servicecomb-pack
 servicecomb-pack copied to clipboard
servicecomb-pack copied to clipboard
Apache ServiceComb Pack is an eventually data consistency solution for micro-service applications. ServiceComb Pack currently provides TCC and Saga distributed transaction co-ordination solutions by u...
```java @Override public void compensate(TxEvent event) { Map serviceCallbacks = callbacks.getOrDefault(event.serviceName(), emptyMap()); OmegaCallback omegaCallback = serviceCallbacks.get(event.instanceId()); if (omegaCallback == null) { LOG.info("Cannot find the service with the instanceId {}, call...
branch:0.4.x
这个是远程抛出的异常信息: org.apache.servicecomb.pack.omega.transaction.OmegaException: Failed to get reconnected sender, all alpha server is down. 但是我alpha服务器确认是启动着
alpha和omega都是通过容器部署的,k8s; 情况: 第一次调用服务A的时候,在向alpha发送SagaStartEvent时报了`io.grpc.StatusRuntimeException: UNKNOWN`,此时将sender的value设置为Long.MAX_VALUE; 第二次调用服务A时,就报了`Failed to get reconnected sender, all alpha server is down.`,导致整个服务不能正常使用; 我想问,在第一次调用时,报了GRPC的异常,为什么没有执行`PushBackReconnectRunnable.run()`进行重连呢? 之前我猜测可能因为设置的gprc地址不对,但是omega在启动时是会去连接alpha进行校验的,这就说明alpha配置的GRPC地址是正确的,可是为什么在发送事件的时候出错了?是因为网络的原因的?
pack问题汇总反馈

大家好!本人最近做分布式事务服务框架,刚开始想直接将pack拿过来使用,但我们发现pack的问题太多了。逼不得已将pack的核心代码基本全部重写,但保持业务逻辑与pack一致。受制于公司政策,代码不方便公开。现将我们遇到的问题进行反馈: 1. 服务发现机制不健全,如果新加入alpha,客户端无法感知; 2. SQL代码复杂。这是由于数据库设计表不合理造成的。saga只有一个表,tcc有三个表,其实两张表最合理,一张表存事务的整体状态,一张表存事务的事件。这样可以使SQL写的很简单。 3. 回滚逻辑复杂,回滚速度慢,如果出现要回滚1000条,立即卡死。建议可以引入状态机来描述分布式事务的状态,回滚逻辑就不需要那么复杂了,代码只需一百多行。下面是我们设计的SAGA状态机,TCC状态机会更复杂一些:  4. gRPC性能较低:gRPC同步模型性能很差,但受制于spring线程模型,只能采用同步模型。 `rpc OnTxEvent (GrpcTxEvent) returns (GrpcAck) {}` 我们是直接用netty手撸了定制的RPC框架,即使是在客户端阻塞的情况下,qps也比gRPC双工异步快。 5. mysql性能较慢:其实这种中间件对性能要求是很高的,一个RPC请求最好在5ms内返回,内网环境下网络需消耗2ms,请求处理要在3ms内返回。使用mysql在高负载下经常超时,目前我们的处理方式是异步批量入库,但这种情况下客户端需将事件发到固定的alpha,以防止事件顺序不对,同时要处理关闭server时清空入库队列; 6. jpa有些不好用:我们在做批量入库时,使用了saveAll方法,但会丢数据,查询时缓存也有影响,查这个事务的数据能出来一条别的事务的数据。我们团队没人会jpa,果断换成mybatis; 7. RPC次数较多:每个分支有两次请求,加上开启与提交,如果有n个分支,SAGA RPC次数是2n+2,TCC是3n+2。我们觉得实在太多了,可以砍掉一部分。我们假定大部分情况下分布式事务是成功的,如果成功率太低,这个接口没有意义。所以,对于分支事务开始会发RPC请求,但结束时不会,除非发生异常会进行RPC请求。这样一个事务正常情况下,SAGA变为n+2,TCC变为2n+2; 经过开发分布式事务,我觉得这玩意就是鸡肋,能不用就不要用!我还是更推荐AP+最终一致性。使用这种框架增加了整个提供的复杂度、耦合性,如果alpha宕机会导致整个系统不可用,而且接口都要求幂等,对普通开发人员来说很容易生产bug。 最后,感谢各位开发者贡献这么好的框架,使本人学会了怎么处理这类问题。非常感谢!
servicecomb的正向恢复和逆向补偿不可兼得吗?测试的时候发现,配置了向前恢复后,就不会执行逆向补偿方法了。

事务失败后做补偿操作(cancel),补偿操作抛异常后omega只是打日志,然后继续发送TxCompensatedEvent给alpha-server。alpha-server认为处理成功了结束事务?这种情况如何监控?
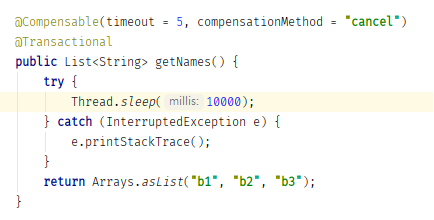 超時場景下,console log 會噴出下圖錯誤訊息,想請教是什麼原因造成的,感謝 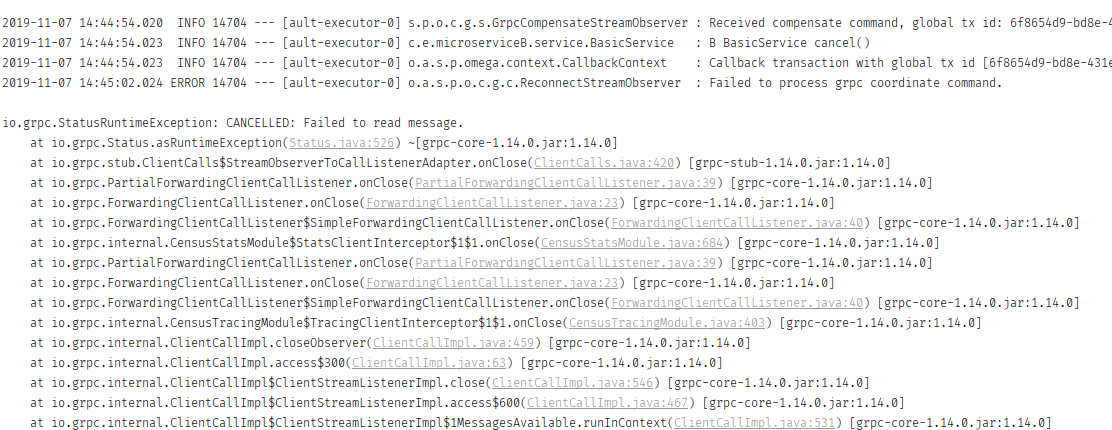 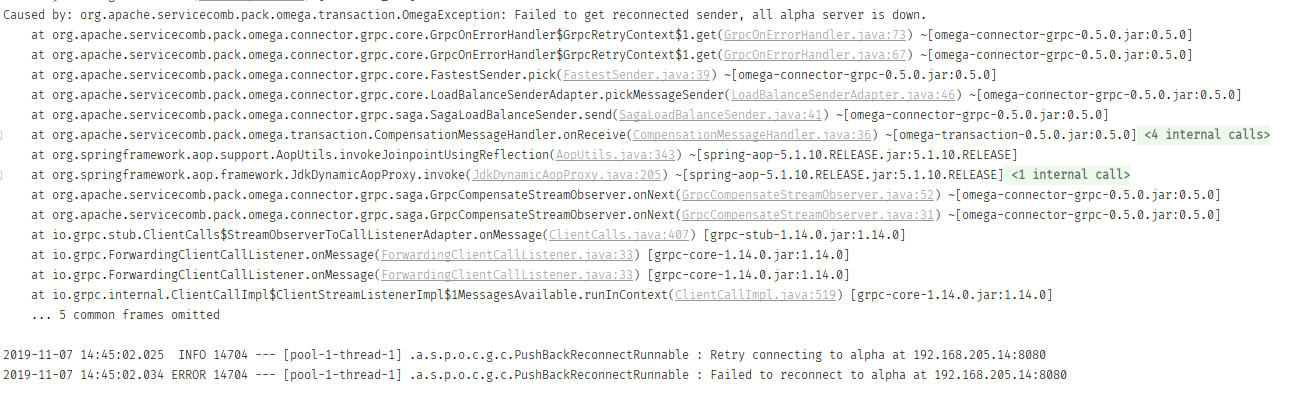 omega-spring-starter & omega-transport-resttemplate 版本皆為 0.5.0 springboot 版本是 2.1.9.RELEASE alpha-server console log 
版本0.5.0,在k8s上,日志报错如下: > 06:27:28.135 [pool-3-thread-1] INFO org.apache.servicecomb.pack.alpha.core.CompositeOmegaCallback - Cannot find the service with the instanceId shop-svc-10.10.1.62, call the other instance. 06:27:28.135 [pool-3-thread-1] ERROR org.apache.servicecomb.pack.alpha.core.PushBackOmegaCallback - Failed to compensate service [shop-svc] instance...