seatunnel
 seatunnel copied to clipboard
seatunnel copied to clipboard
[ST-Engine][Design] Optimize SeaTunnel Zeta engine Jar package upload logic
Search before asking
- [X] I had searched in the feature and found no similar feature requirement.
Description
Introduction
From #2333 we know, this approach has two significant limitations:
- The server needs to have all connectors and their dependent JAR packages.
- The installation path of the client must be exactly the same as the server, and the installation path of Seatunnel Zeta in all nodes must also be the same. This leads to the engine side of SeaTunnel Zeta being relatively heavy, and the container volume becoming very large when performing Docker or Kubernetes (K8S) submission tasks.
To address these limitations, we need to optimize the logic of the Zeta engine to execute the job. The server should only have the core jar package of the engine, and all the connector packages are on the Client side. When the job is submitted, the Client side should upload the required jar package to the server side, instead of just keeping the path of the jar package. When the server executes the job, it downloads the jar package required for the job and then loads it. After the job runs, the jar package is deleted.
Overall Architecture
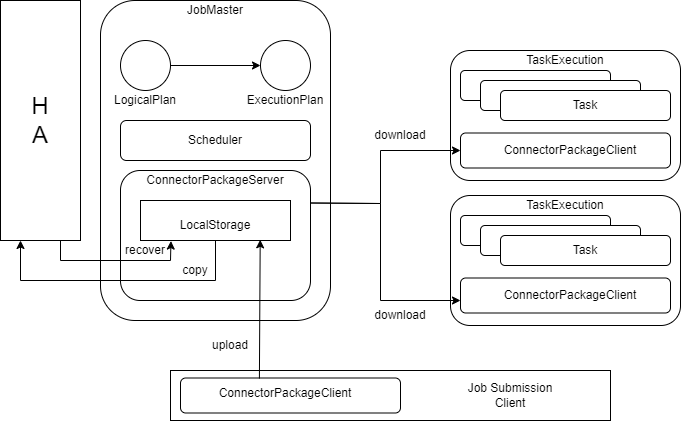
ConnectorPackageServer:
-
Capable of responding to third-party JAR package file upload and download requests for connectors and their dependencies.
-
The local file system can read and write connector JAR package files.
-
The local file system reads and writes the third-party JAR package files that the connector depends on.
-
Supports HA-distributed file system read and write.
-
Responsible for cleaning up the local file system and distributed file system.
-
Download requests prioritize using files from the local file system for HA recovery, downloading files from the distributed system to the local file system.
ConnectorPackageClient:
- Caches local files in the ConnectorPackageServer for reading and writing.
- Prioritizes using files from the local file system, then attempts to obtain them from the ConnectorPackageServert running on the JobMaster side, and finally attempts to download them from the HA distributed file system.
- Responsible for cleaning the local file system.
ConnectorPackageHAStorage:
ConnectorPackageServer only temporarily saves files without specialized persistence operations. To ensure successful recovery from checkpoints after exceptions occur during task execution, it is necessary to persist JAR Package to the local file system or other distributed storage services, such as HDFS, S3, etc.
ConnectorJarsLoader:
ConnectorJarsLoader is a bridge between the JAR package of the connector obtained through component download, the JAR package that the connector depends on, and ClassLoader. These JAR package files are loaded into the path using the corresponding ClassLoader through ConnectorJarsLoader.
Process Design
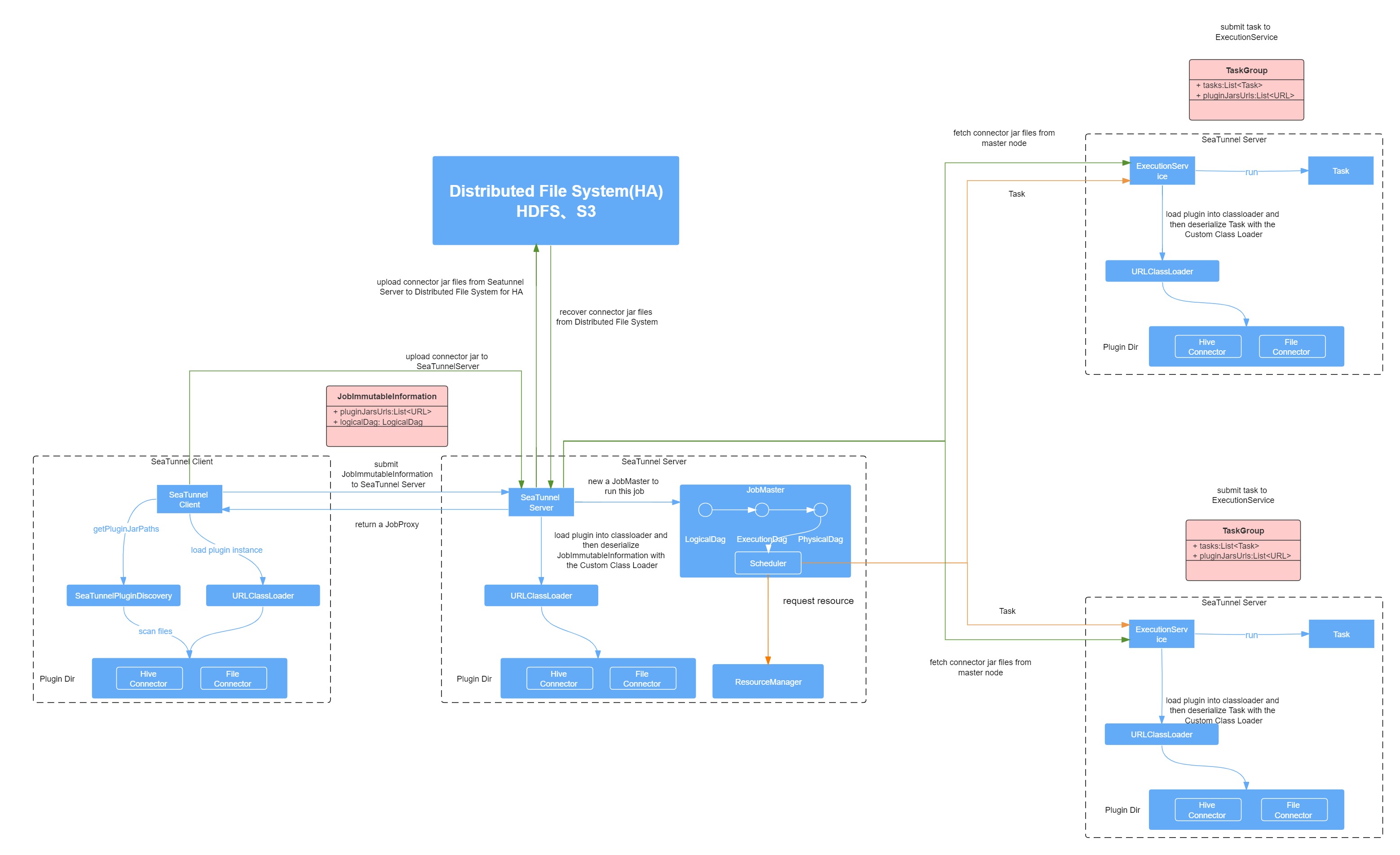
Uploads the JAR package files
During the process of creating a job execution environment, the seatunnel client searches for third-party JAR packages that the connector depends on in the SEATUNNEL_HOME/plugins directory. After parsing the job configuration file according to the plugin type, the unique identifier of each connector plugin needs to be passed to PluginDiscovery. PluginDiscovery will obtain the JAR package name prefix for the corresponding connector from the relevant configuration file (mapping.properties) based on the plugin's unique identifier. Finally, PluginDiscovery searches for the connector JAR package in the storage directory where the corresponding connector JAR package is saved, and uploads it to the Hazelcast main node before the job submission process.
The file is first uploaded to JobMaster for local storage and then transferred to HA storage. Only after both are successfully written can the upload be confirmed (if HA is configured).
JAR package file integrity verification
By performing file verification during the file upload process, it is possible to increase the verification of the integrity of the uploaded file. This helps to ensure that the uploaded files are not tampered with or damaged during transmission and storage.
Obtain JAR package files
JobMaster will create a job scheduler to schedule and deploy physical node tasks in the job. The first step in deploying tasks through task execution services is to obtain the JAR package URL required for the current task execution from the job information. The second step is to determine whether the JAR package associated with the task exists locally. If there is no connector JAR package or third-party JAR package that the connector depends on in the local storage of the current executing node, then we need to obtain the corresponding connector JAR package for the current task and the third-party JAR package file that the connector depends on from JobMaster. Therefore, this step is the process of obtaining the JAR package on the execution end. Similarly, it is necessary to perform file integrity verification on the JAR package file obtained by the execution end. As long as the file integrity verification is successful, the next class loading process can proceed. After the class is loaded, the execution service executes the task.
JobMaster Reliability Assurance (HA)
When the main node crashes, Hazelcast will automatically select another node as the master node. The re-selected master node will undergo the JobMaster reinitialization process again. In order to ensure the normal execution of previous jobs, we need to restore the locally stored job connector JAR package and the third-party JAR package that the connector relies on. We obtain the JAR files required for the job from the distributed file system and load them.
Clear the JAR package files
The cleaning work is carried out not only on the local file system of the Hazelcast master node running on JobMaster but also on the connector JAR packages associated with the job and the third-party JAR packages that the connector depends on in the distributed file system.
Connector JAR file type
Through the ConnectorPackageClient, you can download the JAR package of the connector, the JAR package that the connector depends on, and the user's JAR files from the service executed by JobMaster and store their JAR file content on a local disk. All JAR package files can be roughly divided into two types:
- COMMON_PLUGIN_JAR
- CONNECTOR_PLUGIN_JAR
Abstract Interface
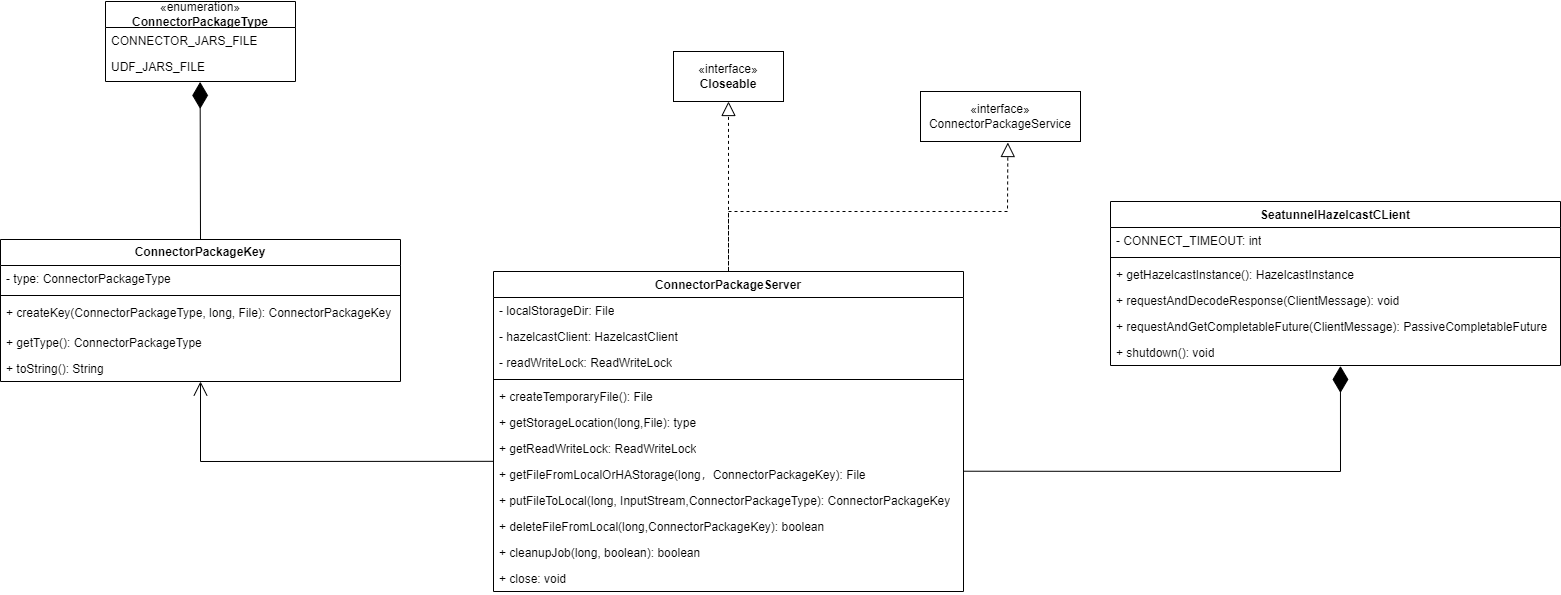
This class implements a server that supports storing JAR package files for connectors, JAR files that connectors depend on. The server is responsible for listening to incoming requests and generating threads to process them. In addition, it is also responsible for creating directory structures that temporarily or permanently store JAR package files for connectors, as well as third-party JAR files that the connector depends on.
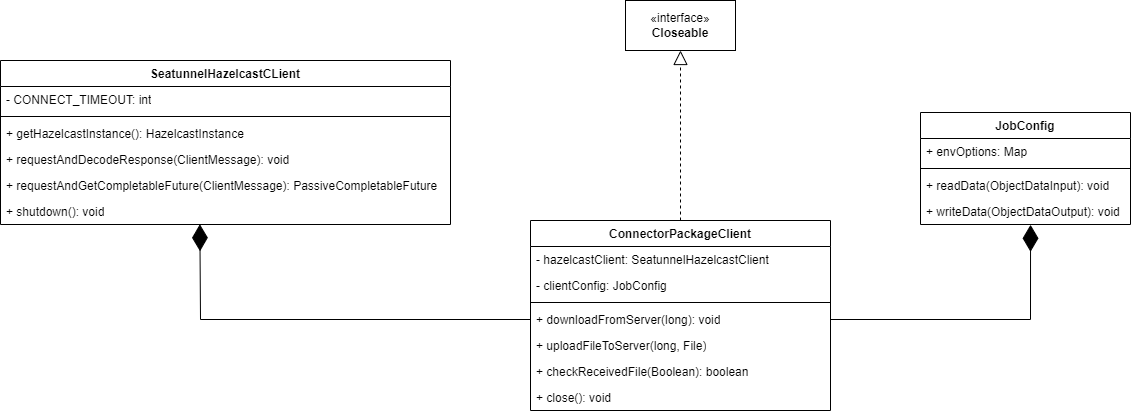
The ConnectorPackageClient can communicate with the ConnectorPackageServer, sending requests to upload files and download files to the ConnectorPackageServer.
Usage Scenario
No response
Related issues
No response
Are you willing to submit a PR?
- [X] Yes I am willing to submit a PR!
Code of Conduct
- [X] I agree to follow this project's Code of Conduct
Hi,The current way of remotely uploading jar packages, the server side will generate a large number of classloaders, which causes a lot of pressure on metaspace, can you improve it? In addition, the historical JOB memory of zeta engine has not been released. Can metaspace consider optimizing the unknown memory growth?
This issue has been automatically marked as stale because it has not had recent activity for 30 days. It will be closed in next 7 days if no further activity occurs.
Hi,The current way of remotely uploading jar packages, the server side will generate a large number of classloaders, which causes a lot of pressure on metaspace, can you improve it? In addition, the historical JOB memory of zeta engine has not been released. Can metaspace consider optimizing the unknown memory growth?
Sorry for not noticing your comment on this issue in time, this is a very valuable issue that needs to be resolved. ClassLoaders created due to repeated executions of the same job can be resolved by caching, but this helps little in metaspace. For the large number of new ClassLoaders created by different job executions, it is not clear what good way to solve it for me. If you have good ideas here, I would appreciate hearing your thoughts on this matter.
Hi, I'm leaving a question in passing. When, main node crash I think connection between new selected node and file system that save jar package is important. Am I right? and doesn't this change make recover time from abnormal master node long?
Nice job. For this relatively large feature, I suggest starting with the [email protected] Proposal and discussion in the mailing list.
Most of the images cannot be displayed. Can you place the design documents in Google doc or seatunel's conf https://cwiki.apache.org/confluence/display/SEATUNNEL/Home?
Hi, I'm leaving a question in passing. When, main node crash I think connection between new selected node and file system that save jar package is important. Am I right? and doesn't this change make recover time from abnormal master node long?
Thank you very much for raising this question and your viewpoint is correct. The previous solution was to issue a pull request for missing Jar packets from the slave node to the master node, which would result in a longer recovery time for abnormal nodes. The slave node needs to download all missing Jar packet files from the master node to complete node recovery. This pull method also requires the service to rely on a distributed system, so I did not use pull in the future. Instead, I pushed the Jar package files required for task execution through the master node to each slave node for storage, so that each node stored a copy of the Jar package file, thereby avoiding the transmission delay required for Jar package file recovery between nodes.
Most of the images cannot be displayed. Can you place the design documents in Google doc or seatunel's conf https://cwiki.apache.org/confluence/display/SEATUNNEL/Home?
I have placed the design documents in Google doc, PTAL! design documents link : https://docs.google.com/document/d/14b6rHr1jjul224AkYIm0fjB4DtqY6U-OY42zmZxw4sY/