[SPARK-40476][ML][SQL] Reduce the shuffle size of ALS
What changes were proposed in this pull request?
implement a new expression CollectTopK, which uses Array instead of BoundedPriorityQueue in ser/deser
Why are the changes needed?
Reduce the shuffle size of ALS in prediction
Does this PR introduce any user-facing change?
No
How was this patch tested?
existing testsuites
take the ALSExample for example:
import org.apache.spark.ml.recommendation._
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
val ratings = spark.read.textFile("data/mllib/als/sample_movielens_ratings.txt").map(parseRating).toDF()
val als = new ALS().setMaxIter(1).setRegParam(0.01).setUserCol("userId").setItemCol("movieId").setRatingCol("rating")
val model = als.fit(ratings)
model.recommendForAllItems(10).collect()
before:
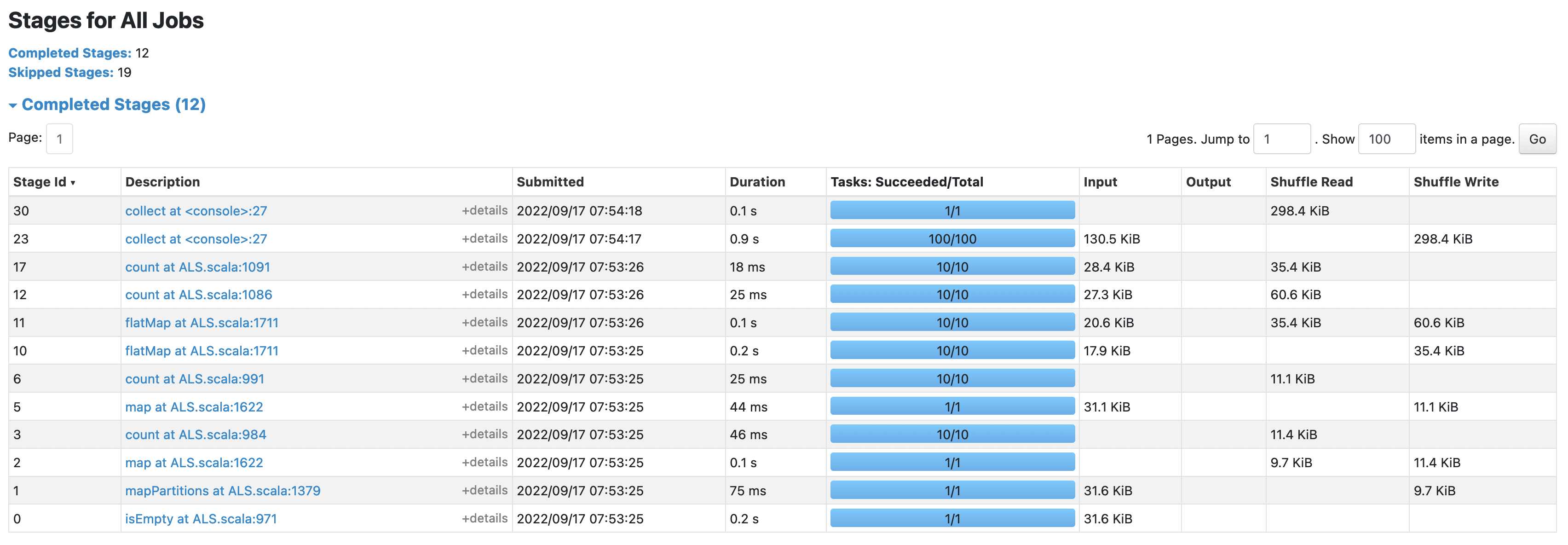
after:
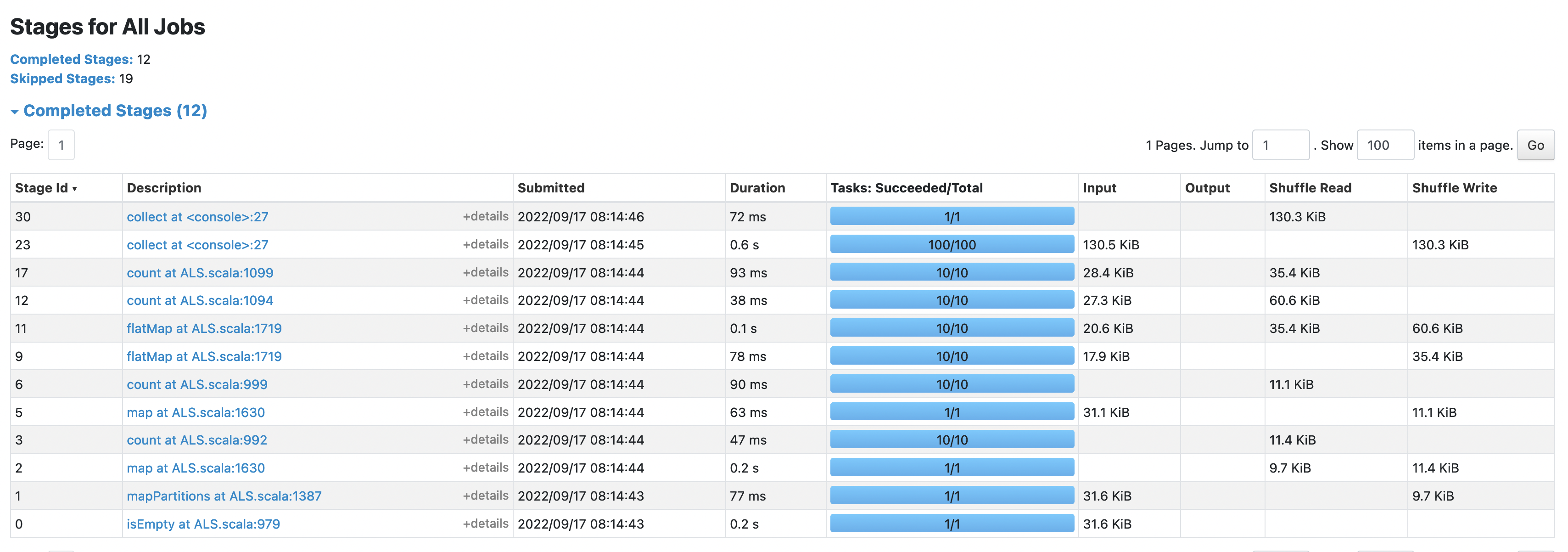
the shuffle size in this case was reduced from 298.4 KiB to 130.3 KiB
@dongjoon-hyun
could you make an independent PR moving TopByKeyAggregator to CollectTopK because that is orthogonal from Reduce the shuffle size of ALS?
It is just the moving from TopByKeyAggregator to CollectTopK that reduce the shuffle size, since the ser/deser is optimized in CollectTopK, let me update the PR description
In addition, we need a test coverage for CollectTopK because we remove TopByKeyAggregatorSuite.
Sure, will update soon