apollo-rs
 apollo-rs copied to clipboard
apollo-rs copied to clipboard
Streaming lexer
this is an exploration of streaming the lexer. The current parser first allocates the list of tokens, then reverses it, then transforms to a syntax tree.
With the benchmark I added, on current main ( 6e8e8a8 ) we're at:
test bench_peek_n ... bench: 11,620 ns/iter (+/- 344)
test bench_supergraph ... bench: 418,199 ns/iter (+/- 6,446)
Here's the flamegraph when parsing the supergraph:

We can see that a large part of the time is spent in allocations in the lexing phase.
In 57647fe963b4c830d70a125cd4a52af47854bce9 we see that we can avoid reversing by replacing the token Vec with a VecDeque (I think the errors will be generated in the wrong order here though).
Then we can remove that vec entirely in 81f94f4731ed2f8afbb67040137ccc2b8ae63a33 by transforming the Lexer into an iterator of Token or Error. The interesting thing here is that it's actually slower:
test bench_peek_n ... bench: 23,392 ns/iter (+/- 636)
test bench_supergraph ... bench: 725,191 ns/iter (+/- 27,976)
We can see in the global graph that we removed all allocations in the lexer:
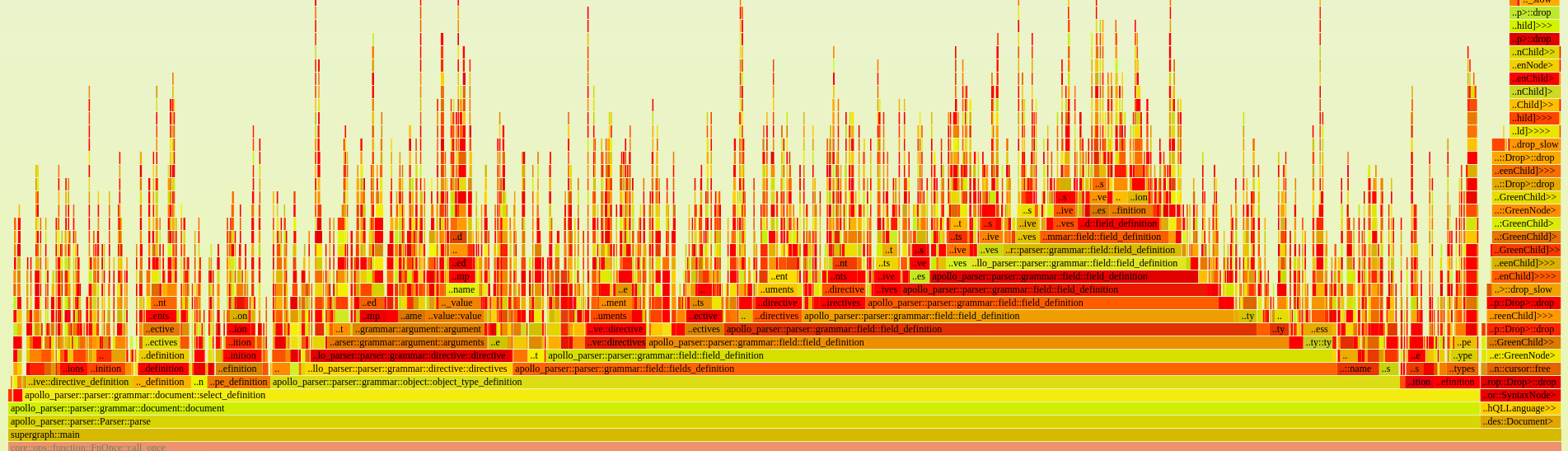
But if we zoom in, we see that the peek function is called very often:

The parser is calling that function regularly to make a decision when parsing the rest of the input. When tokens were preallocated, looking at the next one was nearly free but now we're reparsing it often.
So in e743184085414ca1a080ed06573f1c45ee3d31a8 we will store in Parser the next token when it is requested, to avoid reparsing it. The cost for that is fixed, it's only enough memory for one token, and we get better performance:
test bench_peek_n ... bench: 9,144 ns/iter (+/- 152)
test bench_supergraph ... bench: 297,023 ns/iter (+/- 11,814)
The graphs get smaller and we don't call peek as often.


To sump up: less allocations, between 20 and 30% improvement, no change in the syntax tree creation code, I feel good about that :)
I also think the Lexer is becoming a bit bulky. There is now a LexerIterator, LexerResult and a Cursor. I'd like to see if we can simplify this a bit and make it more readable. Using Read and Write directly is likely going to help with this.
I think I can replace the LexerResult with a std Result. Also, LexerIterator can be renamed Lexer, and I'll add a collect() method that produces vecs of tokens and errors
I would also like to see if the parser "navigation" functions, i.e. peek_token, peek_n, pop can be simplified a bit. I think the iteration can be done outside of the individual functions, e.g. parser.parse().
I'm looking at it, there are ways to simplify them. I'm not sure iterating should be done outside though, since we'd lose the benefit of streaming: iteration is driven by the needs of the tree builder
So I made the iterator the main lexer API now and added a .lex() method that returns a (Tokens, Errors) tuple. The public API is just for item in Lexer::new(source) or let (tokens,errors) = Lexer::new(source).lex().
For the Parser I think we can keep the lifetime for now, as the typical use case is to do:
let parser = Parser::new(source);
let tree = parser.parse();
And then you just use the tree, which is an owned structure. So you don't end up ever storing the parser with a lifetime on it.
When we add reparsing we can reconsider that, I think the API (from an ownership view, not the exact parameters) would roughly be this:
let mut parser = Parser::new(source); // ← already does the parse
let ast = parser.ast(); // get the already-parsed AST
parser.reparse(new_source);
Parser::new() can then return a structure that contains the owned syntax tree and doesn't need to reference the source string. So it should be easy to remove the lifetime then.