuelEphrem's
Sequenceconformance - [x] Reformat the code to match the 2 space indent/80 char width style
- [x] Optimize
_indexOfChildOrGrandchild(of:sortedUsing:)(probably by splitting it back out into 2 separate functions) - [x] Chase down suggestion from @timvermeulen about skipping nodes that have children
- [x] Figure out if
@inlinableis required - [x] Add checks for heap invariants
- [x] Make a call on whether or not we want to add
removeMin/Max - [x] Make
_minMaxHeapIsMinLevelan instance method - [x] Merge @hassila's changes to make
_bubbleUpMin(startingAt:)and_trickleDown(startingAt:)iterative instead of recursive - [X] Add implementation of
insert(contentsOf:) - [X] Rebase this on top of the
Heapimplementation merged intomain
Future Directions
- Add support for merging two priority queues
- Add
replaceMinandreplaceMax
Documentation
The public APIs have largely been documented. An overview document has been added to the Documentation directory.
Testing
There are unit tests for the added PriorityQueue type.
Performance
Performance tests have been added. @lorentey has a PR up (#76) which adds a std::priority_queue benchmark — it would be interesting to compare against that with more complex types.
We may want to revisit the library JSON to ensure we have the desired comparisons defined.
Source Impact
This is purely additive. No existing APIs were changed, deprecated, or removed.
Checklist
- [X] I've read the Contribution Guidelines
- [X] My contributions are licensed under the Swift license.
- [X] I've followed the coding style of the rest of the project.
- [X] I've added tests covering all new code paths my change adds to the project (to the extent possible).
- [X] I've added benchmarks covering new functionality (if appropriate).
- [X] I've verified that my change does not break any existing tests or introduce unexpected benchmark regressions.
- [X] I've updated the documentation (if appropriate).
This looks really good!
@timvermeulen Could you lend a second pair of eyes and review the heap logic?
The
PriorityQueuetype is a very thin wrapper on top ofMinMaxHeap. I went through and renamed some of the functions inMinMaxHeapbased on feedback @lorentey provided in #43; after doing so, it became an even thinner wrapper. Maybe it's not even needed?
I agree. I don't think the separate MinMaxHeap type is needed. Let's just have a single type called PriorityQueue!
It might be nice to add a few convenience APIs for bulk insertion/creation:
public init<S: Sequence>(_ elements: S) where S.Element == Elementpublic mutating func insert<S: Sequence>(contentsOf newElements: S) where S.Element == ElementExpressibleByArrayLiteralconformance
I have not yet run the performance tests to ensure the performance matches what is expected.
I think this would be the most profitable next step to take. It'd be great to see how the performance of PriorityQueue compares to CFBinaryHeap!
Super to see this in progress! Just one quick initial comment/question while browsing, push/pop is documented as Complexity: O(log n) - although if skipping levels as mentioned in article referenced previously in #3 the time complexity should be O(log n) / 2 - different implementation or documentation?
Just one quick initial comment/question while browsing, push/pop is documented as
Complexity: O(log n)- although if skipping levels as mentioned in article referenced previously in #3 the time complexity should beO(log n) / 2- different implementation or documentation?
The implementation does skip levels (see _bubbleUpMin and _bubbleUpMax — they reach for the grandparent nodes). My understanding is that when using big-O notation coefficients are usually not included.
In the case of Sequence conformance, how do we handle the double-endedness of the PriorityQueue? i.e. Should next() iterate from lowest to highest priority or vice-versa?
In the case of
Sequenceconformance, how do we handle the double-endedness of thePriorityQueue? i.e. Shouldnext()iterate from lowest to highest priority or vice-versa?
Maybe PriorityQueue shouldn't conform directly to Sequence but have (warning placeholder names!) a minHeap and maxHeap "view":
let q: PriorityQueue = ...
for elt in q.minHeap {
// iterates from min to max
}
for elt in q.maxHeap {
// iterates from max to min
}
wdyt?
In the case of
Sequenceconformance, how do we handle the double-endedness of thePriorityQueue? i.e. Shouldnext()iterate from lowest to highest priority or vice-versa?Maybe
PriorityQueueshouldn't conform directly toSequencebut have (warning placeholder names!) aminHeapandmaxHeap"view":let q: PriorityQueue = ... for elt in q.minHeap { // iterates from min to max } for elt in q.maxHeap { // iterates from max to min }wdyt?
Another approach I was mulling over is exposing separate functions for creating the iterator (e.g. makeLowToHighPriorityIterator and makeHighToLowPriorityIterator). That doesn't address the issue that will come up if somebody tries to iterate directly (though I guess that could be addressed by not conforming to Sequence directly).
I think exposing a view that conforms to Sequence makes more sense.
https://developer.apple.com/documentation/swift/bidirectionalcollection ?
If we can provide a bidirectional collection view I think that'd work great:
for elt in q.sortedElements {
// iterates from min to max
}
for elt in q.sortedElements.reversed() {
// iterates from max to min
}
However, it wasn't clear to me if we're able to provide an efficient bidirectional view over the heap.
If we can provide a bidirectional collection view I think that'd work great:
Would the priority queue be able to conform to the Collection protocol? Because min and max values are determined during the remove operation, the priority queue does not lend itself easily to random access of elements via indexes.
let q: PriorityQueue = ... for elt in q.minHeap { // iterates from min to max } for elt in q.maxHeap { // iterates from max to min }```
I like this method of traversing the priority queue, as it is the least ambiguous.
That doesn't address the issue that will come up if somebody tries to iterate directly
In this case, the iterator could default to iterating from min to max (or max to min if that makes more sense)
I don’t think the iterator necessarily should default to any sorted order - it could just provide “some” order unless asked for sorted / reversed as suggested? Just trying to find reuse of existing protocols if possible if performant and natural (that being said, can’t say whether efficiency would be good - but just wanted to point out that there is an existing interface that might be useful) - that would also argue for popFirst/popLast methods for dequeueing from respective ends
Because min and max values are determined during the remove operation, the priority queue does not lend itself easily to random access of elements via indexes.
This was my impression.
I don’t think the iterator necessarily should default to any sorted order - it could just provide “some” order unless asked for sorted / reversed as suggested?
I think both could be useful:
let q: PriorityQueue<Foo> = ...
let heap: [Element] = q.heap // direct access to the underlying heap array
for elt in q.minToMax { ... } // a sequence that iterates from min to max
for elt in q.maxToMin { ... } // a sequence that iterates from max to min
Direct access to the underlying heap array could be useful if want to efficiently hand off all the elements to an API that expects an Array if order isn't important.
Direct access to the underlying heap array could be useful if want to efficiently hand off all the elements to an API that expects an Array if order isn't important
I feel that exposing the underlying heap to the developer would introduce unnecessary complexity, and a separate function could return an array view of the priority queue.
Also, because elements of the highest priority are at the front of the priority queue, another way to conform to the Sequence protocol would be like this
let q: PriorityQueue = ...
for elt in q {
// iterates from max to min
}
for elt in q.reversed() {
// iterates from min to max
}
While I think this is the most straightforward way to traverse the priority queue, I'm not sure how intuitive it is for others.
I think conforming to Collection is out — I don't think there's a way to do this efficiently.
Direct access to the underlying heap array could be useful if want to efficiently hand off all the elements to an API that expects an Array if order isn't important
I feel that exposing the underlying heap to the developer would introduce unnecessary complexity, and a separate function could return an array view of the priority queue.
I think we should expose it as var unorderedElements: [Element].
Also, because elements of the highest priority are at the front of the priority queue[…]
Because we're using a min-max heap, the lowest-priority element is at the front of the backing array not the highest.
[…] another way to conform to the Sequence protocol would be like this
let q: PriorityQueue = ... for elt in q { // iterates from max to min } for elt in q.reversed() { // iterates from min to max }While I think this is the most straightforward way to traverse the priority queue, I'm not sure how intuitive it is for others.
I'm still in the camp of not adding conformance to Sequence to the priority queue type itself; I think that conformance belongs on the min and max views. I don't have good suggestions as far as naming those, though. I think calling them minHeap and maxHeap exposes some of the implementation details.
Meta question: does this sort of discussion belong in the forums or would we rather it happen here?
I think that conformance belongs on the min and max views
I can get behind this idea as well!
I don't have good suggestions as far as naming those, though. I think calling them minHeap and maxHeap exposes some of the implementation details.
Maybe have something like this? The priority queue would not conform to the Sequence protocol, yet rather have whatever q.orderedIncreasing() and q.orderedDecreasing() returns to conform to Sequence.
let q: PriorityQueue = ...
for elt in q.orderedIncreasing() {
// iterates from min to max
}
for elt in q.orderedDecreasing() {
// iterates from max to min
}
Assuming we are exposing the underlying heap as var unorderedElements: [Element], the naming of q.orderedIncreasing() and q.orderedDecreasing would follow in the same fashion.
For brevity, however, it might be better just to have it as q.increasing() and q.decreasing() as saying "increasing"/"decreasing" already implies that it is ordered.
Meta question: does this sort of discussion belong in the forums or would we rather it happen here?
I think discussion here is better, as we would be able to see code changes and implementation suggestions all in one place.
Other possible naming options: ascendingElements/descendingElements, or increasingElements/decreasingElements. I think the former of these two could go better together with the Foundation type ComparisonResult with its cases orderedAscending etc.
Other possible naming options:
ascendingElements/descendingElements, orincreasingElements/decreasingElements. I think the former of these two could go better together with the Foundation typeComparisonResultwith its casesorderedAscendingetc.
I also like riffing off of ascending and descending. I think we can get away with dropping the "elements" suffix and parenthesis. For example, OrderedSet has an unordered view.
That would leave us with:
let q: PriorityQueue<Element> = ...
let heap: [Element] = q.unordered // direct read-only access to the underlying heap array
for elt in q.ascending { ... } // a sequence that iterates from min to max
for elt in q.descending { ... } // a sequence that iterates from max to min
I think I still prefer heap to unordered because it provides additional useful information (the elements aren't arbitrarily unordered like a hash table). However, this seems to me like a solid direction regardless of the names. I think @AquaGeek, you should proceed with your preferred names.
Meta question: does this sort of discussion belong in the forums or would we rather it happen here?
I think discussion here is better, as we would be able to see code changes and implementation suggestions all in one place.
I think this discussion is working well in this thread—we seem to be making progress and converging. If we find ourselves at a stalemate, that might be a good time to gather more opinions by bringing it to the forums. And before we merge the PR, it'd prob be good to solicit feedback and do some kind of API review on the forums.
@AmanuelEphrem Do you want to work on implementing ascending and descending and open a PR against my branch? I was thinking of returning an Iterator from both of those that conforms to both IteratorProtocol and Sequence:
extension PriorityQueue {
public struct Iterator: IteratorProtocol, Sequence {
private var _base: PriorityQueue
private let _direction: IterationDirection
[…]
}
var ascending: Iterator {
Iterator(_base: Self, _direction: .ascending)
}
var descending: Iterator {
Iterator(_base: Self, _direction: .descending)
}
}
I'll work on adding the performance tests.
@AmanuelEphrem Do you want to work on implementing
ascendinganddescendingand open a PR against my branch? I was thinking of returning anIteratorfrom both of those that conforms to bothIteratorProtocolandSequence:
Yes! I was thinking of the exact same implementation as well.
Here's a first pass at performance tests:
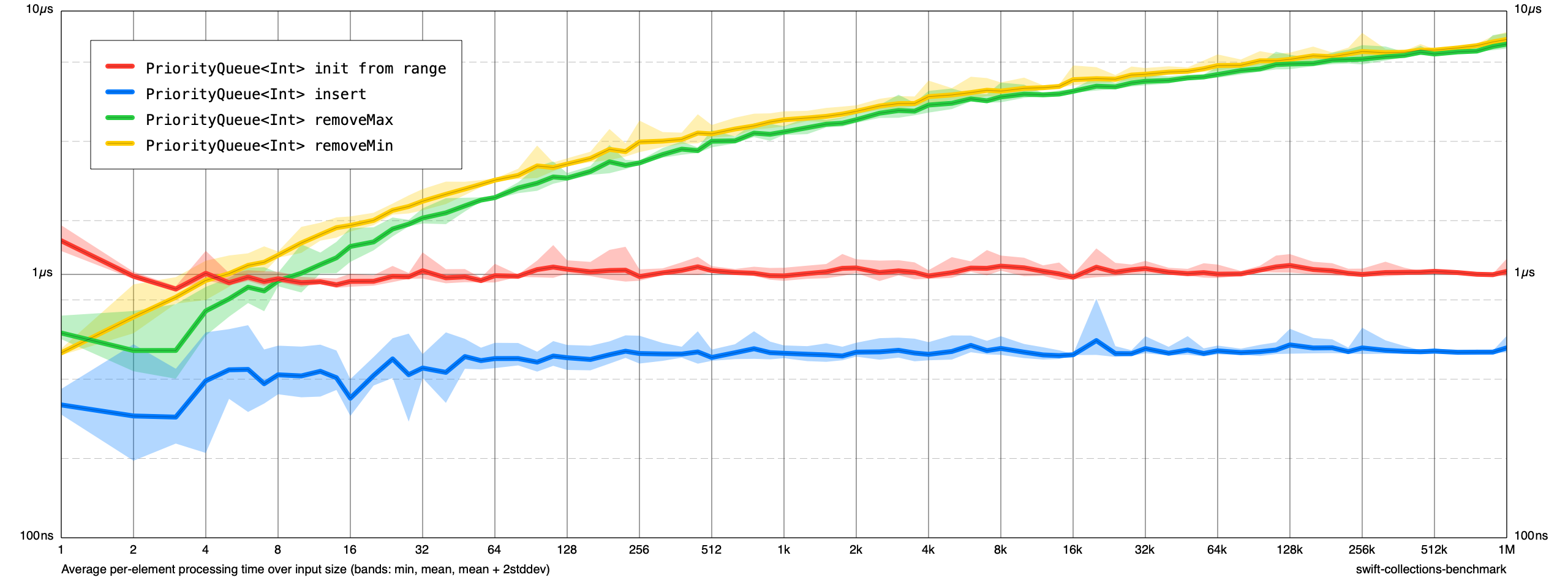
Interesting! Out of curiosity what hardware is this running on? (And to confirm it is built in release mode?)
Interesting! Out of curiosity what hardware is this running on? (And to confirm it is built in release mode?)
This was run on a 2019 MacBook Pro (2.3 GHz 8-Core Intel Core i9). Yes, it was built in release mode.
Here's a first pass at performance tests:
@AquaGeek Nice! It'd be great to see how the performance compares to CFBinaryHeap for equivalent operations (e.g. CFBinaryHeapAddValue and CFBinaryHeapGetMinimum)!
@AquaGeek Nice! It'd be great to see how the performance compares to CFBinaryHeap for equivalent operations (e.g.
CFBinaryHeapAddValueandCFBinaryHeapGetMinimum)!
@kylemacomber Here's a quick pass at adding CFBinaryHeap implementations. I'll get the code added here shortly. Somebody definitely needs to check my work here — take the benchmarks with a hefty grain of salt.
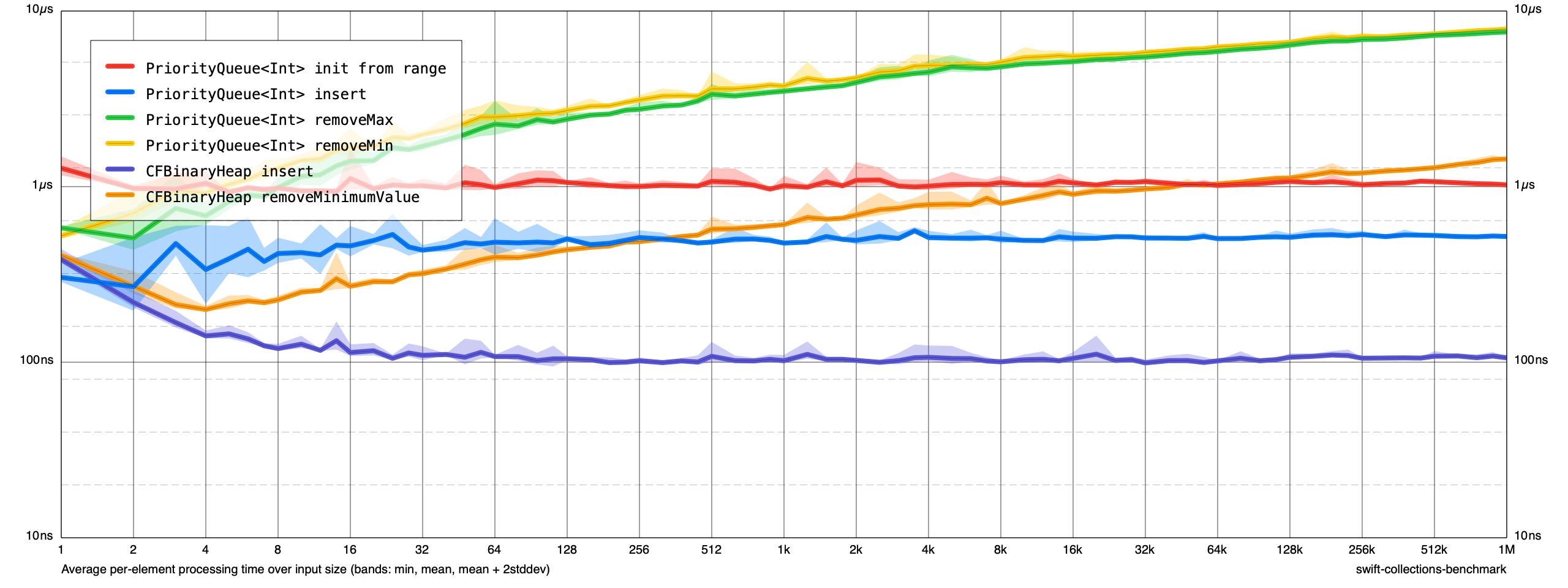
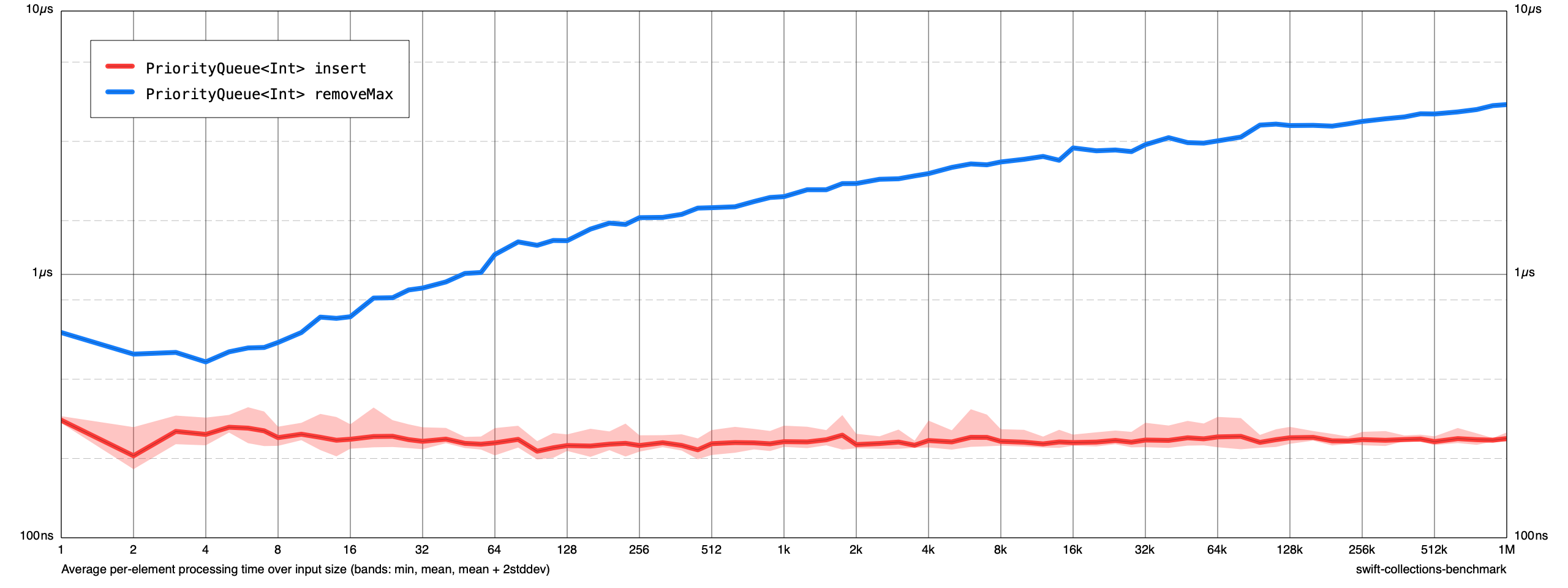
I just spent a little time profiling a bit (as the benchmark runtime seems quite long compared to the C++ version referenced in the article linked to previously), there seems to be an issue with using swapAt: (probably the same issue discussed here) - I just did a simple measurement of PriorityQueue<Int> insert and could see around 7.5M transient allocations. Doing the simple change of manually doing the swapAt: like this in all places:
storage.swapAt(largestDescendantIdx, index)
changed to
let tmp = storage[index]
storage[index] = storage[largestDescendantIdx]
storage[largestDescendantIdx] = tmp
brought this test down to 165K transient allocations and the runtime was basically halved.
And the original benchmark went from:

to:
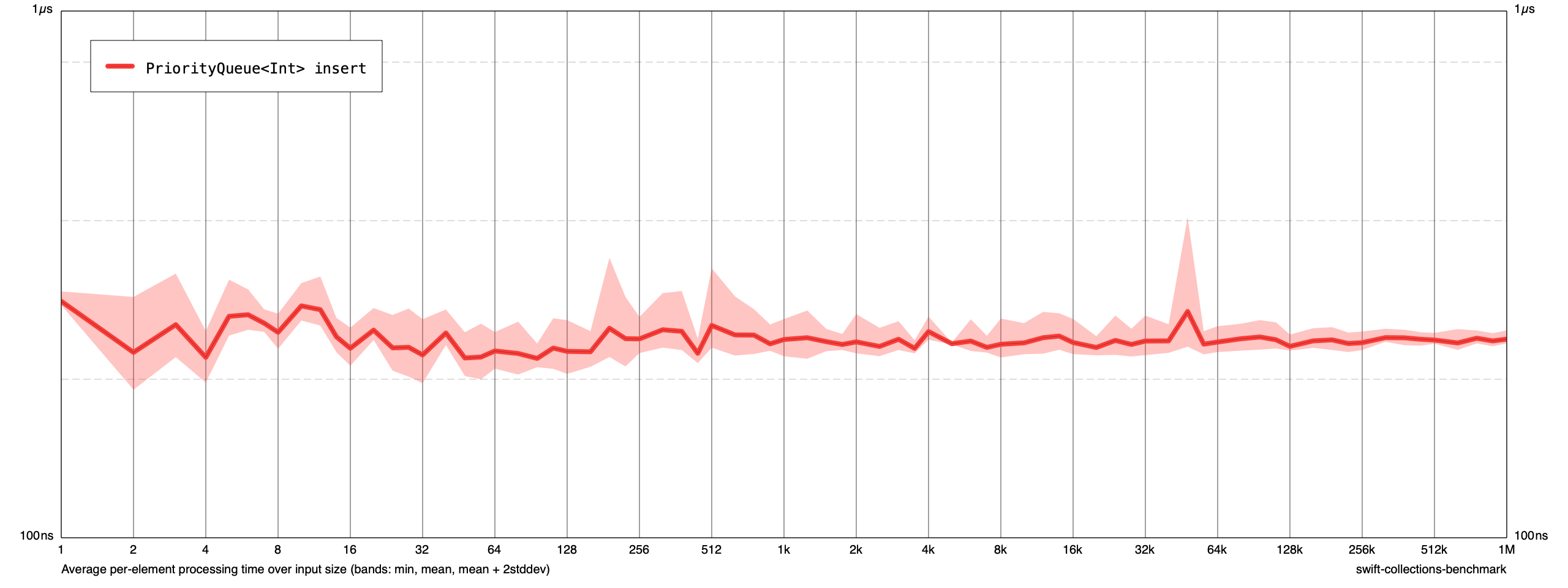
Not sure if this is a known issue with the swapAt: method, but it seems a bit rough to force two memory allocations per swapAt: operation for a simple small value type.
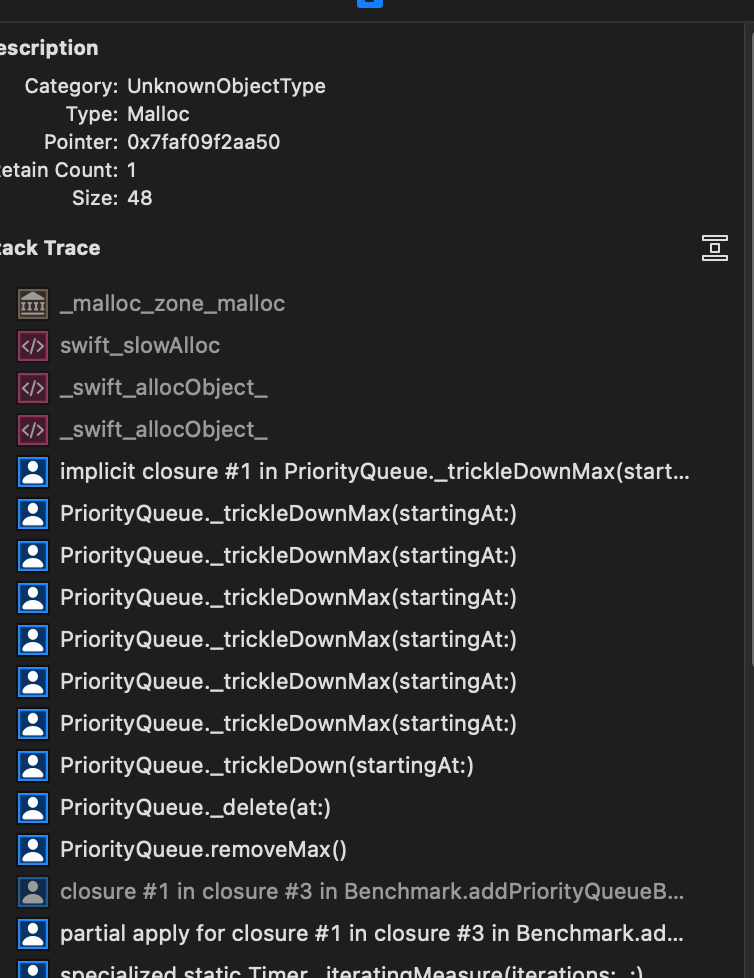
Also, looking at the removeMax test, there is also a large amount of transient allocations with this backtrace, can't quite understand why though (haven't looked at any others yet).
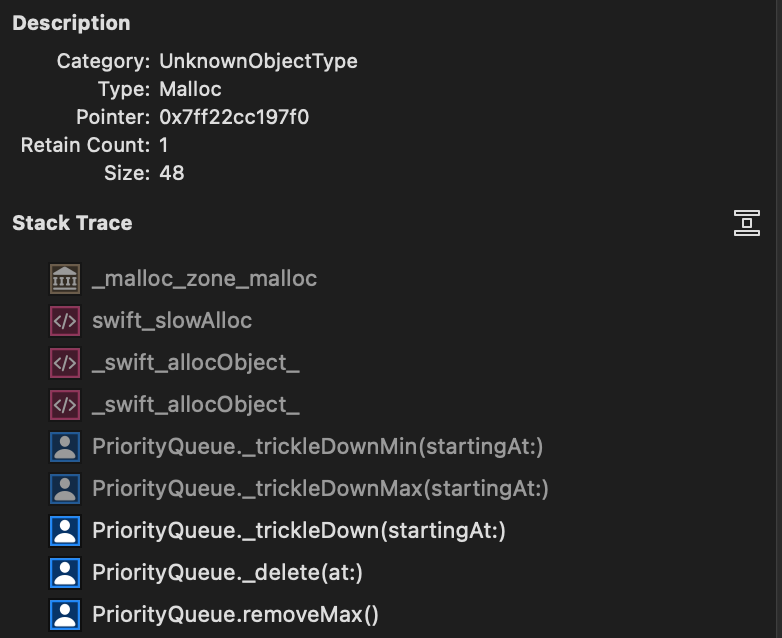
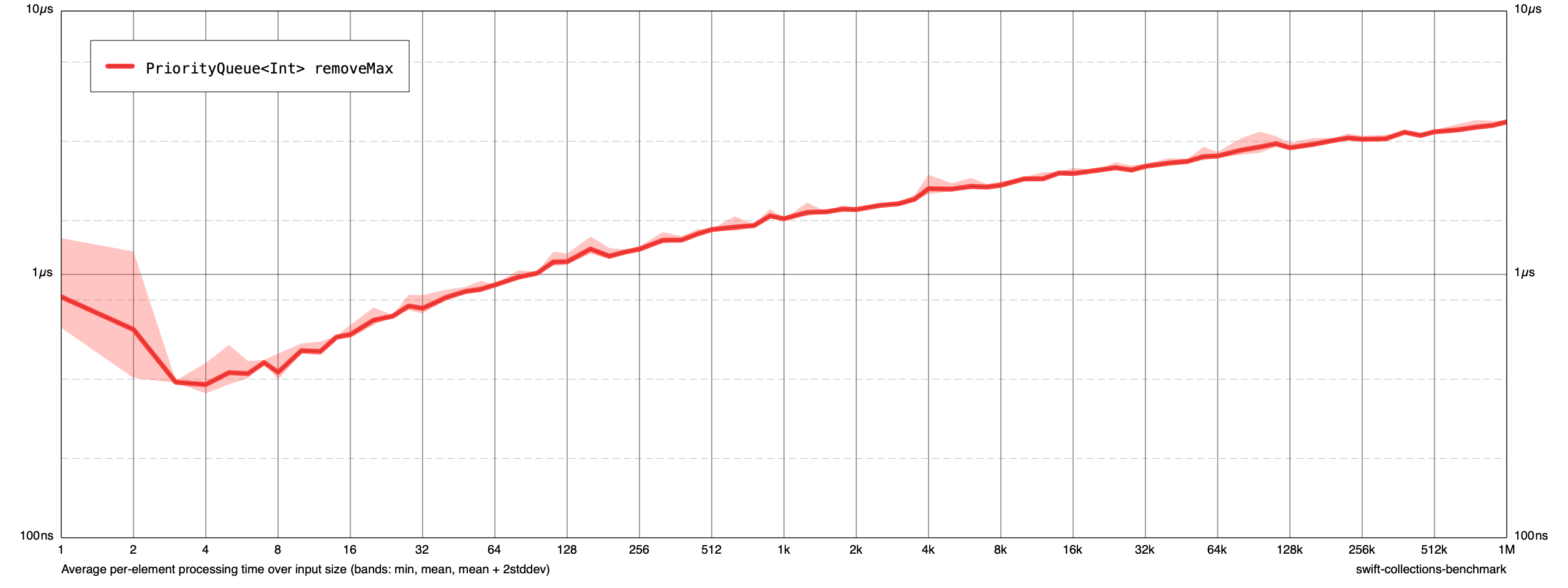
Tracked down the removeMax transient allocations too (disable inlining of _trickleDownMax and used Instruments), removing them changed the runtime for one iteration of the benchmark from from 95s -> 83s (and removed several M allocations too).
It was triggered by a couple of guard statements looking like:
guard let (smallestDescendantIdx, isChild) = _indexOfChildOrGrandchild(of: index, sortedUsing: <) else {
return
}
So I just tried remove 'sortedUsing' and created two duplicate methods for _indexOfChildOrGrandchild (one for greater, one for less than) and the allocations went away (it seems an implicit closure is created by passing the operator function as an argument which caused all the allocations).
storage.swapAt(largestDescendantIdx, index)
I wonder if storage.withUnsafeMutableBufferPointer { $0.swapAt(largestDescendantIdx, index) } would also exhibit the excessive allocations problem?
storage.swapAt(largestDescendantIdx, index)
I wonder if
storage.withUnsafeMutableBufferPointer { $0.swapAt(largestDescendantIdx, index) }would also exhibit the excessive allocations problem?
I gave it a spin, and it does not have the transient allocations - it does perform significantly worse though at 7.7s instead of ~6s for the manually inlined version of swapAt (vs ~12s with the transient allocations using swapAt).
@AquaGeek for the swapAt: issue, I tried the following with good results - add a helper method:
@inline(__always)
private mutating func _swapAt(_ first: Int, _ second: Int) {
let tmp = self.storage[first]
self.storage[first] = self.storage[second]
self.storage[second] = tmp
}
and just change the call site from:
storage.swapAt(smallestDescendantIdx, index)
to
self._swapAt(smallestDescendantIdx, index)
it does perform significantly worse though at 7.7s instead of ~6s for the manually inlined version of swapAt
Interesting. I would think that the manually-inlined would do worse than the UMBP-calling version when used on types that do ARC, such as String. The specialization of swapAt on UMBP exists partly to explicitly avoid ARC traffic, and to not rely on the optimizer to remove it. It looks to me like the optimizer still can't reliably do that.
Looking at the generated code of the following on godbolt:
var a = [1,2,3,4,5]
var b = a.map(String.init)
var c = b
var d = b
extension Array {
@inlinable @inline(__always)
public mutating func _swapAt(_ first: Int, _ second: Int) {
let tmp = self[first]
self[first] = self[second]
self[second] = tmp
}
}
@inline(never)
func sa(_ a: inout [Int]) {
a._swapAt(0, 3)
}
@inline(never)
func sb(_ b: inout [String]) {
b._swapAt(0, 3)
}
@inline(never)
func sc(_ c: inout [String]) {
c.withUnsafeMutableBufferPointer { $0.swapAt(0, 3) }
}
@inline(never)
func sd(_ d: inout [String]) {
d.swapAt(0, 3)
}
sa(&a)
sb(&b)
sc(&c)
sc(&d)
sb and sd look about the same, while sc eliminates the retains and releases. Does it make sense to also benchmark PriorityQueue with a non-trivial type?
Interesting. In reality I’d personally probably end up using a simple struct with priority (Int) and then an index / key to a collection type for the actual entities in the priority queue - just to ensure cheap push/pop and no arc if keeping references. But it wouldn’t be bad testing it of course, as your use-case may vary.
Thank you to everyone who provided feedback on this. I have integrated most of it.
Remaining tasks:
- [x] Merge @AmanuelEphrem's
Sequenceconformance (waiting on some tweaks from his side) - [x] Reformat the code to match the 2 space indent/80 char width style
- [x] Optimize
_indexOfChildOrGrandchild(of:sortedUsing:)(probably by splitting it back out into 2 separate functions) - [x] Chase down suggestion from @timvermeulen about skipping nodes that have children
- [x] Figure out if
@inlinableis required - [x] Add unit tests for heap invariants
- [x] Make a call on whether or not we want to add
removeMin/Maxas well asreplaceMin/Max - [x] Make
_minMaxHeapIsMinLevelan instance method - [x] Investigate making
_bubbleUpMin(startingAt:)iterative instead of recursive
Very cool @AquaGeek, will play a bit now with the latest version! :-)
Just in case it was missed as it was part of a different comment above and now marked resolved, @timvermeulen suggestion on an iterative implementation of e.g. mutating func _bubbleUpMin(startingAt index: Int) { might be worth investigating too?
@AquaGeek I found a way to keep _indexOfChildOrGrandchild as a single method while removing the transient allocations with minimal changes.
EDIT: It seems still faster to split into two methods as you planned, so just for reference the below fixed the allocs, but is still slower - the extra branch was costly as it seems.
- Change the signature of the method to:
@inline(__always)
private func _indexOfChildOrGrandchild(of index: Int, greaterThan: Bool) -> (index: Int, isChild: Bool)? {
The previous predicate code becomes:
// if predicate(storage[rightChildIdx], storage[leftChildIdx]) {
if greaterThan ? storage[rightChildIdx] > storage[leftChildIdx] : storage[rightChildIdx] < storage[leftChildIdx] {
and
// if predicate(storage[i], storage[result.index]) {
if greaterThan ? storage[i] > storage[result.index] : storage[i] < storage[result.index] {
And finally the two call sites changes to:
guard let (largestDescendantIdx, isChild) = _indexOfChildOrGrandchild(of: index, greaterThan: true) else {
guard let (smallestDescendantIdx, isChild) = _indexOfChildOrGrandchild(of: index, greaterThan: false) else {
This removes the transient allocations and significantly drops the execution time.
FYI, I've looked a bit more on the transient allocations in removeMax now, it seems the Array triggers copy-on-write even if it shouldn't sometimes:
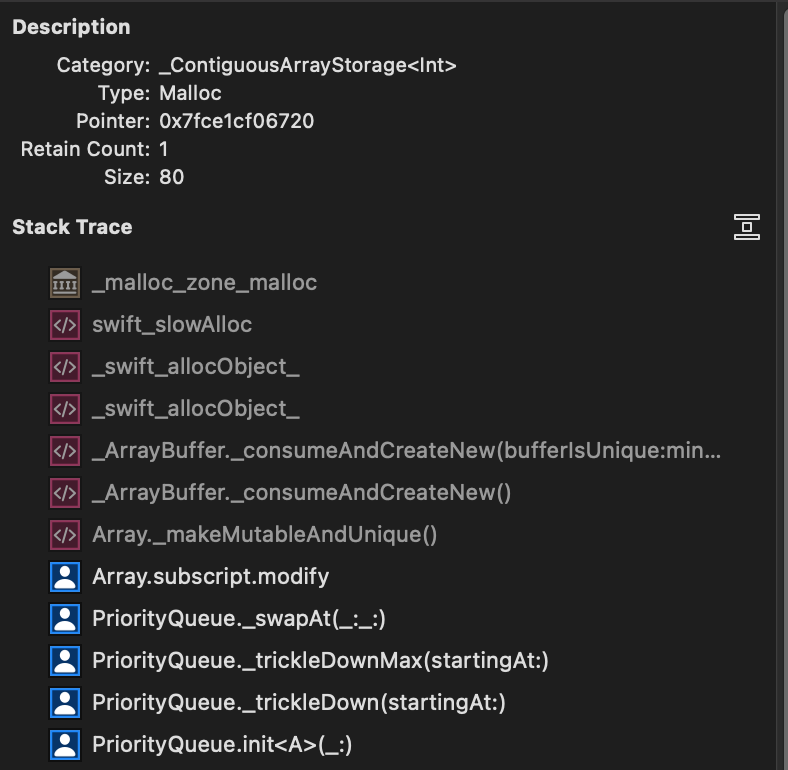
(closest issue I found was https://bugs.swift.org/browse/SR-14062, but unclear if it is the same - will dig a bit more)
Just in case it was missed as it was part of a different comment above and now marked resolved, @timvermeulen suggestion on an iterative implementation of e.g.
mutating func _bubbleUpMin(startingAt index: Int) {might be worth investigating too?
Ooops. I had missed that when I was making the list. Thanks for reminding me @hassila!
public mutating func insert<S: Sequence>(contentsOf newElements: S) where S.Element == Element
I was trying to figure out if there is a performant way to do this — build a heap out of the new sequence and then merge the two?
[ ] Figure out if
@inlinableis required
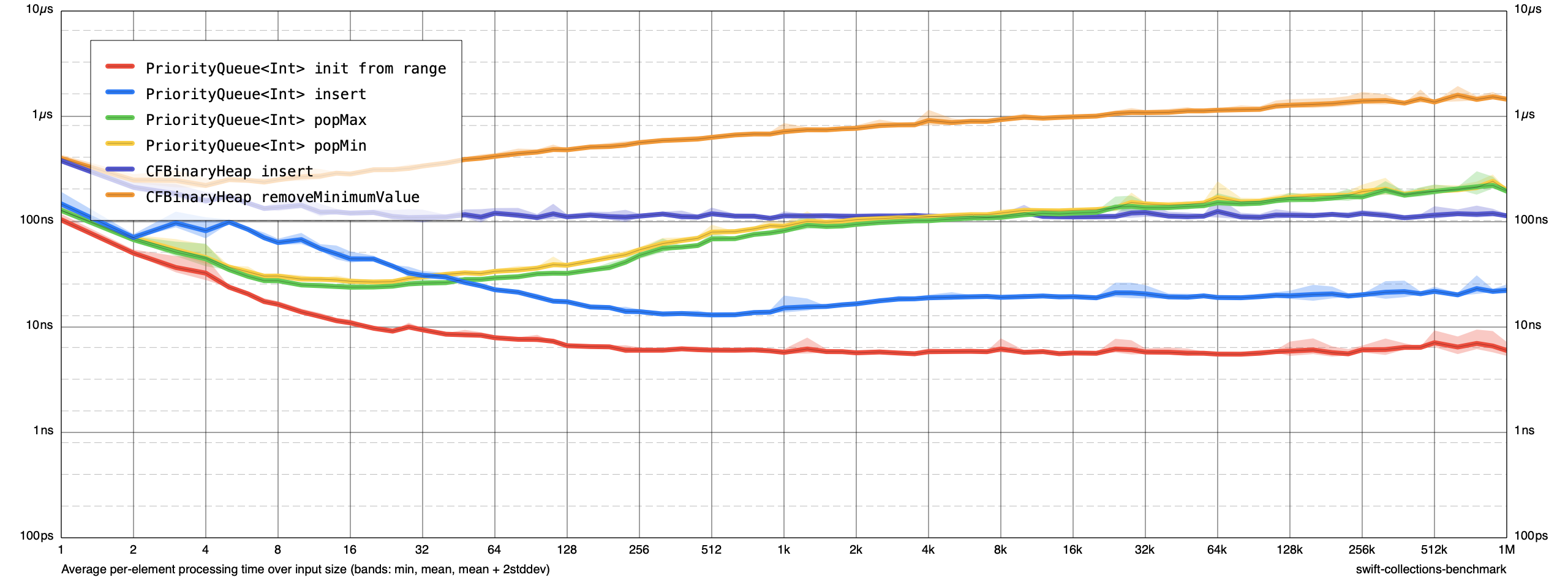
@inlinable is definitely required and it dramatically improves performance!
I did a naive find and replace adding @inlinable to every method on PriorityQueue. Many operations are now 10-100x faster! It blows away CFBinaryHeap:
[ ] Figure out if
@inlinableis required
@inlinableis definitely required and it dramatically improves performance!I did a naive find and replace adding
@inlinableto every method onPriorityQueue. Many operations are now 10-100x faster! It blows awayCFBinaryHeap:
That was more like it! Awesome. Should revisit iterative vs recursive implementation again (I can do that tomorrow, have done it for a few methods with no real wins, but proper inlining may change that) - wonder how many are missing this given the comment I found googling the forums...
OK, I marked everything as @inlinable in c33273f80c341c9c61c997dfe2daca8e88c5a5ac. Test results now are much better and in-line with what @kylemacomber got:
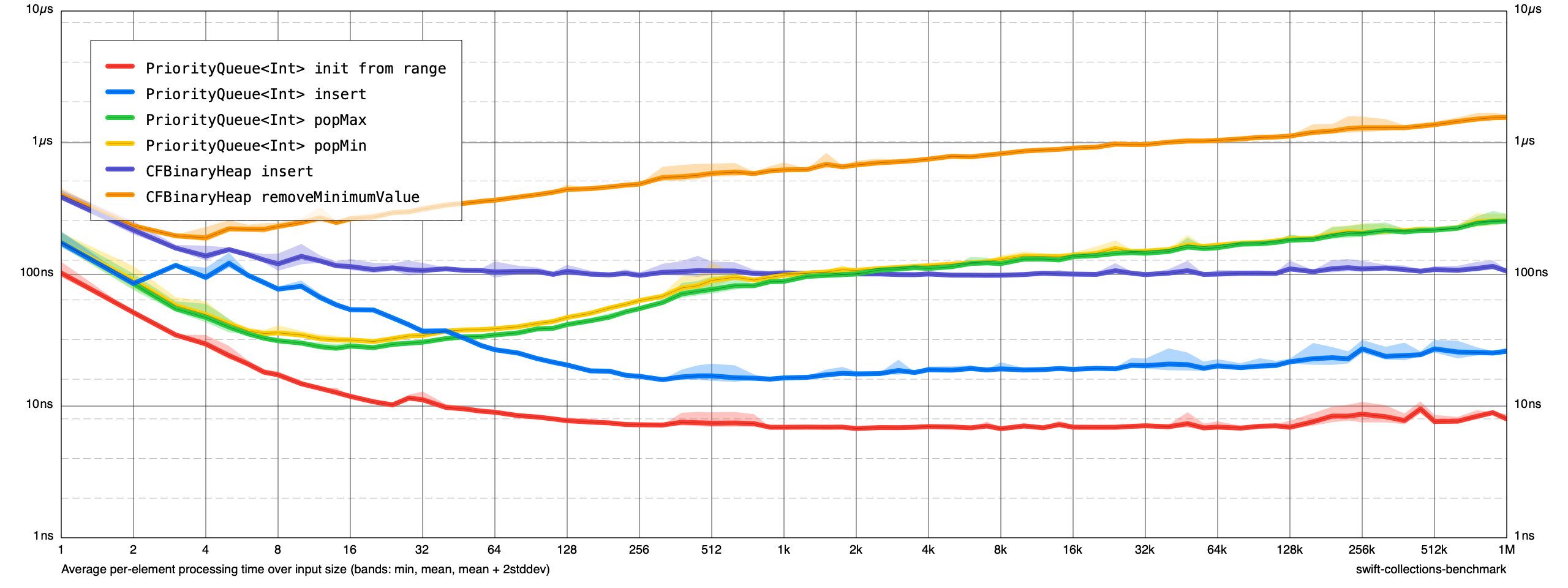
I did an iterative implementation as a test, seems to give a noticeable improvement when done together with some extra inlining. Created https://github.com/AquaGeek/swift-collections/pull/2 for your consideration @AquaGeek if you want it.
Recursive:

Iterative:

Found out that the nice benchmark framework could do a better diff - updated performance numbers in PR (20-35% approximately).
OK, @hassila's "iterative instead of recursive" PR has been merged. I think the only thing left here is to add invariant tests. I was planning on following the approach taken in some of the other data structures:
// PriorityQueue+Invariants.swift
extension PriorityQueue {
#if COLLECTIONS_INTERNAL_CHECKS
@inlinable
@inline(never)
internal func _checkInvariants() {
// TODO: Check that the layers in the min-max heap are in the proper order
}
#else
@inlinable
@inline(__always)
public func _checkInvariants() {}
#endif // COLLECTIONS_INTERNAL_CHECKS
}
OK, invariant checks have been added. Anything else we need to address here? (cc/ @kylemacomber)
public mutating func insert<S: Sequence>(contentsOf newElements: S) where S.Element == ElementI was trying to figure out if there is a performant way to do this — build a heap out of the new sequence and then merge the two?
I think it's fine to just add the naive loop that calls insert for every element in the sequence to start. Since we don't have to worry about ABI stability, it's trivial to substitute the implementation with a more efficient algorithm in the future.
OK, invariant checks have been added. Anything else we need to address here? (cc/ @kylemacomber)
This is our first big addition to the collections package, so there's not really any existing precedent, but I think it'd be great to do an API review on the collections section of the forums to finalize the names.
I think something similar to the review of the FilePath Syntactic APIs would work well. Nothing too fancy—just a dump of all the public APIs and their doc comments along with a little commentary. We should include at least couple example uses of PriorityQueue (either in the doc comments or the commentary)!
This is our first big addition to the collections package, so there's not really any existing precedent, but I think it'd be great to do an API review on the collections section of the forums to finalize the names.
I think something similar to the review of the FilePath Syntactic APIs would work well. Nothing too fancy—just a dump of all the public APIs and their doc comments along with a little commentary. We should include at least couple example uses of
PriorityQueue(either in the doc comments or the commentary)!
OK, here's the WIP doc for the review. I need to fill in the details about the structure of the min-max heap and add some example usages. Once that's done I'll post it on the forum.
Looks like a very nice start @AquaGeek - maybe append the latest performance measurements too as it will likely be one of the first questions? I can run the latest with a larger set of runs on an Intel box if you want (just let me know), would be cool to have M1 numbers too (don't have access unfortunately).
Looks like a very nice start @AquaGeek - maybe append the latest performance measurements too as it will likely be one of the first questions? I can run the latest with a larger set of runs on an Intel box if you want (just let me know), would be cool to have M1 numbers too (don't have access unfortunately).
I don't have access to an M1, either. I'll re-run the benchmarks on my MBP and include those in the forum post (good call there!); I think that'll be fine for now. If you want to run any additional benchmarks you can post a follow-up in the thread with your results.
It looks like _minMaxHeapIsMinLevel is always called with a +1 at the call-site, as in:
_minMaxHeapIsMinLevel(index + 1)
Would it make sense to move the +1 into the implementation of _minMaxHeapIsMinLevel, so that call-sites can just pass in index rather than having to remember to add one first?
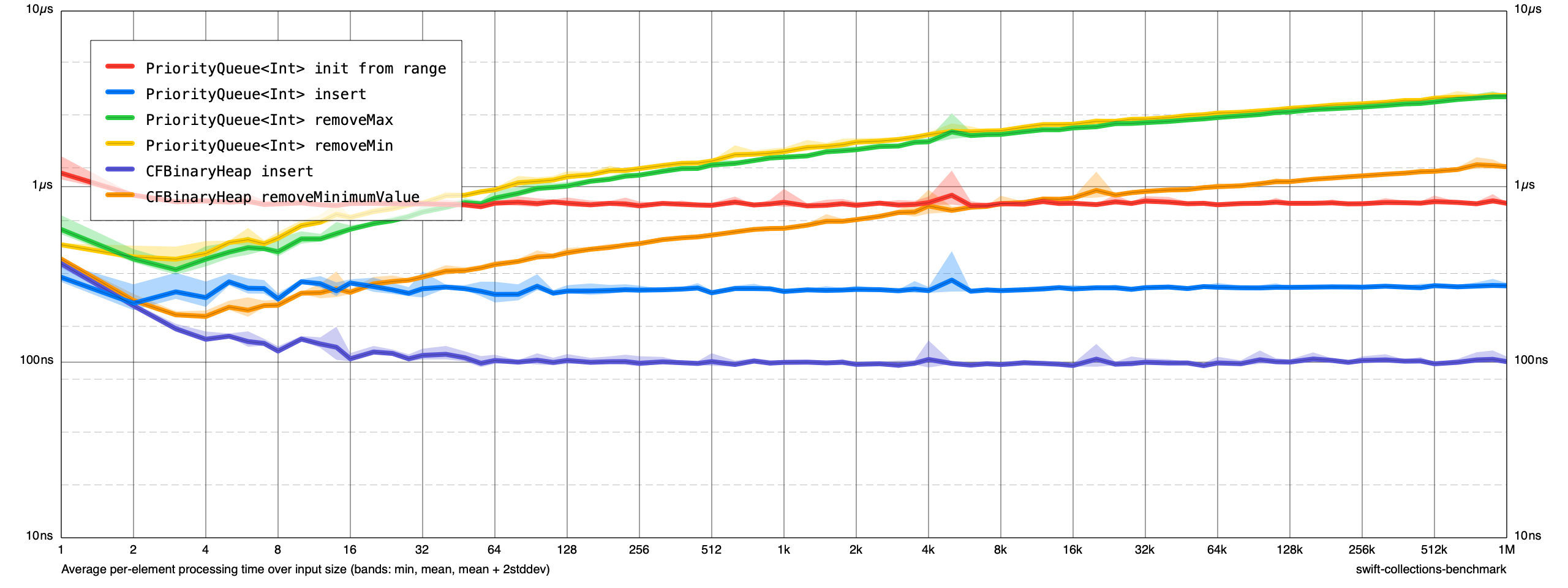
There is one thing I wonder about the performance tests - maybe a question for @lorentey if this is possible to do - looking at the output graphs from typical benchmarks, the actual construction time for the data structure is included such that we start of with a high per-item runtime (100+ns, see e.g https://forums.swift.org/t/api-review-priorityqueue-apis/49932/10) which then goes down over time for larger amount of tested items as the setup cost is amortised over the number of items.
It is interesting to know what the creation/destruction overhead is for a data structure (also as a function of "n" if reserving a certain capacity for creation and to understand if destruction is inefficient), but wouldn't it make sense to break that out into separate benchmark tests typically and keep the normal operation testing without that overhead?
It would be a more natural looking graph for most I think?
@NevinBR Would it make sense to move the
+1into the implementation of_minMaxHeapIsMinLevel, so that call-sites can just pass inindexrather than having to remember to add one first?
Yeah, I went back and forth on this. I ended up pushing it onto the callers because the calculation is ultimately based on the count of items, not the index. I don't have strong feelings about it either way, though if we leave the responsibility of adding one on the callers we should probably require the parameter name in the call:
_minMaxHeapIsMinLevel(count: index + 1)
// Instead of:
_minMaxHeapIsMinLevel(index + 1)
In the Swift Forums discussion thread for this type, I suggested adding an element search method. I put it in a pull request to the repo this pull request is based on: AquaGeek#3.
the calculation is ultimately based on the
countof items, not the index.
That seems…needlessly pedantic to the point of causing confusion to readers.
The caller is working with an index, and wants to know “Is this index in a min-level or a max-level?”
That seems…needlessly pedantic to the point of causing confusion to readers.
The caller is working with an index, and wants to know “Is this index in a min-level or a max-level?”
I couldn't agree more — it's immediately clear what it means for a node to be on a min-level or a max-level for anyone even slightly familiar with how this data structure works. "Returns true if count elements falls on a min level" is a bit of an awkward description, at least to me, because I have no intuition for what it could mean for count elements to fall on a certain level.
The count > 0 precondition and the + 1 in every single call site are also pretty good indicators that taking an index instead would simplify the code.
It is interesting to know what the creation/destruction overhead is for a data structure (also as a function of "n" if reserving a certain capacity for creation and to understand if destruction is inefficient), but wouldn't it make sense to break that out into separate benchmark tests typically and keep the normal operation testing without that overhead?
It would be a more natural looking graph for most I think?
I think I would rather say that having constant overheads show up in the regular benchmark is the most useful/honest approach -- after all, separating these out would hide a very large component of performance at small sizes, which would be misleading.
In cases where a certain calculation isn't relevant, the benchmark ought to be manually written so that the calculation occurs outside of the scope of measurement. (In the case of an insertion benchmark, this can be done by reserving capacity before the measurement begins, and using withExtendedLifetime to also ignore deinitialization costs. This ought to be just one variant of the benchmark though -- in real world cases, allocation/deallocation costs are very much relevant, and it isn't always possible/desirable to call reserveCapacity.)
In cases where the extra calculation cannot be separated from the thing we're measuring, then why exactly would we want to hide it? Artificially massaging benchmark curves to better match the expected asymptotic behavior at small sizes wouldn't be useful. Most real-world charts that plot average per-element time naturally have a lopsided U shape -- getting rid of the initial downward slope by tweaking the benchmarking methodology would be a non-goal, I think.
OK, I've integrated most of the feedback and split MinMaxHeap<Element: Comparable> from PriorityQueue<Value, Priority: Comparable>. My changes are on a separate branch if anyone wants to have a look.
@kylemacomber and @lorentey: How do you want to proceed from here?
- Should I merge those changes into this same
priority-queuebranch and continue the review in this PR? - How do you want to handle @CTMacUser's PR (AquaGeek/swift-collections#3)? Do you want that to be part of this chunk of work, or do you want to review/merge it separately?
- How do you want to handle the significant changes involved in splitting the two types apart again in regards to the API review in the forum? Should that topic be closed as "returned for review" and a new one opened once we've reached a good point on the code side with the full API docs again of both types, or should I update that thread with the updated docs for the two types?
- @kylemacomber you mentioned adding
Collectionconformance. I think I'd prefer that to happen as a separate unit of work. Thoughts? - Should
replaceMinandreplaceMaxto be added as part of this initial chunk of work? (Again, I think I'd prefer that those be follow-up PRs.)
Thanks in advance!
Here are preliminary benchmarks of PriorityQueue<Value, Priority> vs MinMaxHeap<Element> vs CFBinaryHeap:
Insertions
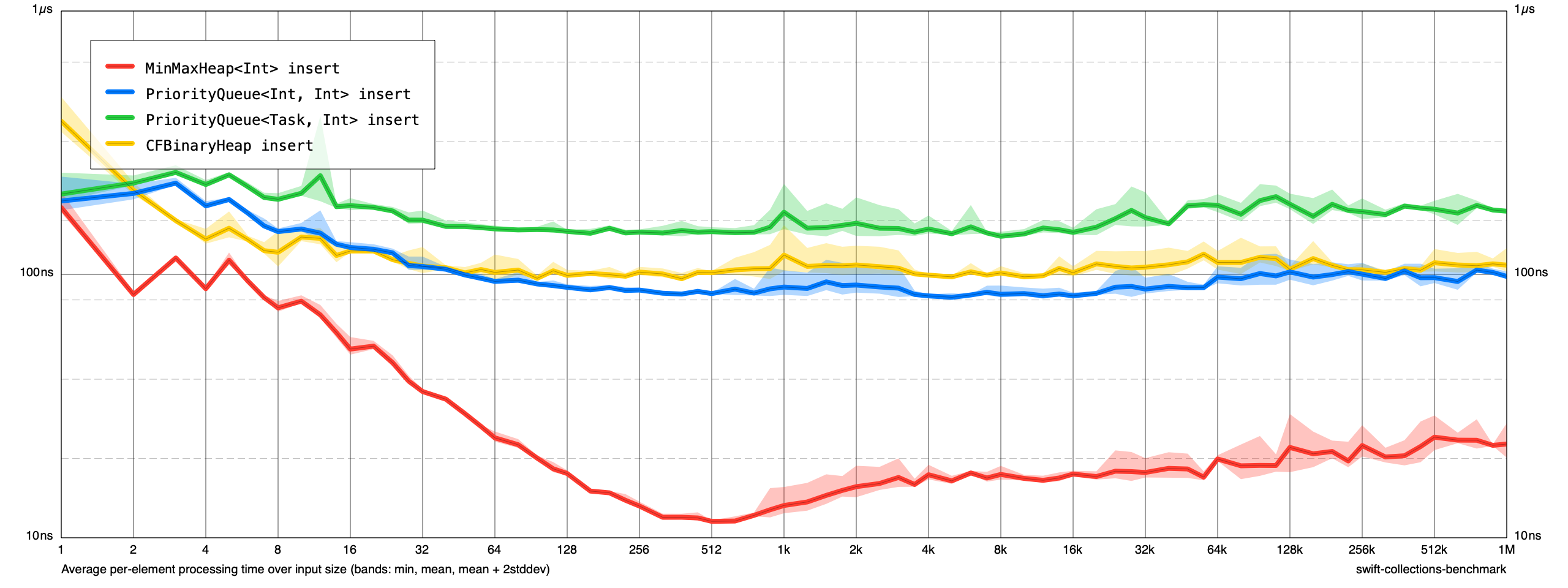
Removals
I'm open to other directions, but I think it might be good to rename this type to Heap and land it with no additional features (maybe into a PriorityQueue feature branch). Then we can open up other PRs for the PriorityQueue work and some of the other enhancements people have proposed.
Also it might be worth including the API review document as part of this initial commit.
I think I would rather say that having constant overheads show up in the regular benchmark is the most useful/honest approach -- after all, separating these out would hide a very large component of performance at small sizes, which would be misleading. ...
In cases where the extra calculation cannot be separated from the thing we're measuring, then why exactly would we want to hide it? Artificially massaging benchmark curves to better match the expected asymptotic behavior at small sizes wouldn't be useful. Most real-world charts that plot average per-element time naturally have a lopsided U shape -- getting rid of the initial downward slope by tweaking the benchmarking methodology would be a non-goal, I think.
Thanks for the reply - the reason for "hiding it" would be that many performance sensitive implementations recycle data structures to remove the init/deinit overhead - in this particular case, we'd probably have a long life cycle for the priority queues, but constantly add/remove a smallish number of items (perhaps 10-10.000 depending on load), so the performance characteristics for long-lived data structures where you have a smallish amount of data items are effectively opaque as the init/deinit overhead overshadows the actual run time for the operations.
But I'm not really arguing for hiding it completely, but rather suggest that it might be interesting to understand init/deinit costs for the data structure separately from the actual operation - I was just thinking it might make sense to split that out to a separate test (init/deinit times for data structure with N elements), fundamentally splitting the current single curve into three curves, one for init, one for deinit, one for the actual real processing (which would be relevant for long-lived structures). That would allow users with long-living data structures to understand performance characteristics as well as users who have transient data structures (who would need to look at two or all three of the curves in that case).
Anyway, I'll be ok with the current setup too, one gets a worst-case performance estimate when looking at the lowest point of the curve - thanks for explaining your reasoning.
- Should
replaceMinandreplaceMaxto be added as part of this initial chunk of work? (Again, I think I'd prefer that those be follow-up PRs.)
@AquaGeek For what it's worth, I've written a draft implementation for those here. But I agree about landing the data structure first, also because there are some unresolved questions that we'd need to answer 🙂
@kylemacomber I opened a new PR (#61) with just the Heap (and all the commits leading to that). I figure we can retarget that to a new priority-queue branch if needed. Do we want to do another separate API review for that in the forums, or is the feedback we received from the PriorityQueue API review (and the changes to split the two types apart and loosen the Comparable requirement on the PriorityQueue element type) sufficient?
I think the only thing missing from that PR is extracting the API review doc/adding a write-up of the technical design to the Documentation directory.
OK, I've force-pushed the commits to this branch that add the priority queue implementation on top of Heap (which @lorentey merged yesterday 🎉). I'll need to take a pass and update the docs (and there are probably a few other things I need to tweak), but it should be largely ready for re-review.
@AquaGeek In hindsight, I think the single huge library file isn't very useful -- I find I almost never want to generate benchmarks for every single data structure in this package (it's just too slow), but rather I concentrate on one collection at a time.
I started to split recent library additions into separate files -- for example, we have a smaller library specifically for Heap in the Benchmarks/Libraries/Heap.json file. It would make sense to add PriorityQueue benchmarks to that file, too. (I think it is okay not to update the primary library file -- I expect I'll eventually replace its contents with an inclusion mechanism, or just remove it altogether.)
I believe the PriorityQueue charts would work better as new additions, separate from the existing Heap ones. (I find a chart with more than 5-6 tasks is very hard to follow.) In addition to standalone charts that only show PriorityQueue tasks, we can also have a set of charts for Heap vs PriorityQueue comparisons for each (family of) operations. (It may be useful to make the Element type of Heap a custom struct combining the keys/values in PriorityQueue to make these fair. It's extra work though, and I don't think it's critical -- comparing against Heap<Int> would still be interesting. I don't think we need to directly compare PriorityQueue to C++ constructs, but that's an option too.)
@lorentey
@AquaGeek In hindsight, I think the single huge library file isn't very useful -- I find I almost never want to generate benchmarks for every single data structure in this package (it's just too slow), but rather I concentrate on one collection at a time.
Yeah. While I was going through this, I didn't fully understand how libraries work, so I was commenting out the irrelevant benchmarks in main.swift. 😆
I started to split recent library additions into separate files -- for example, we have a smaller library specifically for
Heapin the Benchmarks/Libraries/Heap.json file. It would make sense to addPriorityQueuebenchmarks to that file, too. (I think it is okay not to update the primary library file -- I expect I'll eventually replace its contents with an inclusion mechanism, or just remove it altogether.)
I originally had the benchmarks in the primary library file as well, but I removed them from that and created a new separate file for them (Benchmarks/Libraries/PriorityQueue.json).
I believe the
PriorityQueuecharts would work better as new additions, separate from the existingHeapones. (I find a chart with more than 5-6 tasks is very hard to follow.) In addition to standalone charts that only showPriorityQueuetasks, we can also have a set of charts forHeapvsPriorityQueuecomparisons for each (family of) operations. (It may be useful to make theElementtype ofHeapa custom struct combining the keys/values inPriorityQueueto make these fair. It's extra work though, and I don't think it's critical -- comparing againstHeap<Int>would still be interesting. I don't think we need to directly comparePriorityQueueto C++ constructs, but that's an option too.)
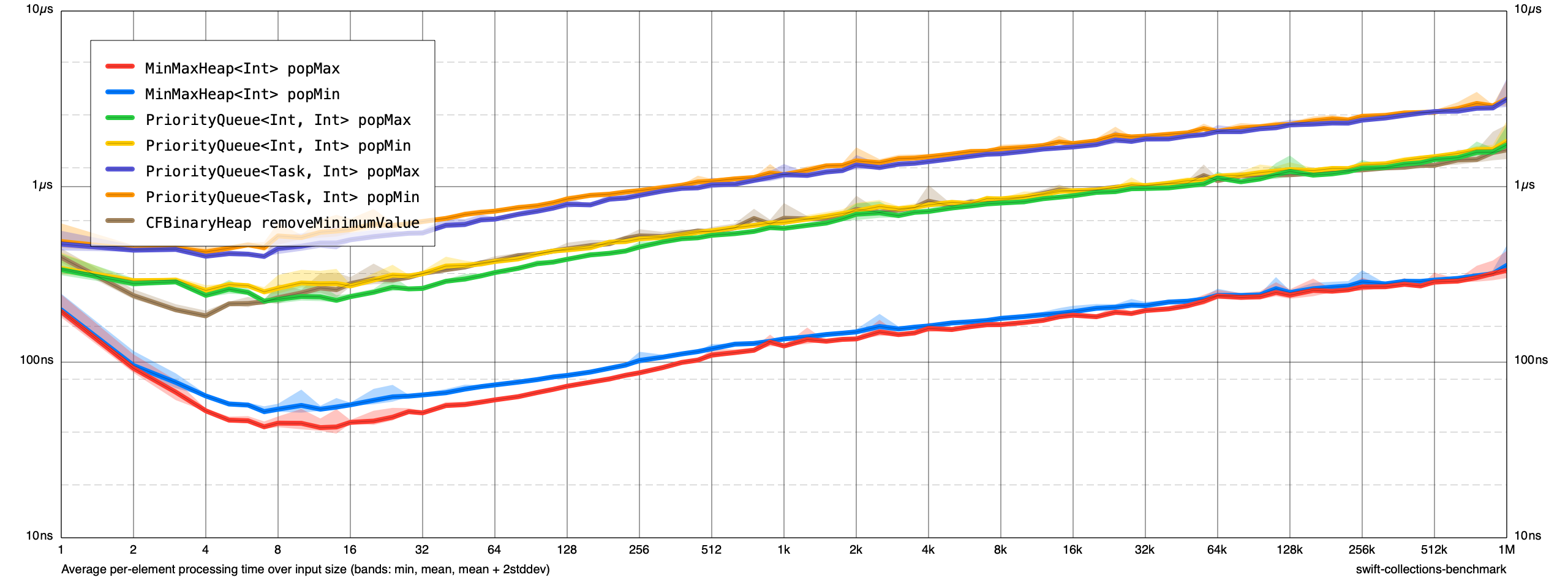
I updated the Heap benchmarks to also include ones for a small Task struct. Here are the comparative benchmarks (MacBook Pro (16-inch, 2019), 2.3 GHz 8-Core Intel Core i9):
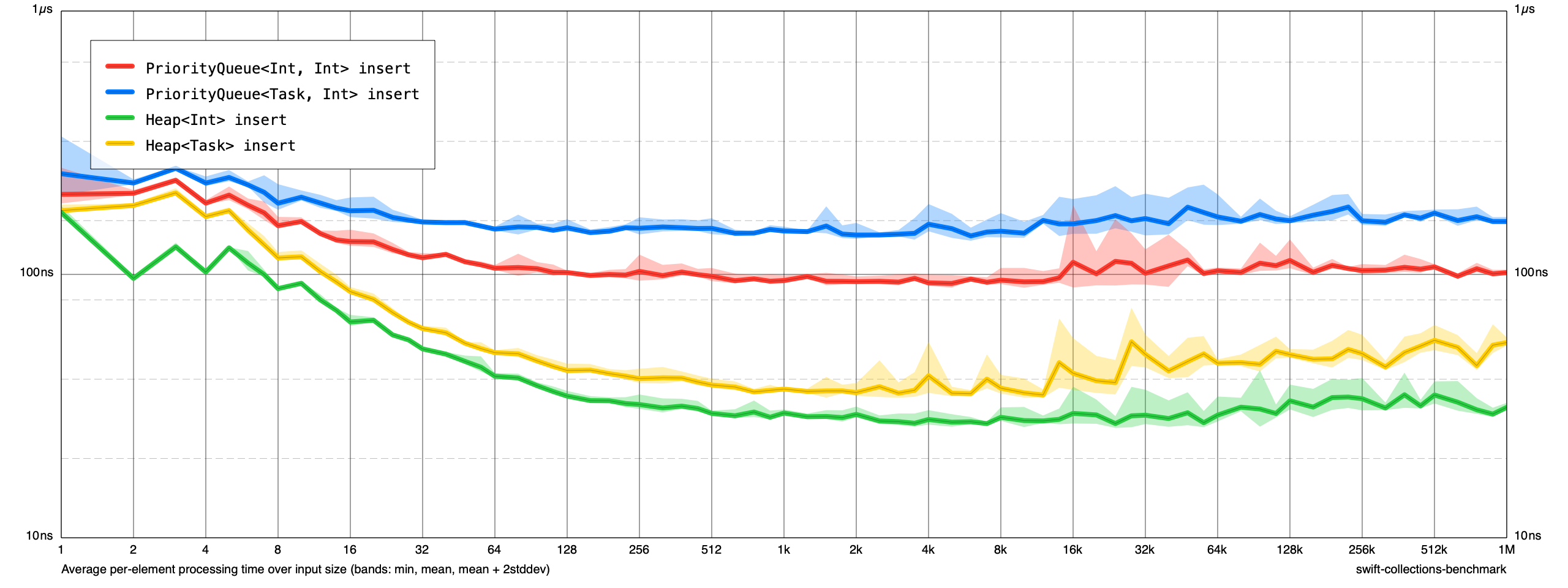
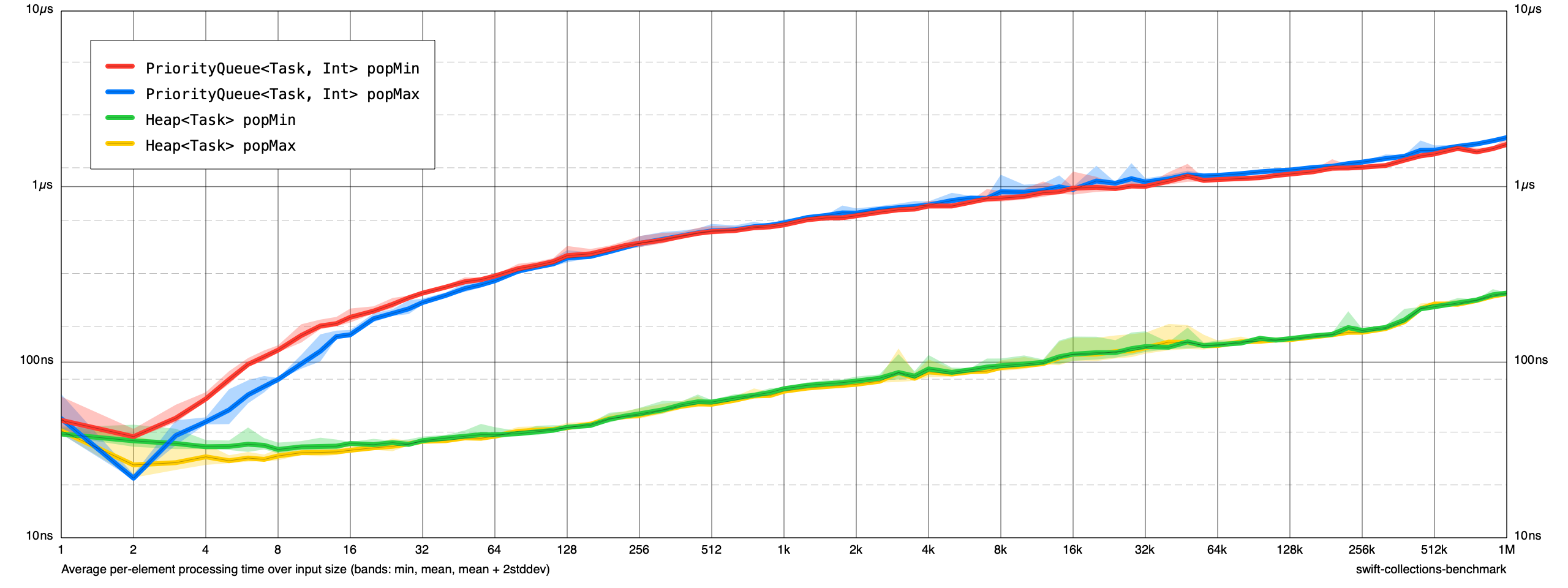
I rebased this branch on main (fc876e18c1637257f2b6665cf794c3fa8b2d410a). @lorentey is there anything else you need from me on this?
Given the other PRs, should we remove the ascending and descending views on the priority queue from the get-go?
@lorentey I rebased on main again and removed the ordered views from PriorityQueue.
What about decreasePriority/increasePriority functions? It's used by some algorithms, for example Dijkstras algorithm, to become faster.
What is the status of this PR, is it pending review still? @AquaGeek
Yes, it's still pending review. In particular, I'm looking for feedback on the best way to handle FIFO ordering — right now, I'm using a UInt64 insertion counter.
I'd love to get this landed.
@AquaGeek Have you considered using a timestamp such as Date() to enforce FIFO in case of equal priorities instead of the counter? What would be the disadvantages of that approach? I guess precision.
@AquaGeek Have you considered using a timestamp such as Date() to enforce FIFO in case of equal priorities instead of the counter? What would be the disadvantages of that approach? I guess precision.
I think that would be effectively the same thing but with the downside of depending on Foundation. There may be performance or space differences worth digging into.
@AquaGeek Have you considered using a timestamp such as Date() to enforce FIFO in case of equal priorities instead of the counter? What would be the disadvantages of that approach? I guess precision.
I think that would be effectively the same thing but with the downside of depending on
Foundation. There may be performance or space differences worth digging into.
If exploring this, I'd aim for using Instant then from 5.7 to keep it Foundation-free (https://github.com/apple/swift-evolution/blob/main/proposals/0329-clock-instant-duration.md). Space-wise it would be twice (128 bits), performance of getting the current time is fairly decent these days (used to suck big time), but hardly as cheap as maintaining a counter - which is the best thing I can think of at least for maintaining FIFO.