[fix][broker][schema]fix creating lots of ledgers for the same schema
Fixes #18292
Motivation
fix creating lots of ledgers for the same schema
Modifications
when putting schema to zk failed, do not retry directly, but read the latest persistent schema from zk first
Documentation
- [ ]
doc - [ ]
doc-required - [x]
doc-not-needed - [ ]
doc-complete
Matching PR in forked repository
PR in forked repository: https://github.com/aloyszhang/pulsar/pull/3
Codecov Report
Merging #18293 (fe78ff2) into master (cee697b) will decrease coverage by
0.15%. The diff coverage is28.94%.

@@ Coverage Diff @@
## master #18293 +/- ##
============================================
- Coverage 47.06% 46.91% -0.16%
- Complexity 8956 10428 +1472
============================================
Files 592 698 +106
Lines 56313 68339 +12026
Branches 5844 7342 +1498
============================================
+ Hits 26503 32058 +5555
- Misses 26946 32658 +5712
- Partials 2864 3623 +759
| Flag | Coverage Δ | |
|---|---|---|
| unittests | 46.91% <28.94%> (-0.16%) |
:arrow_down: |
Flags with carried forward coverage won't be shown. Click here to find out more.
| Impacted Files | Coverage Δ | |
|---|---|---|
| ...apache/bookkeeper/mledger/ManagedLedgerConfig.java | 71.60% <0.00%> (ø) |
|
| .../org/apache/bookkeeper/mledger/impl/MetaStore.java | 100.00% <ø> (ø) |
|
| ...okkeeper/mledger/impl/ShadowManagedLedgerImpl.java | 0.00% <0.00%> (ø) |
|
| ...ava/org/apache/pulsar/broker/service/Consumer.java | 69.21% <0.00%> (+7.11%) |
:arrow_up: |
| ...service/schema/BookkeeperSchemaStorageFactory.java | 100.00% <ø> (ø) |
|
| ...ker/stats/prometheus/NamespaceStatsAggregator.java | 0.00% <0.00%> (ø) |
|
| ...va/org/apache/pulsar/client/impl/ProducerImpl.java | 17.00% <0.00%> (-0.02%) |
:arrow_down: |
| ...rg/apache/pulsar/broker/service/BrokerService.java | 57.34% <20.00%> (+0.15%) |
:arrow_up: |
| ...sar/broker/service/persistent/PersistentTopic.java | 61.46% <20.00%> (-0.82%) |
:arrow_down: |
| ...org/apache/bookkeeper/mledger/impl/OpAddEntry.java | 64.21% <26.31%> (ø) |
|
| ... and 186 more |
This pr only guarantees the consistency of the zk storage schema, but it still creates useless ledger, right?
@congbobo184 The schema will create a useless ledger at two points.
- At the point of client connected the first time concurrently, all producers or consumers see no schema info and create a new schema ledger, and only onde ledger will be used at last
- At the point of update zookeeper storage failed, the broker will create a new schema ledger repeatedly if the update zookeeper failed.
This PR tries to resolve the second problem.
I still working on the first problem and will send a new PR for it.
To my understanding, this PR canceled the retry action in putSchema, and add the retry action in putSchemaIfAbsent.
But I notice the putSchema method will be called by the deleteSchema method, so this PR removes the retry functionality of deleteSchema method too. Will that be OK?
To my understanding, this PR canceled the retry action in putSchema, and add the retry action in putSchemaIfAbsent. But I notice the putSchema method will be called by the deleteSchema method, so this PR removes the retry functionality of deleteSchema method too. Will that be OK?
@labuladong As described in issue #18292, the retry function in putSchema is the root cause of creating lots of useless schema ledgers when the update zookeeper failed with AlreadyExistsException or BadVersionException. So, it should be removed.
BTW, the retry function is only useful when there is a race condition updating the zookeeper, and the command of delete schema is invoked from the CLI or PulsarAdmin which is rare to have a high concurrency. So, little chance for delete the schema will fail. However, putSchemaIfAbsent will be called when the producer or subscription is created. There is a high chance for a race condition to happen, so keep the retry function to avoid the producer or consumer from init failed.
Also, if there is a scene where keeping the retry function in putSchema is necessary, we can bring up a new issue and pull request.
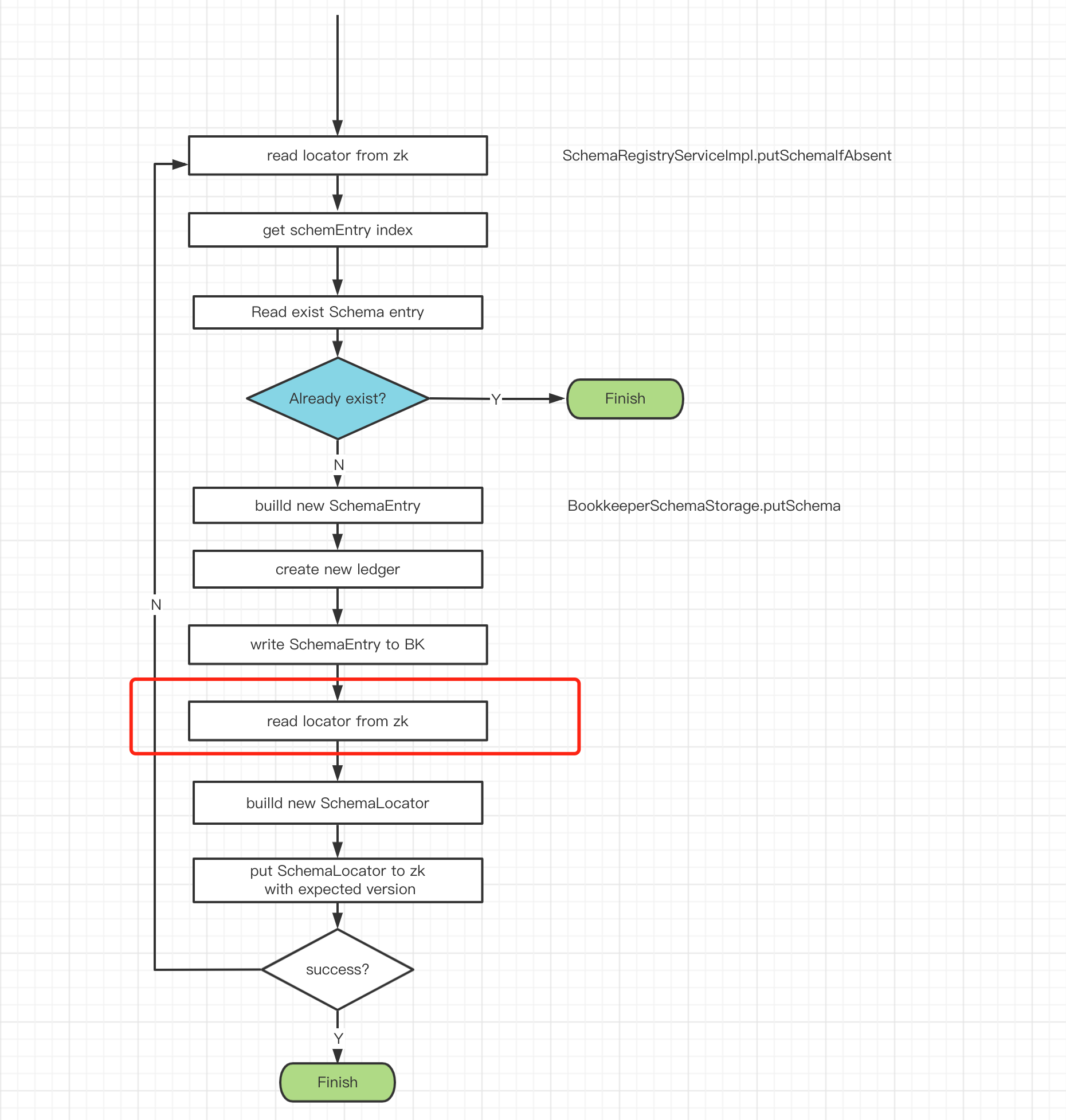 @codelipenghui This is another problem. The root cause is the concurrent access to zookeeper.
@codelipenghui This is another problem. The root cause is the concurrent access to zookeeper.
Before updating the schemaLocator on zk, it reads zk again. The purpose is to obtain the content of the existing locator to build the index information of the new locator, and the version will be +1.
If other threads updated the locator just before this point, it directly adds the position information of a new schema entry to the locator without exist check
@aloyszhang hi, I move this PR to release/2.9.5, if you have any questions, please ping me. thanks.
close this pull request due to https://github.com/apache/pulsar/pull/18701