ZOOKEEPER-2789: Reassign `ZXID` for solving 32bit overflow problem
If it is 1k/s ops, then as long as $2^{32} / (86400 * 1000) \approx 49.7$ days ZXID will exhausted. But, if we reassign the ZXID into 16bit for epoch and 48bit for counter, then the problem will not occur until after $Math.min(2^{16} / 365, 2^{48} / (86400 * 1000 * 365)) \approx Math.min(179.6, 8925.5) = 179.6$ years.
However, i thought the ZXID is long type, reading and writing the long type (and double type the same) in JVM, is divided into high 32bit and low 32bit part of the operation, and because the ZXID variable is not modified with volatile and is not boxed for the corresponding reference type (Long / Double), so it belongs to non-atomic operation. Thus, if the lower 16 bits of the upper 32 bits are divided into the low 32 bits of the entire long and become 48 bits low, there may be a concurrent problem.
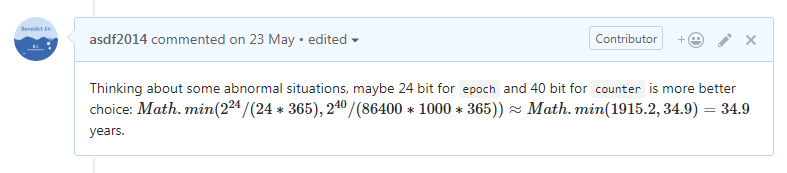
Thinking about some abnormal situations, maybe 24 bit for epoch and 40 bit for counter is more better choice: $Math.min(2^{24} / (24 * 365), 2^{40} / (86400 * 1000 * 365)) \approx Math.min(1915.2, 34.9) = 34.9$ years.
Seems like all test cases passed, but some problems happened in Zookeeper_operations :: testOperationsAndDisconnectConcurrently1:
[exec] /home/jenkins/jenkins-slave/workspace/PreCommit-ZOOKEEPER-github-pr-build/build.xml:1298: The following error occurred while executing this line:
[exec] /home/jenkins/jenkins-slave/workspace/PreCommit-ZOOKEEPER-github-pr-build/build.xml:1308: exec returned: 2
[exec]
[exec] Total time: 15 minutes 45 seconds
[exec] /bin/kill -9 16911
[exec] [exec] Zookeeper_operations::testAsyncWatcher1 : assertion : elapsed 1044
[exec] [exec] Zookeeper_operations::testAsyncGetOperation : elapsed 4 : OK
[exec] [exec] Zookeeper_operations::testOperationsAndDisconnectConcurrently1FAIL: zktest-mt
[exec] [exec] ==========================================
[exec] [exec] 1 of 2 tests failed
[exec] [exec] Please report to [email protected]
[exec] [exec] ==========================================
[exec] [exec] make[1]: Leaving directory `/home/jenkins/jenkins-slave/workspace/PreCommit-ZOOKEEPER-github-pr-build/build/test/test-cppunit`
[exec] [exec] /bin/bash: line 5: 15116 Segmentation fault ZKROOT=/home/jenkins/jenkins-slave/workspace/PreCommit-ZOOKEEPER-github-pr-build/src/c/../.. CLASSPATH=$CLASSPATH:$CLOVER_HOME/lib/clover.jar ${dir}$tst
[exec] [exec] make[1]: *** [check-TESTS] Error 1
[exec] [exec] make: *** [check-am] Error 2
[exec]
[exec] Running contrib tests.
[exec] ======================================================================
[exec]
[exec] /home/jenkins/tools/ant/apache-ant-1.9.9/bin/ant -DZookeeperPatchProcess= -Dtest.junit.output.format=xml -Dtest.output=yes test-contrib
[exec] Buildfile: /home/jenkins/jenkins-slave/workspace/PreCommit-ZOOKEEPER-github-pr-build/build.xml
[exec]
[exec] test-contrib:
[exec]
[exec] BUILD SUCCESSFUL
[exec] Total time: 0 seconds
Due to this jvm bug, JDK7 cannot recognition import static... I will use fully qualified name replace of it.
[javac] /home/jenkins/jenkins-slave/workspace/PreCommit-ZOOKEEPER-github-pr-build/src/contrib/loggraph/src/java/org/apache/zookeeper/graph/JsonGenerator.java:129: error: cannot find symbol
[javac] long epoch = getEpochFromZxid(zxid);
1.change the Zxid from high32_low32 to high24_low40 can avoid concurrent problem you hava referred to? 2.because the frequency of leading epoch change is much less than the change of counter,so you choose high24_low40? 3.when Zxid has exhausted,it will start from 0 ? or force to a new leader election ? or something else?
Hi, @maoling. Thanks for your discussion. Maybe due to my description is problematic, so make you confused.
-
I am worry about if the lower 8 bits of the upper 32 bits are divided into the low 32 bits of the entire
longand become 40 bits low, there may be a concurrent problem. Actually, it shouldn't be worried, all operation aboutZXIDis bit operation rather than=assignment operation. So, it cann't be a concurrent problem inJVMlevel. -
Yep, it is. Especially, if it is
1k/sops, then as long as $2^{32} / (86400 * 1000) \approx 49.7$ daysZXIDwill exhausted. And more terrible situation will make there-electionprocess comes early. At the same time, the "re-election" process could take half a minute. And it will be cannot acceptable. -
As so far, it will throw a
XidRolloverExceptionto forcere-electionprocess and reset thecounterto zero.
Hi, @asdf2014 .Thanks for your explanation! But I still have some confusions about the question one: look at code like this :
int epoch = (int)Long.rotateRight(zxid, 32);// >> 32;
long count = zxid & 0xffffffffffL;
it all depends on that zxid can not be altered(no write operation after zxid has generated at the first time) in the multithread situation,otherwise epoch and count isn't idempotent.should zxid be decorated by final?
@maoling You are welcome. Already changed it into following code. Then, i think it can still guarantee its idempotency.
long count = ZxidUtils.getCounterFromZxid(zxid);
long epoch = ZxidUtils.getEpochFromZxid(zxid);
Hi, I think 48 bits low is better for large throughput zk cluster. Another benefits is when use 48 bits low we assuming the epoch low than (1<<16), so we can 16 bits high to judge whether it is old version or new version. So use 48 bits low we can make the upgrade progress smoothly
Hi, @yunfan123 . Thank you for your suggestion. As you said in the opinion, so that it can guarantee a smooth upgrade. However, if the 16-bit epoch overflow rather than the counter overflow, it will make Zookeeper cannot keep provide services by re-election anymore. So, i thought we should keep enough space for epoch. What you think?
Hi, @asdf2014 In most cases, I don't think the epoch can overflow 16-bit. In general, zookeeper leader election is very rare, and it may take several seconds even several minutes to finish leader election. And zookeeper is totally unavailable during leader election. If the zookeeper that you use can overflow 16-bits, it turns out the zookeeper you used is totally unreliable. Finally, compatible with old version is really important. If not compatible with old versions, I must restart all my zookeeper nodes. All of nodes need reload snapshot and log from disk, it will cost a lot of time. I believe this upgrade process is unacceptable by most zookeeper users.
@yunfan123 @asdf2014 i have seen this issue a twice over a month period.
is there anything one can do to prevent this from happening? maybe allowing for leader restarts at "off peak hours" weekly?(yuck i know)
it sound like if we can move forward with this if we move to 48 bits low correct?
note version: 3.4.10
@JarenGlover It's a good idea, but not the best solution. Still we can use the restart operation to solve this problem without any changes to Zookeeper for now. BTW, you are welcome to get more details of this problem in my blog yuzhouwan.com :-)
Are you seeing this behavior with ZOOKEEPER-1277 applied? If so it's a bug in that change, because after that's applied the leader should shutdown as we approach the rollover.
It would be nice to address this by changing the zxid semantics, but I don't believe that's a great idea. Instead I would rather see us address any shortcoming in my original fix (1277)
fwiw - what I have seen people do in this situation is to monitor the zxid and when it gets close (say within 10%) of the rollover they have an automated script which restarts the leader, which forces a re-election. However 1277 should be doing this for you.
Given you are seeing this issue perhaps you can help with resolving any bugs in 1277? thanks!
Hi, @phunt . Thank you for your comment. Yeah, we discuss here is due to the ZOOKEEPER-1277 solution is not very well. It causes so many times leader restart. And the restart process even could spend few minutes, which is some situations cannot tolerate it.
Ok, thanks for the update. fwiw restarting taking a few minutes is going to be an issue regardless, no? Any regular type issue, such as a temporary network outage, could cause the quorum to be lost and leader election triggered.
Hi, @phunt . Indeed, the FastLeaderElection algorithm is very efficient. Most of the leader election situation would finished in hundreds milliseconds. However, some real-time stream frameworks such as Apache Kafka and Apache Storm etc, could make lots of pressures into Zookeeper cluster when they carry on too many business data or processing logic. So maybe, the leader election will be triggered very frequently and the process becomes time consuming.
i think it would be much better to extend ZOOKEEPER-1277 to more transparently do the rollover without a full leader election.
the main issue i have with shortening the epoch size is that once the epoch hits the maximum value the ensemble is stuck, nothing can proceed, so we really need to keep the epoch size big enough that we would never hit that condition. i don't think a 16-bit epoch satisfies that requirement.
Hi, @breed . Thanks for your comment. You are right, we should keep the enough epoch value to avoid meet the epoch overflow. So i offered a better solution is 24-bit epoch in second comment. Even if the frequency of leader election is once by every single hours, we will not experience the epoch overflow until 1915.2 years later.
@asdf2014 look at the latest patch,any solution for backward compatibility ?
- for backward compatibility, the version info of zk server who generates this zxid may be carried in the zxid?
- the design of current zxid benefits from generating a global unique incremental id, however also subject to this.
- look at the desigin of etcd for your reference and inspiration,her main-revision is 64 bits which is not mixed up with any info of epoch/term.
// A revision indicates modification of the key-value space.
// The set of changes that share same main revision changes the key-value space atomically.
type revision struct {
// main is the main revision of a set of changes that happen atomically.
main int64
// sub is the the sub revision of a change in a set of changes that happen
// atomically. Each change has different increasing sub revision in that
// set.
sub int64
}
Hi, @maoling. Thank you for your comments. As you said, if we cannot carry the version of server, it will be too difficult to maintain backward compatibility. The reversion in Etcd is to implement the MVCC feature, which seems to be equivalent to the Zookeeper counter, not the entire ZXID. If we consider that design, then maybe we should use more 64bits, convert ZXID from epoch(32bits)+counter(32bits) to epoch(64bits)+main_counter(32bits)+sub_counter(32bits). What do you think?
I think it is a serious problem. Too frequent re-elections make things complex and make stability indeterminacy.
Hi, @asdf2014. How about zxid skipping 0x0 value of low 32 bit, and epoch ++ when zxid is rolling over, instead of re-election.
@asdf2014 @phunt Is there a solution in the rolling over of counter bit now , we have this problem at version 3.4.13
Hi, any plans to merge this? We have seen frequent rollouts due to 32-bit zxid.
Hi @alexfernandez @wg1026688210 @happenking , thanks for your comments, I would like to merge this which could be a big step forward, maybe Apache Kafka wouldn't need to create KRaft, and ClickHouse wouldn't need to establish ClickHouse Keeper as well. Recently, Apache Druid also began supporting Etcd as an optional choice. :sweat_smile:
Hi @asdf2014 , please do! It would be a great improvement. Do you need any help?
@happenking Since I have not yet received a response from the author and have not been granted co-editor permissions, I have created a new PR(https://github.com/apache/zookeeper/pull/2164) that supports rolling updates based on that PR. Regarding the frequent zxid causing restarts, the proposed solution is to adjust the zxid, prevent re-election after zxid overflow, or just proceed with this current PR, what do you suggest?