jena
 jena copied to clipboard
jena copied to clipboard
Added GraphMemUsingHashMap (faster and needs less memory) to replace GraphMem
update on 2022.06.09 -> implementation almost ready, JMH benchmark results
trading RAM for speed
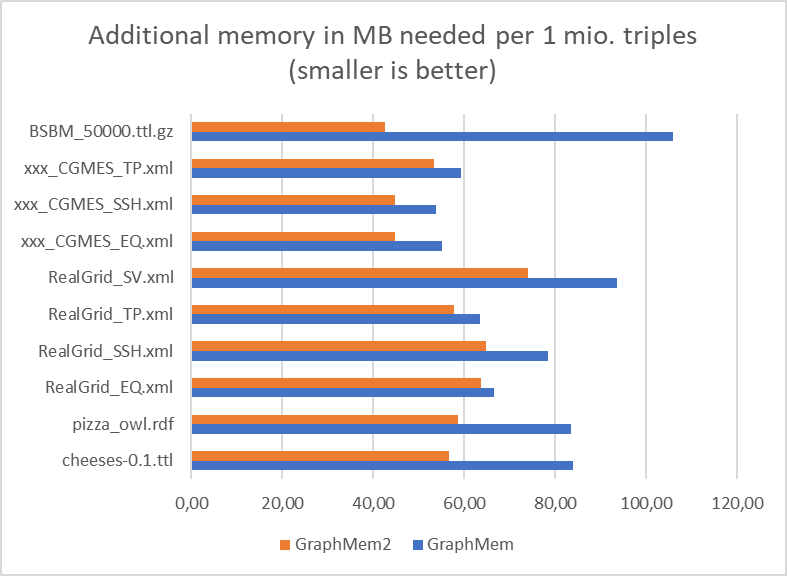
Starting from a variant with very low memory requirements, I decided to trade some memory for speed. For this reason, I developed two implementations: GraphMem2 uses less memory than GraphMem in most cases. GraphMem2Fast uses more memory in most cases, but not excessively for large BSBM graphs. Here is a table with my samle graphs and the additional memory consumption due to the indexing structures in the different graph implementations:
| sample graph | triples | size of triples | +GraphMem | +GraphMem2 | +GraphMem2Fast |
|---|---|---|---|---|---|
| pizza.owl.rdf | 1980 | 0.447 MB | 0.165 MB | 0.123 MB | 0.150 MB |
| cheeses-0.1.ttl | 7,744 | 0.805 MB | 0.165 MB | 0.123 MB | 0.150 MB |
| xxx_CGMES_EQ.xml | 272,800 | 72.568 MB | 15.158 MB | 12.405 MB | 16.982 MB |
| xxx_CGMES_SSH.xml | 79,507 | 20.944 MB | 4.276 MB | 3.582 MB | 5.094 MB |
| xxx_CGMES_TP.xml | 47,455 | 12.310 MB | 2.815 MB | 2.635 MB | 3.331 MB |
| RealGrid_EQ.xml | 947,208 | 246.434 MB | 62.942 MB | 67.260 MB | 92.285 MB |
| RealGrid_SSH.xml | 187,034 | 44.737 MB | 14.639 MB | 13.486 MB | 18.654 MB |
| RealGrid_TP.xml | 96,740 | 23.768 MB | 6.137 MB | 5.888 MB | 7.468 MB |
| RealGrid_SV.xml | 184,455 | 44.05 MB | 17.248 MB | 15.037 MB | 17.930 MB |
| BSBM_2500.ttl | 596,746 | 99.914 MB | 63.507 MB | 32.056 MB | 43.480 MB |
| BSBM_50000.ttl.gz | 17,424,059 | 3,069.049 MB | 1,843.851 MB | 759.397 MB | 1,110.948 MB |
using Java Microbenchmark Harness (JMH)
Apart from knowing better, I started without jmh and did my benchmarks with unit tests only at first. That was fine, up to the point where I started reading the results with wishful thinking. As I don't have much practice with jmh, hopefully I have used it correctly and with reliable results:
- Graph#add
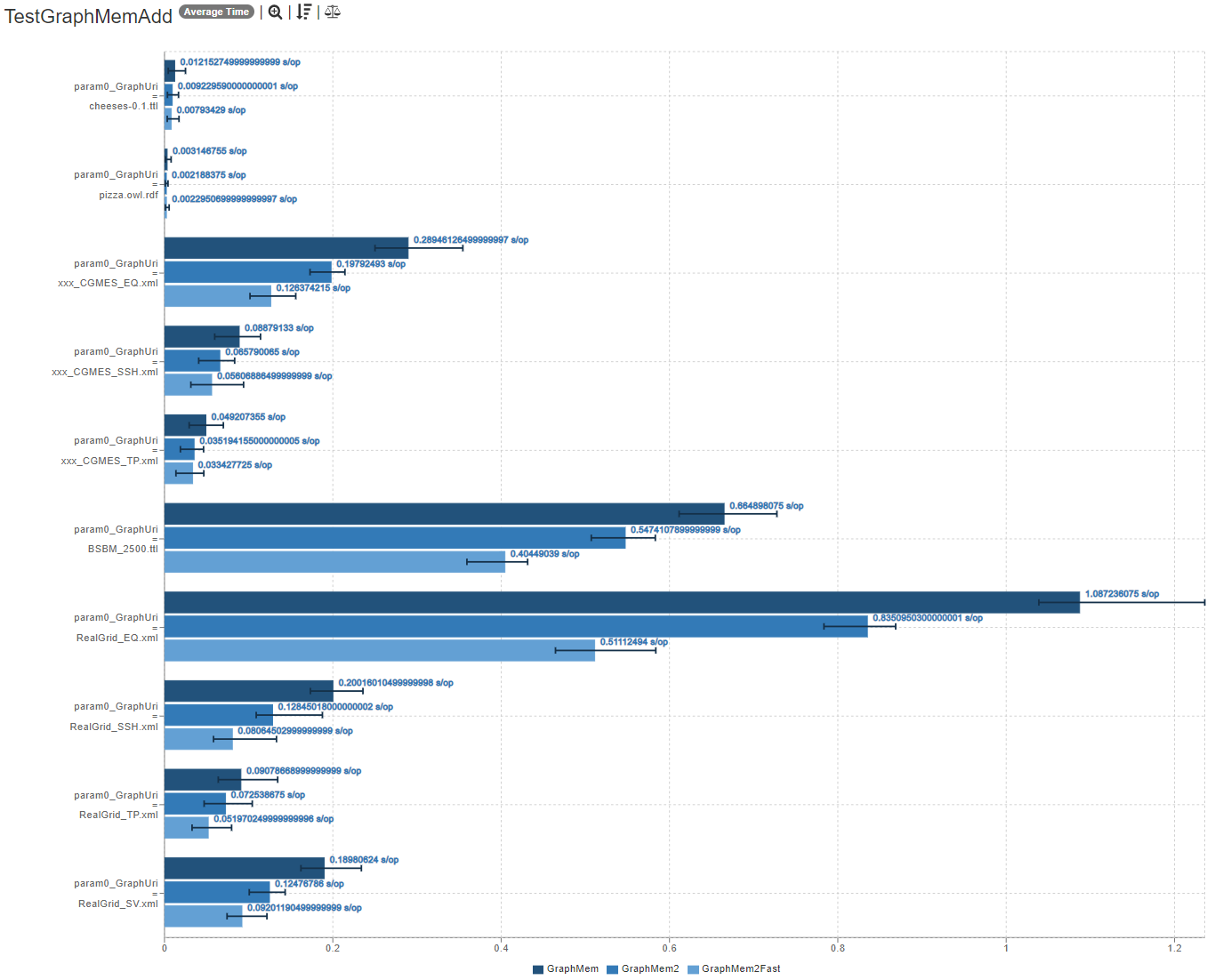
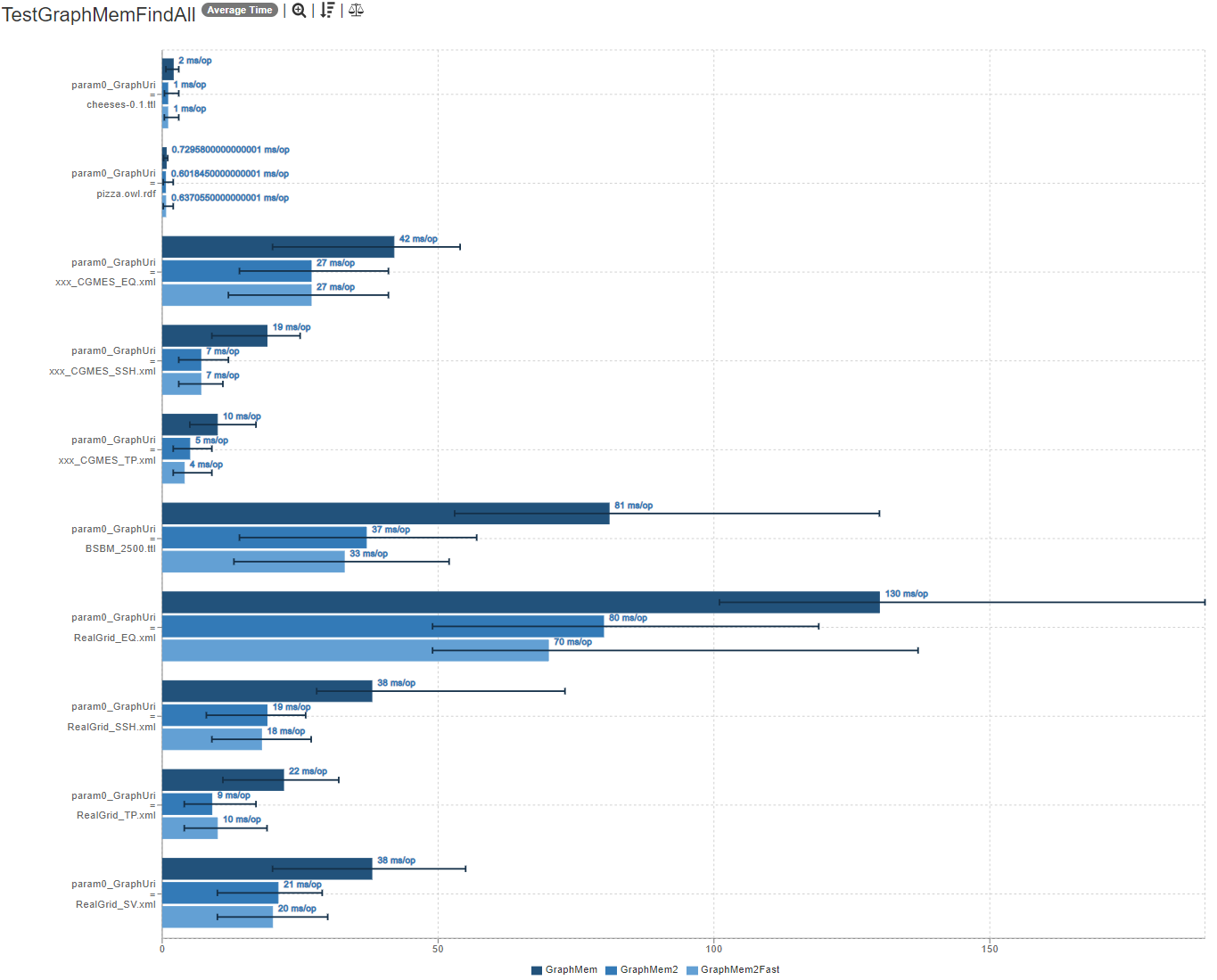
- Graph#find(ANY, ANY, ANY) (details for other combinations are roughly comparable)
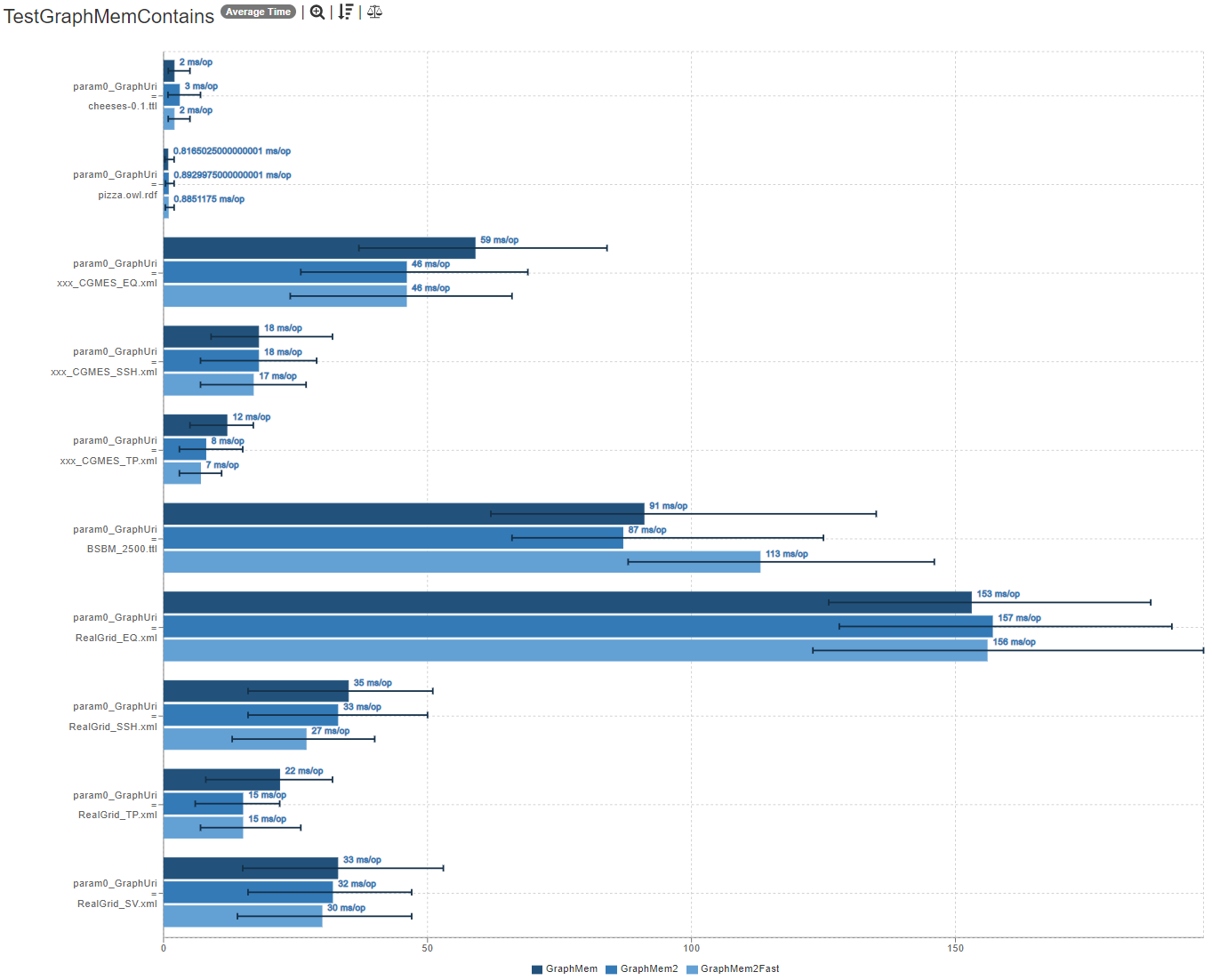
- Graph#contains
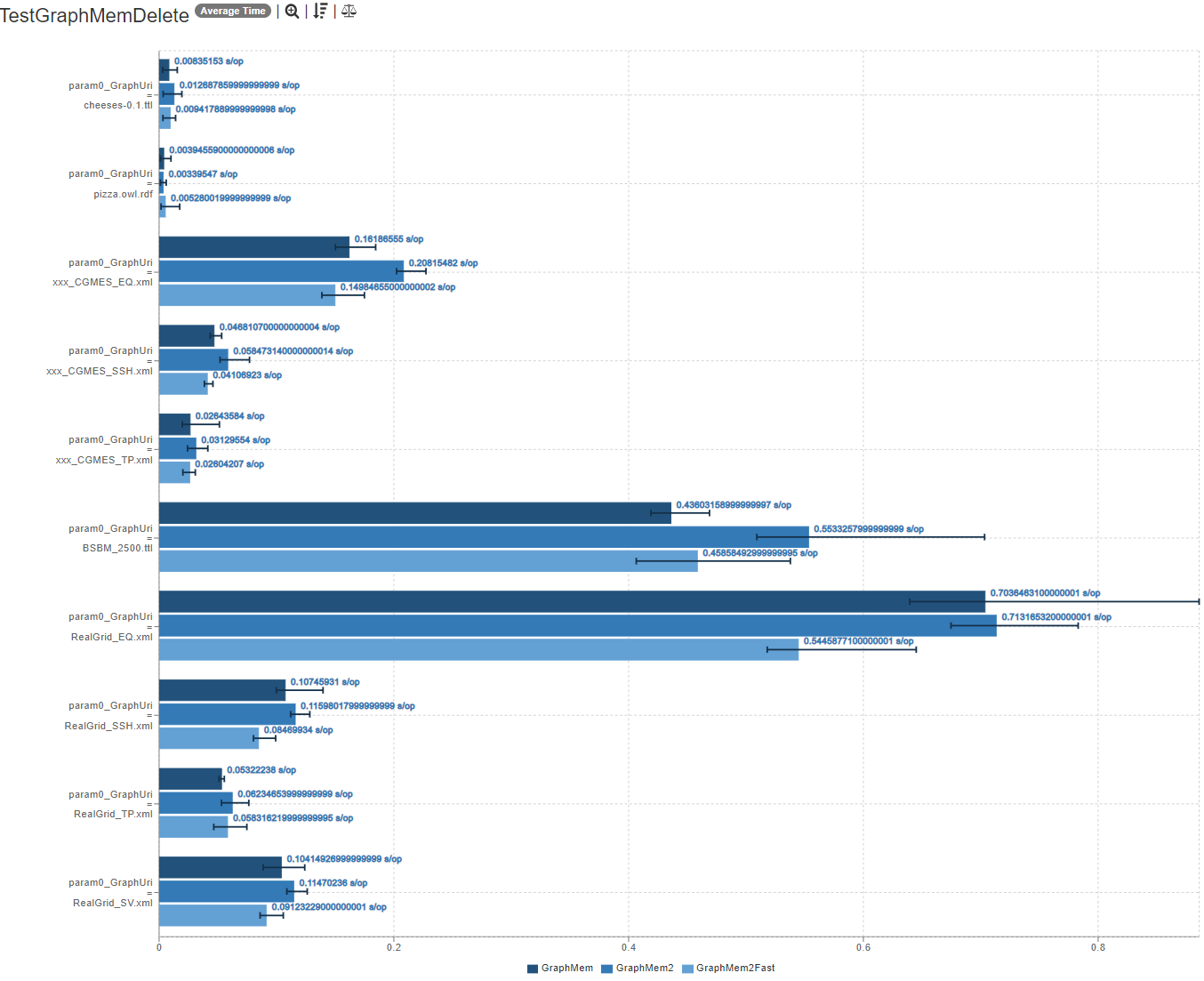
- Graph#delete
These and more benchmarks including Graph#stream, a big BDBM graph and different permutations of Graph#find as JMH JSON results:
- TestGraphMem_20220609.zip, which can easily be browsed via https://jmh.morethan.io/
code is not yet merged to this PR
The main work is finished in my option. The code is not yet merged into this PR as it ist not yet well documented and the additional classes need additional tests first. (althoug the jena project fully compiles and all tests are green, when I replace GraphMem by GraphMem2)
I would like to propose GraphMem2 as a replacement for GraphMem based on the benchmarks and the memory consumption. If i see it right, it outperforms GraphMem in all disciplines (except deletion) while generally having a slightly lower or comparable memory footprint.
GraphMem2Fast is faster at Graph#add and Graph#delete (comparable to GraphMem) while it uses more memory, which could be a problem when it is used in existing solutions. On the other hand, GraphMem2Fast has the same hashCode semantic as GraphMem where GraphMem2 uses a slightly different semantic. So with some graphs, where hash collisions might be an issure one can switch between the two implementation and use the one that is better suited.
Latest sources: https://github.com/arne-bdt/jena/tree/GraphExperiments GraphMem2: https://github.com/arne-bdt/jena/blob/GraphExperiments/jena-core/src/main/java/org/apache/jena/mem2/GraphMem2.java GraphMem2Fast: https://github.com/arne-bdt/jena/blob/GraphExperiments/jena-core/src/main/java/org/apache/jena/mem2/GraphMem2Fast.java
Latest update 2022.05.22 with bad and good news
bad news first
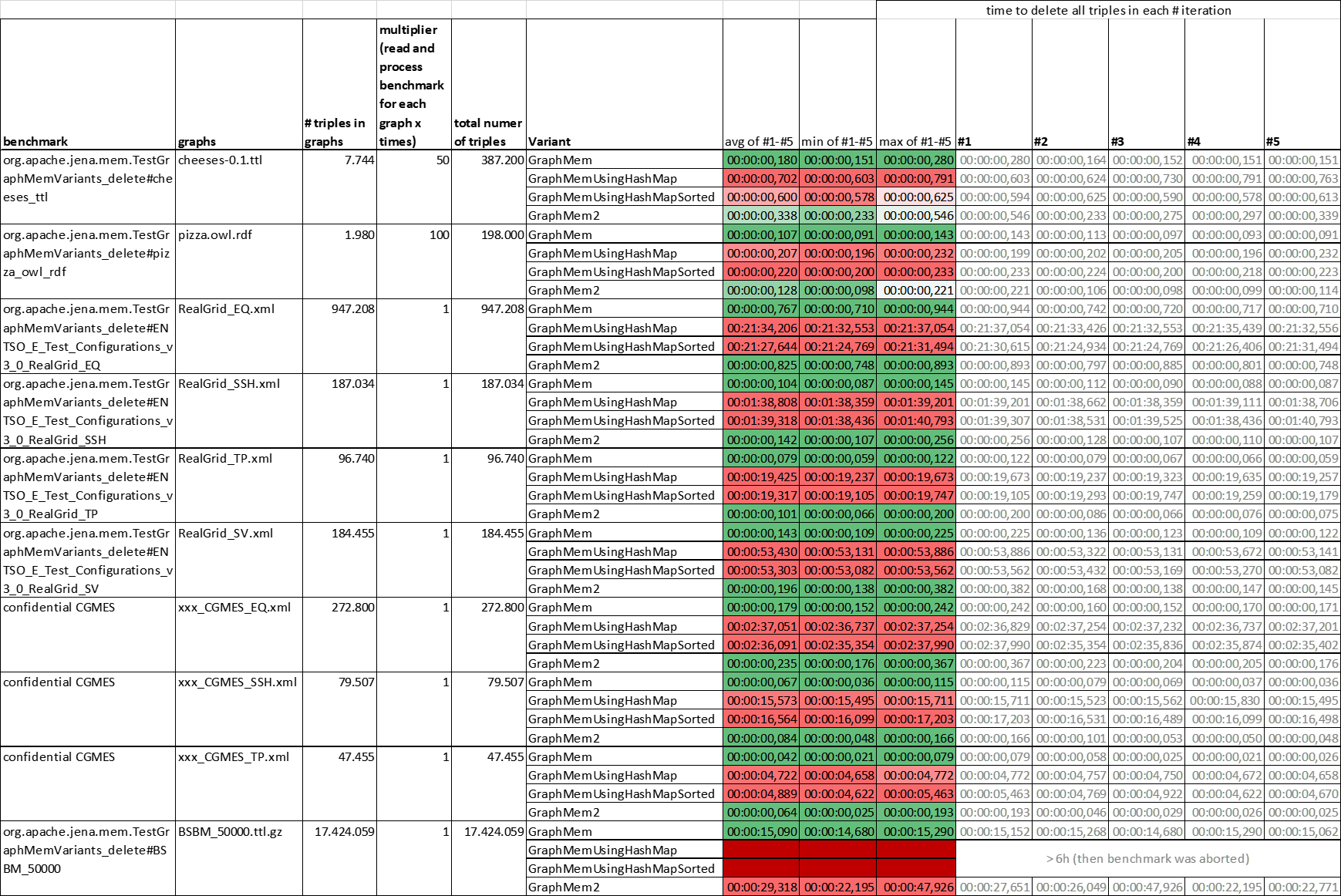
- GaphMemUsingHashMaps is not a valid replacement for GraphMem, as Graph#delete is useless due to poor performance.
- In our use case, where we only append deltas with deletions and additions, removing triples unfortunately practically did not occur.
- The results are so poor that the improved performance in other disciplines cannot compensate for the practically non-working Graph#delete.
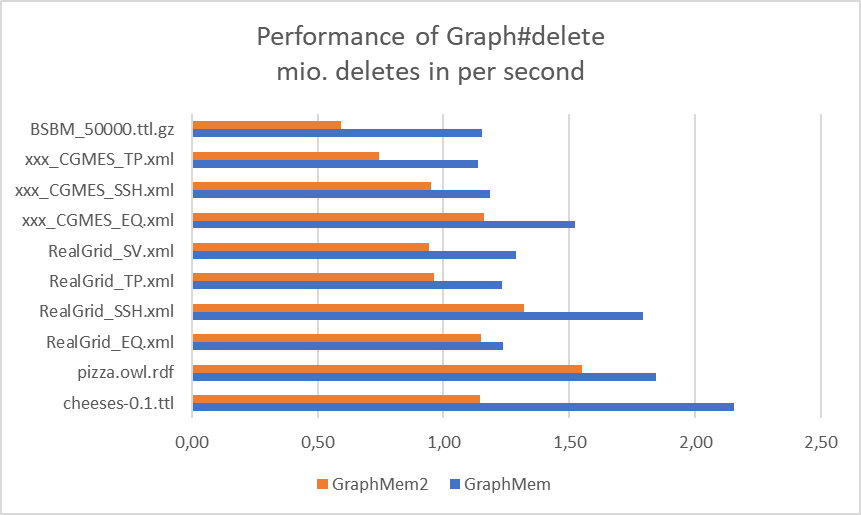
- Graph#delete benchmarks:
good news second
- GaphMemUsingHashMaps or GraphMemUsingHashMapSorted are really great if you only use Graph#add and Graph#find, but never Graph#delete ;-)
- Since I arrogantly and boldly proclaimed to provide an alternative to GraphMem and it is already marked as obsolete, I will provide a candidate (GraphMem2) for your evaluation that is smaller and faster than GraphMem (in most cases). However, it is slower than GaphMemUsingHashMaps in most cases (except Graph#delete). It took me quite some time and work to be confident to be able to provide such a solution. (so I have been a little unresponsive in the last few weeks)
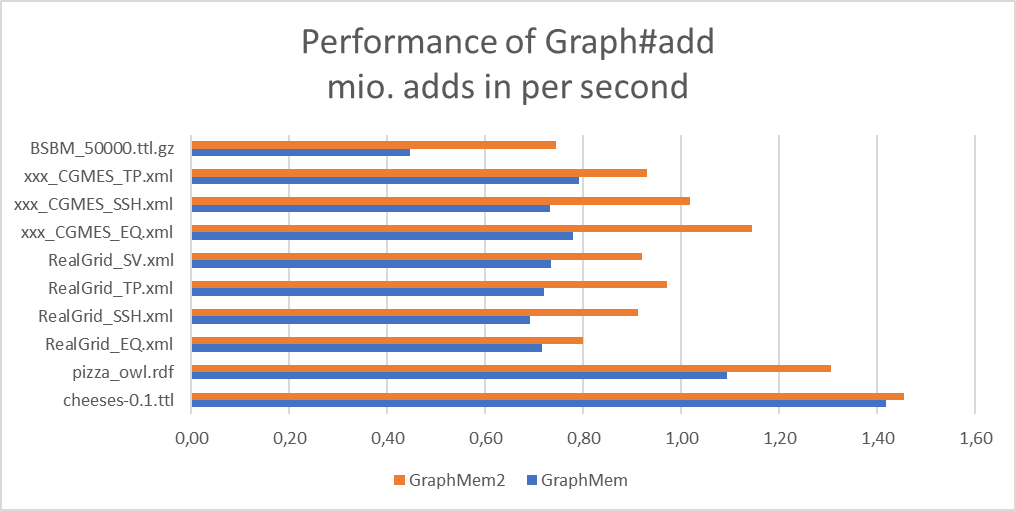
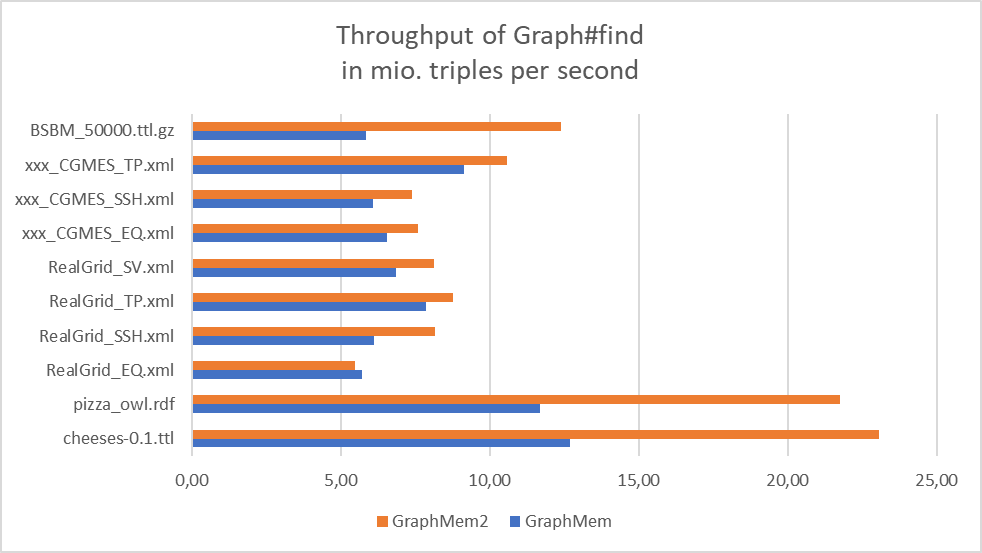
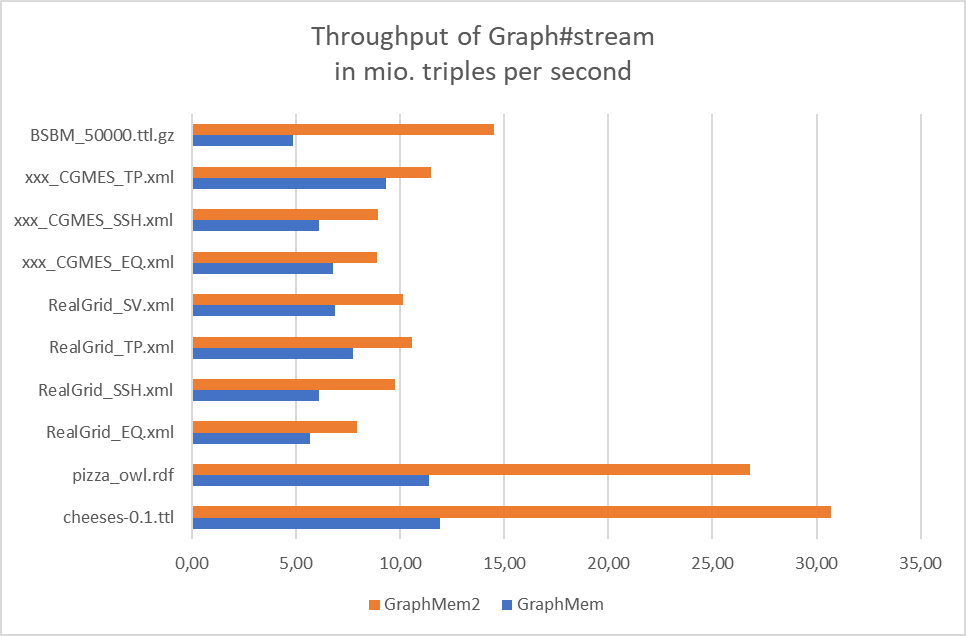
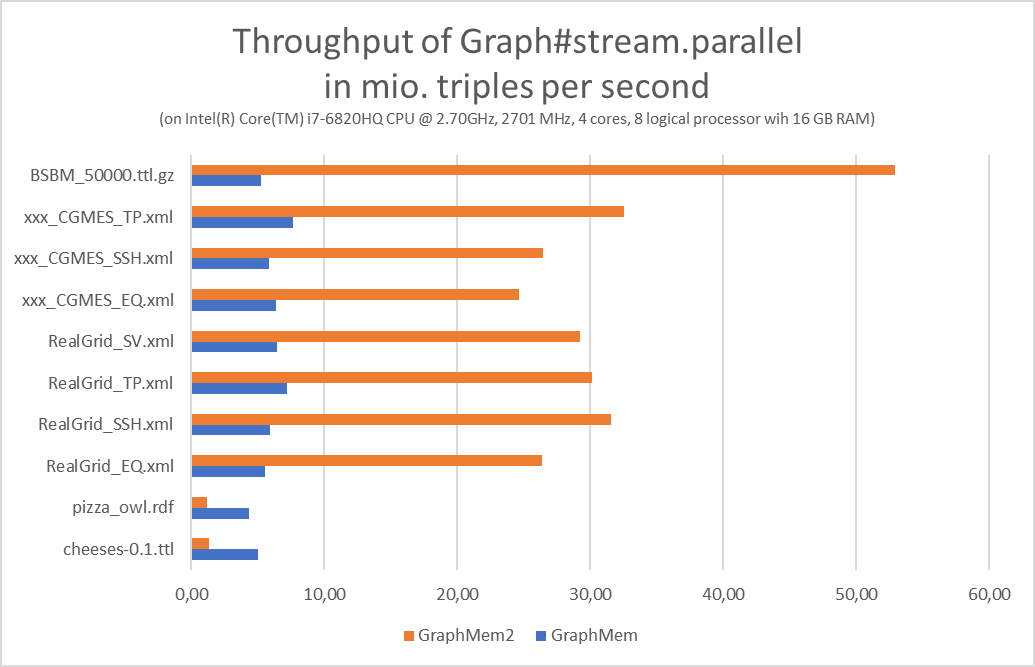
- Benchmarks for Graph#add, Graph#find, Graph#stream and memory:
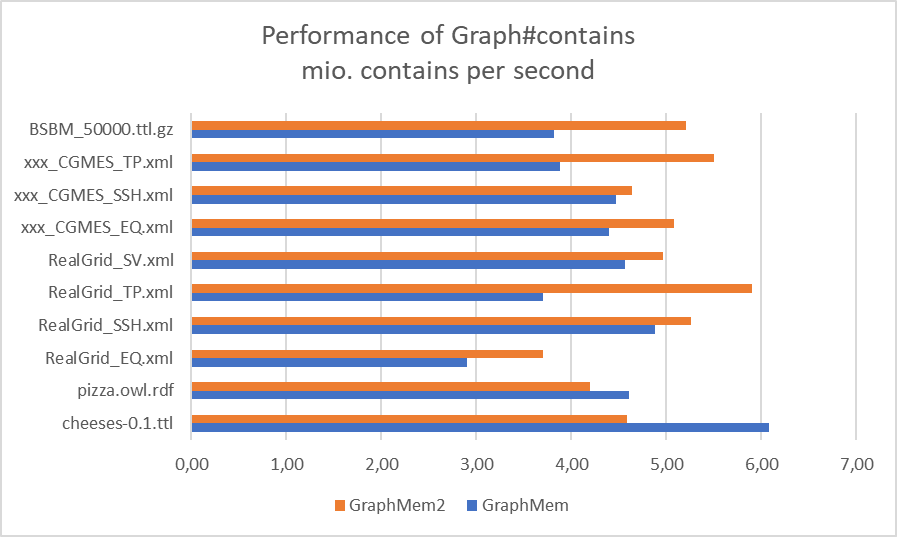
- Benchmarks of GraphMem2 for Graph#contains:
- Benchmarks of GraphMem2 for Graph#delete:
- Benchmarks as spreadsheets: graph_benchmarks_20220522.xlsx
- The GraphMem2 code is still a bit messy and has become much more complicated than GaphMemUsingHashMaps. I will write tests for the additional classes, add documentation and describe them properly in the next weeks.
Outdated old deskription:
Added GraphMemUsingHashMap to replace the now deprecated GraphMem implementation:
-
This implementation basically follows the same pattern as GraphMem: - all triples are stored in three hash maps: - one with subjects as key, one with predicates as key and one with objects as key
-
Main differences between GraphMemUsingHashMap and GraphMem: - GraphMem uses its own hash map and triple bag implementations while GraphMemUsingHashMap uses the standard java HashMap<K,V> and ArrayList<T>. - GraphMemUsingHashMap optimizes find operations by - implementing every possible permutation to avoid unnecessary repeated condition checks (Node.isConcrete) - careful order of conditions to fail as fast as possible - GraphMemUsingHashMap has the Graph#stream operations implemented as real java streams considering the same optimizations as the find operations and not wrapping iterators to streams. - GraphMemUsingHashMap optimizes memory usage by using Node.getIndexingValue().hashCode() as hash keys instead of the Node.getIndexingValue() object itself. This is totally fine, because values are lists.
-
Benchmarks show that: - adding triples is much faster than on GraphMem - for large graphs this implementation need less memory than GraphMem - find and contains operations are a bit faster than GraphMem - stream operations are faster than GraphMem ( and can be accelerated even more by appending .parallel() )
-
The ExtendedIterator<> returned by Graph#find calls supports .remove and .removeNext to make it fully compatible with the usages of GraphMem in the whole jena repository.
Factory --> now creates GraphMemUsingHashMap where it created GraphMem before.
Tests added: package org.apache.jena.mem.test: TestGraphMemUsingHashMap, TestGraphMemUsingHashMap2, TestGraphMemUsingHashMapPackage package org.apache.jena.mem: GraphMemUsingHashMap_CS.java
The following members of GraphMemBase were moved to the deprecated GraphMem:
- public final TripleStore store;
- protected abstract TripleStore createTripleStore();
- protected final boolean isSafeForEquality( Triple t )
Now deprecated in package org.apache.jena.mem:
- ArrayBunch
- BunchMap
- GraphMem
- GraphTripleStore
- GraphTripleStoreBase
- GraphTripleStoreMem
- HashCommon
- HashedBunchMap
- NodeToTriplesMap
- NodeToTriplesMapBase
- NodeToTriplesMapMem
- ObjectIterator
- SetBunch
- StoreTripleIterator
- TripleBunch
- WrappedHashMap -> all usages in the project are replaced by the new GraphMemUsingHashMap only the old tests remain, which are also marked as deprecated: package org.apache.jena.mem.test: TestArrayTripleBunch, TestGraphMem, TestGraphMem2, TestGraphMemPackage, TestGraphTripleStore, TestHashCommon, TestHashedBunchMap TestHashedTripleBunch, TestTripleBunch, TestWrappedSetTripleBunch package org.apache.jena.mem: ArrayBunch_CS, BunchMapContractTest, GraphMem_CS, GraphTripleStore_CS, GraphTripleStoreMem_CS, HashedBunchMap_CS, HashedTripleBunch_CS, SetBunch_CS, TripleBunchContractTest, WrappedHashMap
ModelExpansion.java
- fixed a bug: modifying the collection while iterating on it
Dirty fixes due to different order when returning triples from Graph#find:
- AbstractResultSetTests.java
- ModelCom.java
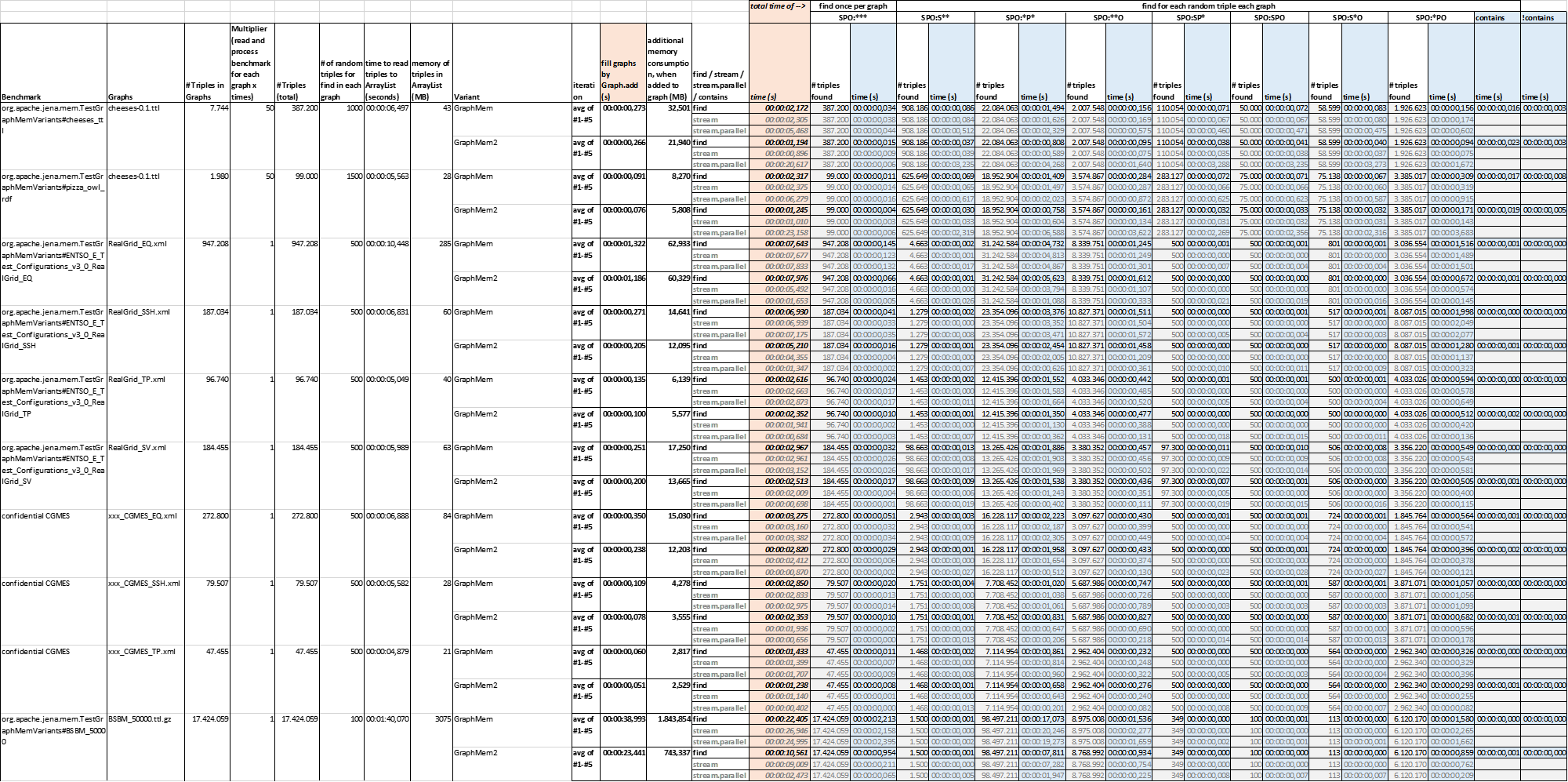
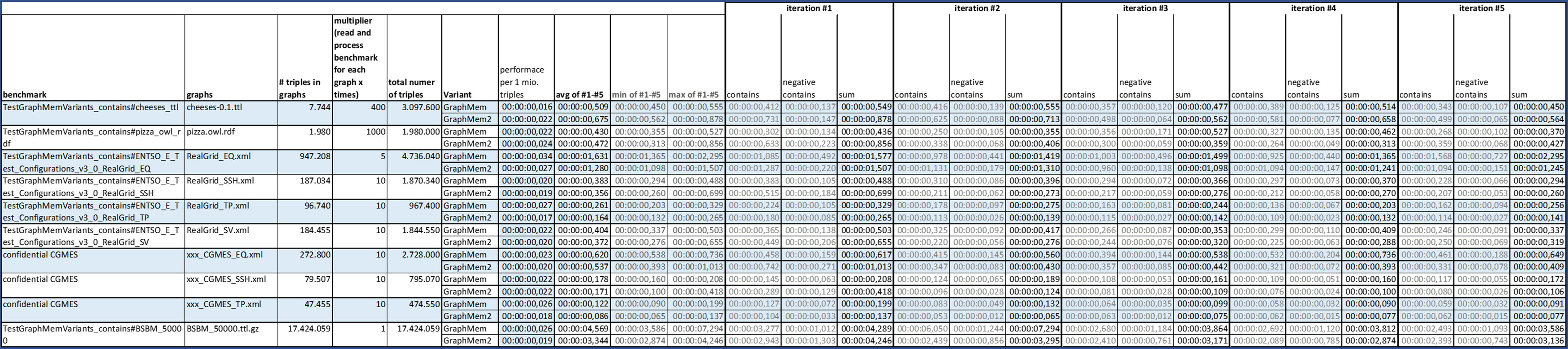
Benchmarks & methology: The benchmark tests have not been added to the PR but are available in my branch GraphMemUsingHashMapSorted. org.apache.jena.mem.TestGraphMemVariants:
- mainly measures Graph#add, Graph#find and Graph#stream
- find and steam are testet against all permutations of subject, predicate and object are measured org.apache.jena.mem.TestGraphMemVariants_contains:
- focuses on Graph#contains only for existing and non-existing triples
General benchmark methology:
- one or multiples graphs are loaded from disk into one or multiples lists (org.apache.jena.mem.GraphMemWithArrayListOnly)
- for each graph implementation a graph is created and all triples from the list are added via Graph#add (depending on the setup this is done multiple times to simulate working with many small graphs)
- for positive tests, random triples are selected from the initial list and stored in a seaparate list
- for negative Graph#contains tests, a list with random triples is generated
- Graph#find is testet for reach triple in the positive list. The resulting iterator is processed to count the matches.
- for streams only stream.count is measured, which seems to use shortcuts if the undderlying collection is not filtered and provides Collection#size. So some measurements show no time where streaming all triples would have consumed more time.
- org.apache.commons.lang3.time.StopWatch is used to measure execution times
- memory is measured by running org.apache.jena.mem.TestGraphMemVariantsBase#runGcAndGetUsedMemoryInMB, which seems to work pretty well and stable.
Results: graph_benchmarks_20220502.xlsx
My interpretation of the benchmark results:
-
Memory consumption of GraphMemUsingHashMap less. On with small graphs, the difference is negligible, on large graphs it is signiffcant.
-
Graph#add --> GraphMemUsingHashMap is always 2-4 times faster than GraphMem. (except for pathologcal cases: see below)
-
Graph#find --> GraphMemUsingHashMap is always 2-4 times faster than GraphMem.
-
Graph#contains --> having an equal number of positive and negative tests, the overall performance of GraphMemUsingHashMap is 2-3 times better than GraphMem (except for pathologcal cases: see below)
-
ATTENTION: For Graph#contains with only positive matches, GraphMem is always faster than GraphMemUsingHashMap. In some cases 3 times faster.
-
Graph#stream is not covered by this test setup due to possible shortcuts of Steam#count
- though, other experiments not covered here, show that Graph.steam().parallel() works pretty well on GraphMemUsingHashMap and not very well on GraphMem.steam()
"pathological case where every triple has the same subject" In the discussion below rvesse mentioned cases where there are few subjects with each containting many predicates and objects. In the sample graphs, there is one "RealGrid_SV.xml" with data matching this description. In this case Graph#add and Gaph#contains are getting increasingly slow. So I did some benchmarks that point out the problem: graph_benchmarks_contains_20220504.xlsx
I followed the tip to perform "the contains() scan on the smallest list (or if any list is empty bypassing it entirely)" - maybe it was too late in the night - but unfortunately, the overall perfomance was even worse. So I tried a different approach by having sorted lists of triples in the node maps. After testing with different combinations of wich maps to sort by which criteria I ended with a new implementation GraphMemUsingHashMapSorted in a separate branch. GraphMemUsingHashMapSorted sorts all lists in the subject map by object (indexingValue.hashCode) when they reach 40 entries. New entries are then inserted at the correct position (using binary search) to keep the lists sorted. In my test cases I could not find ways to take further advantage of the sorted lists in Graph#stream or Graph#find. It is only used in Graph#add and in Graph#contains in the case where subject, predicate and object are concrete. Comparing GraphMemUsingHashMap and GraphMemUsingHashMapSorted the benchmarks show:
- in most cases the performance of Graph#.add in GraphMemUsingHashMapSorted is almost equal to GraphMemUsingHashMap. - in the pathological cases GraphMemUsingHashMapSorted is much faster than GraphMemUsingHashMap
- in most cases Graph#.contains in GraphMemUsingHashMapSorted is a tiny bit slower than GraphMemUsingHashMap. (the smaller the graph the bigger the differnce) - in the pathological cases GraphMemUsingHashMapSorted is much faster than GraphMemUsingHashMap If anywone has ideas on how to improve GraphMemUsingHashMapSorted or has ideas for different apporaches, please send them to me!
Quick comment: the @since attribute doesn't seem to admit a descriptive comment as you have here, but merely a software version. I think you'd do better to use the @deprecated tag on the Javadocs instead.
Quick comment: the
@sinceattribute doesn't seem to admit a descriptive comment as you have here, but merely a software version. I think you'd do better to use the@deprecatedtag on the Javadocs instead.
Thank you! I fixed it by adding @deprecated in javadoc commets. Hopefully @Deprecated(since = "4.5.0") is okay?
It would also be nice to get some more context around the motivation for this change. While "faster and less memory" is noted in the title and description presumably the need for this to be faster and use less memory was originally motivated by performance issues in use case(s) you have?
Knowing the use case(s) would also be useful to understand whether there are other solutions to your performance issues
Quick comment: the
@sinceattribute doesn't seem to admit a descriptive comment as you have here, but merely a software version. I think you'd do better to use the@deprecatedtag on the Javadocs instead.Thank you! I fixed it by adding @deprecated in javadoc commets. Hopefully @deprecated(since = "4.5.0") is okay?
Yes, that would be appropriate, but see @rvesse's comment about the speed of deprecation.
It would also be nice to get some more context around the motivation for this change. While "faster and less memory" is noted in the title and description presumably the need for this to be faster and use less memory was originally motivated by performance issues in use case(s) you have?
Knowing the use case(s) would also be useful to understand whether there are other solutions to your performance issues
Since 2017, we are developing an event sourcing in memory graph database, following the CQRS pattern. Every transaction is written to a new delta graph (not the jena Delta but a variation). Delta graphs are chained until the next snapshot. SPAQRL queries are executed on ad hoc created datasets (not the jena DatasetGraphMapLink but a variation) to support temporal queries (versioning) and additional contexts.
The way of tracking changes as deltas seems similar to the approach of RDF Delta, which I recently discovered. But we support also git-like branching and merging on graphs / datasets.
The database is customized to our domain. For example, to support the reuse of SPARQL queries with named graphs, we have query contexts like version, timestamp, business process or client.
The events with the graphs and delta graphs as payload are written to a relational database (Oracle or Postgres). They are serialized as RDFThriftValues and LZ4 compressed for optimal IO performance. Loading the graphs currently is not fast enough. We are working on a better parallelization but making the graphs add tripples faster is also an option.
In our graphs, the number of entities typically does not grow over time. Also the number of graphs in our use cases does not grow over time. So we are confident so be able to always hold all needed data in memory.
In one common use case we have each named graph 24 times representing 24 differnt timestamps (hours). Since there are only small differnces between the hours, we only keep the full graph for the first hour and use delta graphs (each having the first hour as base graph) to represent the remaining hours. We do have 1 day scenarios with 3644 graphs on one node using up to 24 GB of memory. Next year we will have 7 day scenarios. So it would be a great relief if graphs needed less memory.
Meanwhile, we are looking into the possibility to distribute the graphs on several nodes and use federated queries under the hood. Storing the event chain in Apache Kafka and the payloads (graphs and delta graphs) in MinIO is one possible path on our roadmap.
Hi @arne-bdt,
Good to see this PR. The requirement for large in-memory graphs has been growing in recent years. The origins of the custom indexing was to save space - I'm sure the JDK has significantly improved since the work on more compact indexes was done sometime ago.
One of the few changes to GraphMem over the years has been to increase the range of sizes the custom hash maps can handle. Having something faster loading and more space efficient is good to have.
Could you please create a GitHub issue (or a JIRA) for recording this?
I've only started to look at the code - the comments are very helpful in getting to understand it.
I have built the code and also run the tests suite done a build/test with GraphMem deleted from the codebase so as to force the new code to be used. All passes - one comment about TestPackage.
Legal
Presumably, this is work done during your employment at Soptim and that Soptim is the legal owner of the work. As this is a significant and important contribution to Jena, we ought to get the legal side clear. It is always better to do legal matters early.
To be clear about the contribution, would a contribution agreement be possible?
These are available at: https://www.apache.org/licenses/contributor-agreements.html
For a single, one off software contribution, there is the Software Grant.
Or for this and any future contributions, there is the Corporate Contributor License Agreement (CCLA).
It needs to be signed by some at Soptim entitled to make the legal declaration.
Migration
Apps should not be hooking into the GraphMem machinery. All application use of memory graphs should be via org.apache.jena.graph.Factory (which is now a rather out-of-place name ... but one thing at a time).
For merging into Jena and switching over, how does this sound:
We're approaching Jena 4.5.0 very soon (roughly, as soon as possible). It includes switching to JSON-LD 1.1 so I'd prefer not to hold it up.
As soon as that is done, and the legal is done, we can merge this PR. We can announce on users@ that the code is changing and invite people to test development builds (don't expect many to actually do that! but we can at least make the offer).
Then release Jena 4.6.0 sooner than the usual 3-4 month clock tick. There is at least one other significant PR in progress and nearly ready (SHACL related - not as central as this one). This is quite convenient because JSON-LD 1.0 to 1.1 isn't a simple matter as there are spec changes to data so the chance to fine tune Jena use of the JSON-LD engine (Titanium) we use for JSON-LD 1.1 might be needed anyway.
I don't know what the rest of the team think but personally my objective is to remove the old GraphMem code as soon as possible and not have it in the codebase. It's not like we can't get it back from git or a release. At least move it elsewhere.
The best I can think of for migration is to mark GraphMem deprecated in 4.5.0 to notify any app that is directly calling the constructor. May be also do the same for Factory.createGraphMem.
We can let users know change is coming by putting something in the 4.5.0 release announcment message as well.
Other
commits fb232336ac, cce5c920f9, 2c89182dfa - these don't follow the git convention of one short line, then one blank line, then long text. Tools sometimes assume this. Example: git log -5 --format='[%h] %ae (%ar) - %s.
Issue #1277 - deprecation of GraphMem at Jena version 4.4.0
Issue #1279 - track this PR
How large should I think large graphs?
There must come a point where very large data ought to have a different backing graph for practical reasons like start-up.
BSBM triples take up more space than average - a lot of long literals in the generated data. Just tried old GraphMem : 50m of BSBM took 14G RAM.
Experience of ArrayList is that the way it resizes isn't great for 0 to many million. It only grows by 50% per resize so there is a lot of resize copying going on. If we wanted faster loads, requiring a "large graph" indicator and then an array implementation that was chunked and with a faster growth factor would be better. But not today!
JENA-1142 :: 100e6 triples where the extension of the hash tables is not so much the scale but to have a soft limit rather than a hard limit.
An extreme report was JENA-1726 but that was a reported CONSTRUCT query where a lot of RAM was already being used by the query itself in the path evaluation so we don't know enough details. The tables were extended but again it is to have a soft limit "just in case". We didn't hear back from the reporter. For most cases there is QueryExecution.execConstructTriples to get extreme results (may be not the path case here but we known know for sure).
@arne-bdt - looking at the reviews, I think we're nearly done. There was one comment about iterator remove - how many test are affected?
I think @rvesse's review comment is about migration. Jena 4.5.0 is out, the announcement has a lookahead to the change-over and some deprecation for direct use of GraphMem.
Does that sound right or have I missed something?
Then, a bit of preparation for merging, tidying up the history and the legal side.
Looking good!
@arne-bdt - looking at the reviews, I think we're nearly done. There was one comment about iterator remove - how many test are affected?
I think @rvesse's review comment is about migration. Jena 4.5.0 is out, the announcement has a lookahead to the change-over and some deprecation for direct use of GraphMem.
Does that sound right or have I missed something?
Then, a bit of preparation for merging, tidying up the history and the legal side.
Looking good!
@afs - Last week, I had to set this PR back to draft and updated the upper desciption accordingly. I added Grap#delete tests to my benchmarks, which showed desaterous performance on that task. Unfortunately, in our use case, where we only append deltas with deletions and additons, removing triples did practically not occur. Since then, I am trying to solve it using different approaches. I plan to share about my process and perspectives next Sunday.
There is also a second issue, which I added in upper the description: ""pathological case where every triple has the same subject" In the https://github.com/apache/jena/pull/1273#discussion_r858521057 below rvesse mentioned cases where there are few subjects with each containting many predicates and objects. In the sample graphs, there is one "RealGrid_SV.xml" with data matching this description. In this case Graph#add and Gaph#contains are getting increasingly slow. So I did some benchmarks that point out the problem: graph_benchmarks_contains_20220504.xlsx
I followed the tip to perform "the contains() scan on the smallest list (or if any list is empty bypassing it entirely)" - maybe it was too late in the night - but unfortunately, the overall perfomance was even worse. So I tried a different approach by having sorted lists of triples in the node maps. After testing with different combinations of wich maps to sort by which criteria I ended with a new implementation GraphMemUsingHashMapSorted in a separate branch." --> After weighing the pros and cons, it seems to me that this approach is more suitable. However, solving the deletion problem here is probably even more difficult. So far, I have not received any feedback on this approach or the benchmarks.
Counting the tests is not easy, as many of them are simply not recognized in my IDE or are only listed as warnings despite errors and Maven stops after the first error. I found usages of org.apache.jena.util.iterator.ExtendedIterator#removeNext in:
- org.apache.jena.ontology.impl.OntClassImpl#setSubClass
- org.apache.jena.ontology.impl.OntPropertyImpl#setSubProperty and in the following tests:
- org.apache.jena.graph.GraphContractTest#testSizeAfterRemove
- org.apache.jena.graph.GraphContractTest#testBrokenIndexes
- org.apache.jena.graph.GraphContractTest#testBrokenPredicate
- org.apache.jena.graph.GraphContractTest#testBrokenObject
I found potentially relevant uses of java.util.Iterator#remove in at least the following places:
- 7 usages in org.apache.jena.sparql.*
- 6 usages in org.apache.jena.reasoner.*
- org.apache.jena.assembler.ModelExpansion#removeElementsWithoutType
- org.apache.jena.geosparql.configuration.GeoSPARQLOperations#convertGeometryStructure(org.apache.jena.rdf.model.Model)
The legal side is moving forward. Our board is proceeding with caution, which seems reasonable since we don't yet have established processes or policies for code contributions, and we have a lot of sensitive data that should never become part of a test suite, for example.
If you point me at ExtendedIterator.remove in org.apache.jena.sparql.*, I'll check them and rewrite suspect ones.
If it easier for your board, the Software Grant is for a specific body of code.
There is also a second issue, which I added in upper the description: ""pathological case where every triple has the same subject" In the #1273 (comment) below rvesse mentioned cases where there are few subjects with each containting many predicates and objects. In the sample graphs, there is one "RealGrid_SV.xml" with data matching this description. In this case Graph#add and Gaph#contains are getting increasingly slow. So I did some benchmarks that point out the problem: graph_benchmarks_contains_20220504.xlsx
So I wouldn't get too worried about the pathological cases at large scale. I just wanted to point that they exist, it's fine if for those cases performance drops off at scale but looking at the attached spreadsheet it seems like performance is still much better in most cases.
I followed the tip to perform "the contains() scan on the smallest list (or if any list is empty bypassing it entirely)" - maybe it was too late in the night - but unfortunately, the overall perfomance was even worse.
Sometimes ideas don't pan out. I suspect for this one that in most cases the individual lists are relatively small anyway so the cost of retrieving them from their respective hash maps actually outweighs the cost of scanning through the first list you retrieve (at least in aggregate terms)
So I tried a different approach by having sorted lists of triples in the node maps. After testing with different combinations of which maps to sort by which criteria I ended with a new implementation GraphMemUsingHashMapSorted in a separate branch." --> After weighing the pros and cons, it seems to me that this approach is more suitable.
We can always iterate and improve on the implementation later, having the initial improvement is a good first step. Don't get too hung up on getting this perfect first time.
However, solving the deletion problem here is probably even more difficult.
I don't see anything in the numbers that actually shows the deletion problem, can you expand on that?
In general I would expect that most of the time things are added to in-memory graphs rather that removed from them. So in aggregate the improved performance for the add/contains may balance out any performance loss on deletion.
@rvesse : Thank you very much for your motivating words. That was quite helpful, when I got frustrated in the last days. I updated the PR description, including the devastating Graph#delete benchmarks.
We can always iterate and improve on the implementation later, having the initial improvement is a good first step. Don't get too hung up on getting this perfect first time.
You defintivley got a point here. But I made a promise to the community and I want to keep it. Even though I was unsure if I could do it. In the last week I have regained a little of my confidence and hope that this time I have not missed anything.
To make Graph#delete work, I implemented a deviation of the HashedTripleBunch as LowMemoryHashSet. With the right iterators and spliterators, it provides good retrieval performance. My removal algorithm is not optimized yet, and maybe I will leave it that way, because I want to have everything ready before the summer vacations.
I'm eager to hear feedback on the benchmark tables once I've finished preparing them. Most recently, I kept discovering anomalies during the preparation that had escaped me before.
If you point me at
ExtendedIterator.removeinorg.apache.jena.sparql.*, I'll check them and rewrite suspect ones.
Sorry, I didn't mean to point at anyone. It seems that it's pretty common in the core Java libraries to work with iterator#remove, and they have sophisticated solutions to support it. I didn't know this before and thought changing a collection during iteration was an anti-pattern.
If it easier for your board, the Software Grant is for a specific body of code.
We had a meeting with our lawyer who had some questions about our intentions. The general feedback was positive and he will give his final feedback shortly.
Please comment on the new benchmarks (see PR-description above) for Graph#add, Graph#find, Graph#stream, memory consumption and Graph#contains!
My general conclusions are:
- GraphMem2 is always faster at Graph#add
- GraphMem2 is always faster at Graph#stream
- GraphMem2 always requires less memory than GraphMem (but the relative savings are very different)
- with GraphMem2 Graph#stream is (almost) always faster than Graph#find and should be prefered in the future
- GraphMem2 is not as fast as GraphMem at Graph#delete, but in my opinion it should be fast enough
Things I recognized:
- only with the samle graph "RealGrid_EQ.xml" GraphMem2 is a bit slower at Graph#find -> I don´t know why
- only on the small sample graphs "cheese-0.1.ttl" and "pizza.owl.rft" GraphMem2 is slower at Graph#contains -> I don´t know why
- in the first iteration Graph#contains always takes pretty long with GraphMem2 -> the relative difference is striking
- GraphMem practically does not support Graph#stream.parallel
- Graph#stream.parallel has problems with small graphs, but that seems to be "normal", as it is the same with simple ArrayLists
Are you missing any specific benchmarks or information? Am I missing something? Do these benchmarks look promising enough to justify replacing the current GraphMem? (cleaning up and writing more tests is still a lot of work and I don't want to waste my time)
Looking good!
I agree with the conclusions. It is an in-memory graph - adding is more important than delete.
The only odd result - and this is not a concern - is that GraphMem2#stream is faster than GraphMem2#find. My experience has been that Java streams have overhead for setup (several objects). I haven't dug in the code to investigate, and havn't been into the old GraphMem code in depth quite awhile; for me, this is just an item of note, and not a concern. My only thought is to have index direct manipulation of ArrayLists and avoid list iterators, but that is messy code to do and IMO not necessary. If we encounter some unknown use case, we will then have better information to revise the code.
Do these benchmarks look promising enough to justify replacing the current GraphMem? Yes, very much so.
The code works and is better on important cases - the smaller memory footprint is especially welcome.
@arne-bdt - just checking in to see where we are on this pull request.
To sum it up: I estimate this PR to bei ready in August 2022. In have two Implementations ready GraphMem2 and GraphMem2Fast in an other branch. Which one fits best to be a successor of GraphMem is up to you as maintainers. I although the whole jena project with all tests runs perfectly, the additional classes need some unit tests too. I will also have do document and possibly rename some things to clean up. I have been sick for almost two weeks and now my vacation has started, so I am sorry I was not able to complete the PR before my vacation, as I had planned.
Sorry to hear you've been ill. I hope you still get a proper vacation.
Releases happen on a clock-tick, not based on features. We release at regular intervals and likely at the end of this month (July).
The contribution work is done when it's done! So if it is in August that's fine.
Looking forward to seeing GraphMem2 and GraphMem2Fast.
Take care /Andy
FYI: We have learn from the process experience and added a PR template that mentions contributions are under the Apache Contributors Agreement.
Hi @arne-bdt,
Would it be a good idea to put in this PR in its current state as a replacement for the existing (and difficult to maintain) GraphMem?
It can be replaced again later. No application should be depending on implementation classes.
Hi @arne-bdt,
Would it be a good idea to put in this PR in its current state as a replacement for the existing (and difficult to maintain) GraphMem?
It can be replaced again later. No application should be depending on implementation classes.
Hi @afs, I'm sorry that my prediction to finish the work on this PR by the end of August was wrong. This PR still refers to a branch with a graph that I would only use for very specific use cases and that is not a replacement for GraphMem.
I still plan to move two candidates (currently called GraphMem2 and GraphMem2Fast) from https://github.com/arne-bdt/jena/tree/GraphExperiments to this PR that would make a good replacement for GraphMem. My code needs more testing, documentation, renaming, and cleanup to end up with a maintainable solution.
Could you perhaps help me with the following questions?
- where should I add JHM benchmarks? To get reliable benchmarks, I needed to introduce JMH. I could easily integrate them into the tests of jena-arq. Would it be appropriate to add a new project called "jena-benchmarks-jmh" and move the benchmarks there?
- where can I get more graphs? In the jena repository I could only find "cheeses-0.1.ttl" and "pizza.owl.rdf" as small sample graphs. The graphs I use at work are strictly confidential. There are some comparable graphs provided by ENTSO-E in their conformity assessment, which I can only refer to but not include in the repository. I have created additional graphs using [datagenerator] (http://wbsg.informatik.uni-mannheim.de/bizer/berlinsparqlbenchmark/spec/BenchmarkRules/index.html#datagenerator), but the files are quite large and I am not sure whether to include them in the repository. The benchmarks behave differently for each type of graph. Sometimes due to hash collisions or different distributions of subjects, predicates and objects. The current results look good to me, but it should be easy for any user to validate their graphs against different graph implementations. I think it would be nice to have a public repository with example graphs and even large graphs to have a common base for benchmarks. --> Maybe "jena-benchmarks-jmh" should be a separate repository that could contain large graphs?
- how to deal with typed literals in example graphs?
Most example graphs seem to be serialized without type information. The benchmarks behave differently if all objects are treated as strings. For our rdf graphs, I implemented a TypedTripleReader that uses the rdf schema files defined by CIM/CGMES. But the implementation felt strange, as this should be a general task.
Is there a simpler, more general way to read graphs with typed literals?
Greetings Arne
Sorry for the delay in replying. Too many things ...
JMH Benchmarks
JMH benchmarks: Jena doesn't have any so we're looking to learn.
If jena-benchmarks-jmh is good practice, then "yes".
One word of warning - our CI environments (Apache run Jenkins, and GitHuib actions) - seem positively troublesome towards our timeout tests. This is because they are heavily loaded virtual machines. Sometimes, they pause for significant periods of time - 30 seconds or more. I think, can't prove, this is mostly likely when they do some external operations such as disk I/O.
But even if they are troublesome, the JMH benchmarks are good to have to be run on less hostile environments.
"where can I get more graphs?"
I've got BSBM in various sizes - for parse speed tests I use 25million - it's large enough for the parser to settle down so that 25m and 50m give the same speed.
25e6, 50e6 and 100e6 from the list below
Temporary: https://drive.google.com/drive/folders/1ev2CCKB0MBqNXhZdsbOIRxQVBH4mJ0tF
bsbm-50k.nt.gz -- File size: 1.4M bytes
bsbm-250k.nt.gz -- 6.7M
bsbm-1m.nt.gz -- 27M
bsbm-5m.nt.gz -- 137M
bsbm-25m.nt.gz -- 660M
bsbm-50m.nt.gz -- 1.3G
bsbm-100m.nt.gz -- 2.6G
bsbm-200m.nt.gz -- 5.2G
bsbm-300m.nt.gz -- 7.8G
bsbm-400m.nt.gz -- 11G
bsbm-500m.nt.gz -- 13G
How we deal with data for JMH at scale is very unclear so for now I suggest easy steps - incorporate the tests, external files, don't run them in the main build yet.
how to deal with typed literals in example graphs
BSBM has xsd:date, xsd:dateTime and xsd:integer in the data.
I'm not saying it has to be BSBM. I use it for parser and loader tests where the characteristic of BSBM that it contains a significant proportion of large literals (100, sometimes 1000's of chars long) is useful so I happen to have it lying around and can generate sets of any size. And having used them over time, I have old figures lying around (a track of the history of hardware!).
I did not want to close this PR entierly. I just needed to cleanup the mess I did with my fork to get a clean start.
Hello @ktk, thank you for asking. This puts me under pressure to finally get to work and finish it. After my naive and arrogant attempt at a first solution, the code has become far more complex and, unfortunately, ugly. Currently it's a "works for me" solution: faster than GraphMem and sufficiently well tested. Meanwhile, the amount of work to complete my contribution has grown significantly:
- start fresh with a new fork of the last Jena version
- make the code more readable without affecting performance
- implement unittests for the new classes
- write clean Java doc comments
- add more detailed Markdown documentation if necessary
- add a JHM benchmark project with sample datasets that can be published
- find out if I should/need to use volatile, similar to the Java ArrayList and HashTable implementations, and what the performance impact will be.
- not be distracted by constantly coming up with new ideas of what else I could try to get more performance out of it
- come to terms with the fact that support for iterator#remove will always be an obstacle to achieving better performance
- find the courage not to buckle under the fear of embarrassing myself in front of the community.
So far, I have not had the courage to tackle this in my limited free time. On the other hand, I have already invested more than 200 hours and would like to make my contribution to Jena. Any push or support is very welcome as motivation. I just don't want to make promises again that I can't keep for sure. Greetings from Belgium Arne