spark
 spark copied to clipboard
spark copied to clipboard
[SPARK-39357][SQL] Fix pmCache memory leak caused by IsolatedClassLoader
What changes were proposed in this pull request?
- Fixed memory leak caused
RawStorecleanup mechanism not to take effect due to differentthreadLocalMSinstances being manipulated. - Fixed memory leak caused by not calling
ThreadWithGarbageCleanup#cacheThreadLocalRawStorewhen submit background operation inSparkExecuteStatementOperation. - Fixed memory leak caused by instance in
threadRawStoreMapnot being updated after re-createdRawStoreinstance, reference: HIVE-20192.
Why are the changes needed?
Reference: SPARK-39357
We need to manipulate the same threadLocalMS instance for the RawStore cleanup mechanism to work, the current fix makes ThreadWithGarbageCleanup get the RawStore instance from the threadLocalMS instance in HMSHandler(loaded by IsolatedClassLoader$$anon$1).
Here are some fixes I tried but didn't work with:
-
I tried to create
ThreadFactoryWithGarbageCleanupthroughIsolatedClassLoaderso thatThreadWithGarbageCleanup#cacheThreadLocalRawStorecan directly getRawStoreinstance from thethreadLocalMSinstance inHMSHandler(loaded by IsolatedClassLoader$$anon$1), but it turned out that this fix is not feasible because In the judgment logic before callingThreadWithGarbageCleanup#cacheThreadLocalRawStore,ThreadWithGarbageCleanup.currentThread() instanceof ThreadWithGarbageCleanupwill return false andcacheThreadLocalRawStorecannot be called. The reason for returning false is that theThreadWithGarbageCleanupinstance and theThreadWithGarbageCleanupclass belong to different class loaders. -
I tried not to isolate the
HiveMetaStore.HMSHandlerclass inIsolatedClientLoader#isSharedClass, but actually found that there are too many related classes, and this class must be shared at the same time, otherwise it will causeClassCastExceptionandLinkageError, see 3.2 Class loading in Java, finally I added the following code makeHiveMetaStore.HMSHandleris no longer isolated:val relatedToThreadLocalMS = name.startsWith("org.datanucleus.") || name.startsWith("org.apache.hadoop.hive.metastore.") || name.startsWith("org.apache.hadoop.hive.conf.HiveConf") || name.startsWith("org.apache.hadoop.hive.ql.") || name.startsWith("org.apache.hadoop.hive.serde2.")There are several reasons why this fix was not used in the end: First, I think this fix breaks the design of
IsolatedClassLoader, and second, some class names that need to be shared need to be read from configuration information. Get configuration information fromIsolatedClassLoaderdoes not seem to be easy, such as:HiveConf.ConfVars.METASTORE_EXPRESSION_PROXY_CLASS, if the user configures other custom class name, then ourrelatedToThreadLocalMSjudgment may fail, resulting inClassCastExceptionandLinkageError.
Does this PR introduce any user-facing change?
No
How was this patch tested?
Existing unit tests passed. I have built Spark 2.4.4 with the current fix and have it in production for over a month, confirming the fix is correct.
This can be verified with the fixed production ThriftServer heap dump, this ThriftServer has been running stably for a month, I grabbed the heap dump after a FullGC and executed the following OQL in MAT: SELECT * FROM org.datanucleus.api.jdo.JDOPersistenceManagerFactory, the result is shown in the image:
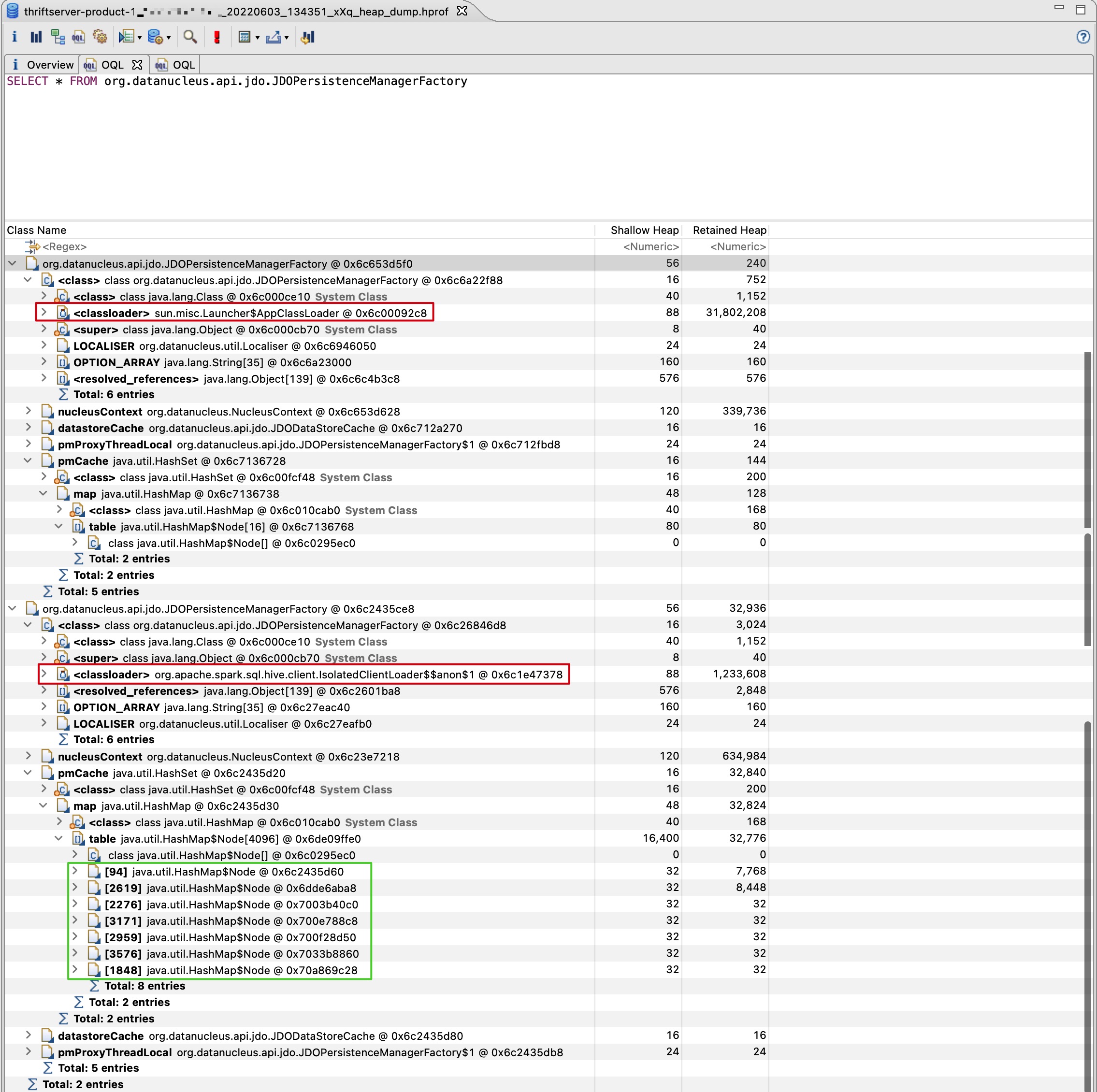
It can be seen that the size of the pmCache of JDOPersistenceManagerFactory(loaded by IsolatedClassLoader$$anon$1) is 7, instead of more than 200,000 before the fix.
Then execute the following OQL in MAT: SELECT * FROM INSTANCEOF java.lang.Class c WHERE [email protected]("class org.apache.hive.service.server.ThreadFactoryWithGarbageCleanup"), the result is shown in the image:
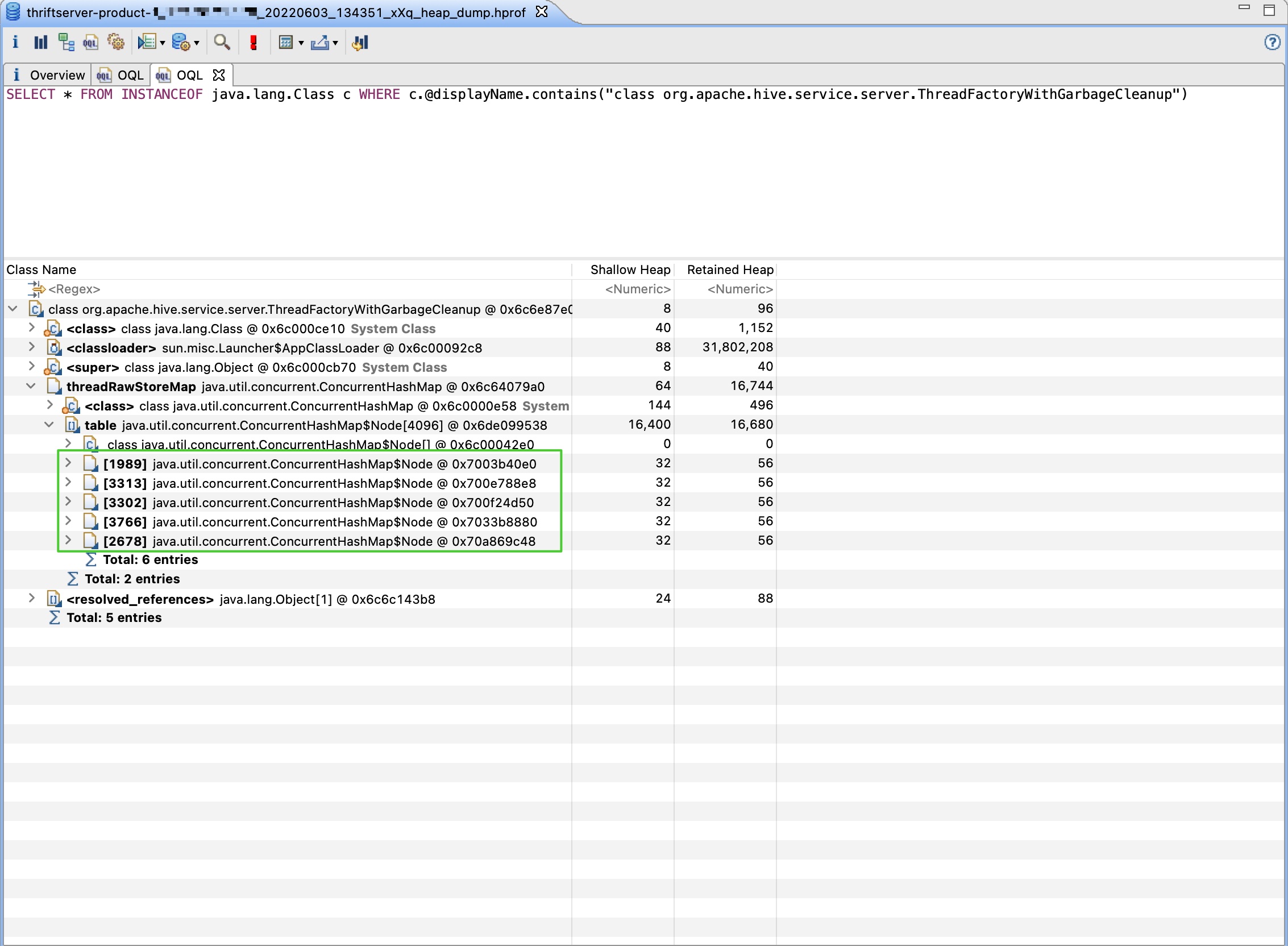
It can be seen that the size of threadRawStoreMap is 5, because the ThriftServer is idle when I grab the heap dump and the default configuration org.apache.hadoop.hive.conf.HiveConf.ConfVars#HIVE_SERVER2_THRIFT_MIN_WORKER_THREADS is 5.
The two extra elements of pmCache are created by threads outside the HiveServer2-* thread pool, such as the main thread. In short, after the fix, pmCache no longer continues to grow, ensuring stable memory usage.
Can't we just use a SoftReferenceMap or something ? is the leak just holding onto entries in that Map?
Can't we just use a SoftReferenceMap or something ? is the leak just holding onto entries in that Map?
In fact, the leak map(pmCache) caused by this problem belongs to datanucleus-api-jdo, which is only a library that Spark depends on, and we should not modify its code because the problem is caused by the IsolatedClassLoader in Spark. The leak caused the memory to grow slowly and finally the STS SQL execution was very slow (continuous GC).
This seems super hacky. Is there any way to do better cleanup?
Yes, the current fix ensures that we always manipulate threadLocalMS instances in HMSHandler(loaded by IsolatedClassLoader$$anon$1) to avoid memory leaks. I don't know if this is the optimal fix, but it does solve the problem of memory leaks. There are two threadLocalMS instances in the JVM complicates the problem. I haven't come up with a better fix, please let me know if you have new ideas.
As described at the beginning of this PR, I tried other fixes and none of them worked, and finally I came up with the current fix, which does seem hacky since I also didn't come up with a better way to clean it up.
@marmbrus , Can you give some advice? The IsolatedClassLoader introduced by SPARK-6907 seven years ago is related to this bug.
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag!