flink1.15.2 or 1.15.1 stream read ,it is pending
Apache Iceberg version
0.14.0 (latest release)
Query engine
Flink
Please describe the bug 🐞
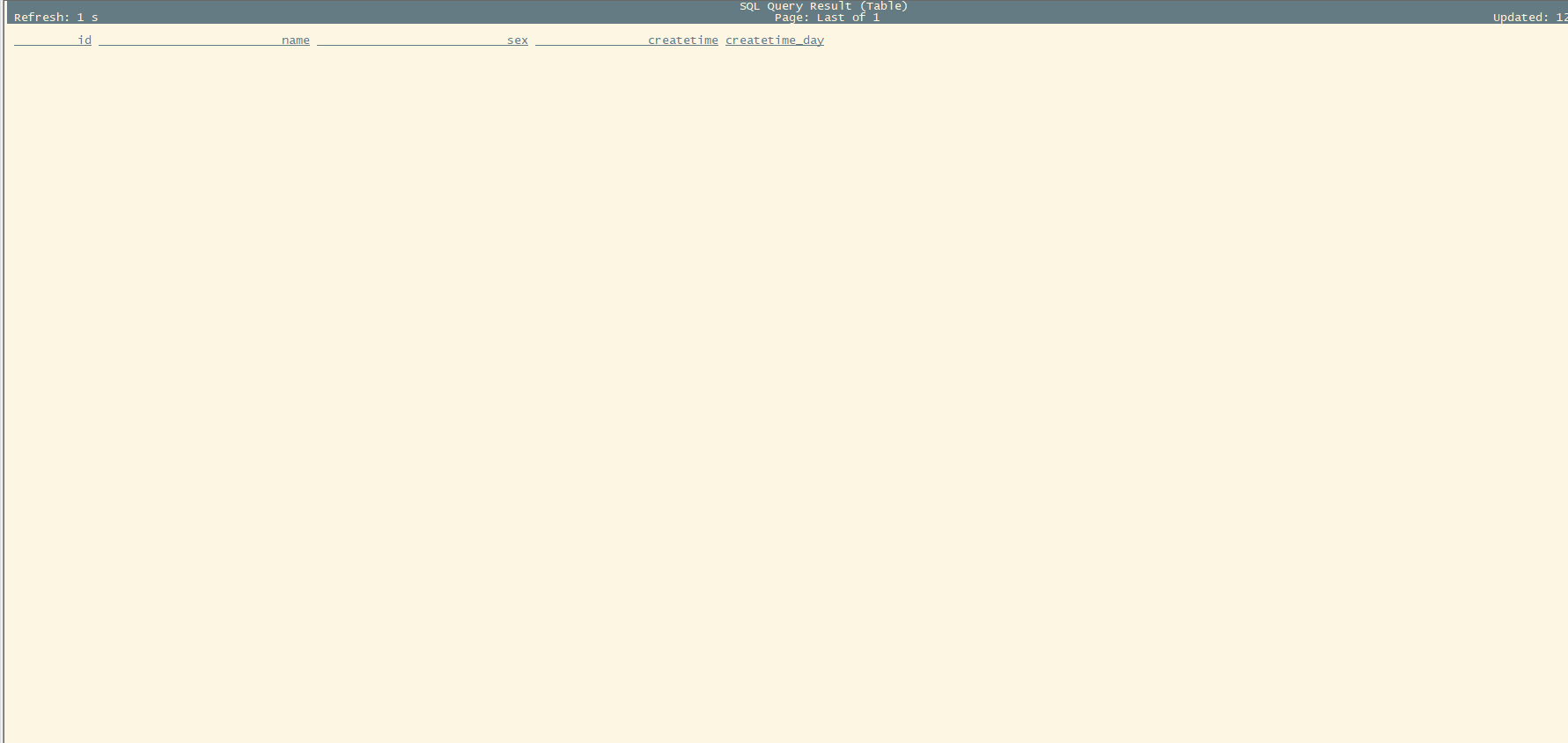
SET execution.runtime-mode = streaming; select * from test /+ OPTIONS('streaming'='true', 'monitor-interval'='1s')/
no result,it is always pending, bath is normal
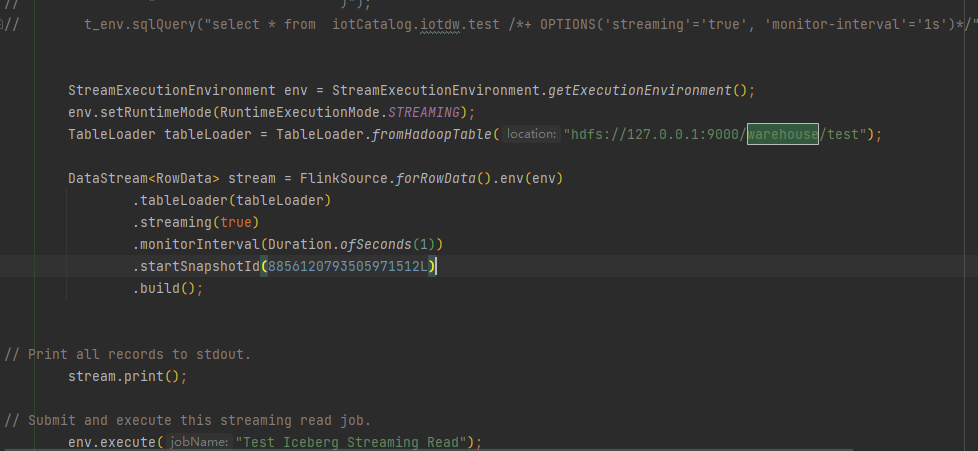 it is always pending, no result
it is always pending, no result
2022-09-20 21:15:43,205 INFO org.apache.flink.api.java.typeutils.TypeExtractor [] - class org.apache.iceberg.flink.source.FlinkInputSplit does not contain a getter for field task 2022-09-20 21:15:43,206 INFO org.apache.flink.api.java.typeutil
@zixiao144 maybe a dumb question. is there any snapshots after the startSnapshotId?
also can you enable DEBUG level logging for StreamingMonitorFunction class? then we can see the split discovery logs. e.g.
LOG.debug(
"Start discovering splits from {} (exclusive) to {} (inclusive)",
lastSnapshotId,
snapshotId);
long start = System.currentTimeMillis();
FlinkInputSplit[] splits =
FlinkSplitPlanner.planInputSplits(table, newScanContext, workerPool);
LOG.debug(
"Discovered {} splits, time elapsed {}ms",
splits.length,
System.currentTimeMillis() - start);
BTW, the FLIP-27 Flink Iceberg source is also merged in the master branch. it is available in 0.14.0 (except for the SQL connector commit and a metrics fix commit). If you are interested in giving it a try, you can refer to the usage in the unit test code.
The benefit of FLIP-27 source for streaming is that it uses pull-based split assignment, which is good for dynamic split assignment and work sharing. Current FlinkSource would assign all discovered splits eagerly to all reader subtasks in a round-robin fashion.
@stevenzwu
I use flink1.15.2's sqlclient.sh .Do simple test.
SET execution.runtime-mode = streaming;
SET table.dynamic-table-options.enabled=true;
or (SET table.exec.iceberg.use-flip27-source = true;)
select * from test /+ OPTIONS('streaming'='true', 'monitor-interval'='1s')/ ;
streaming result:
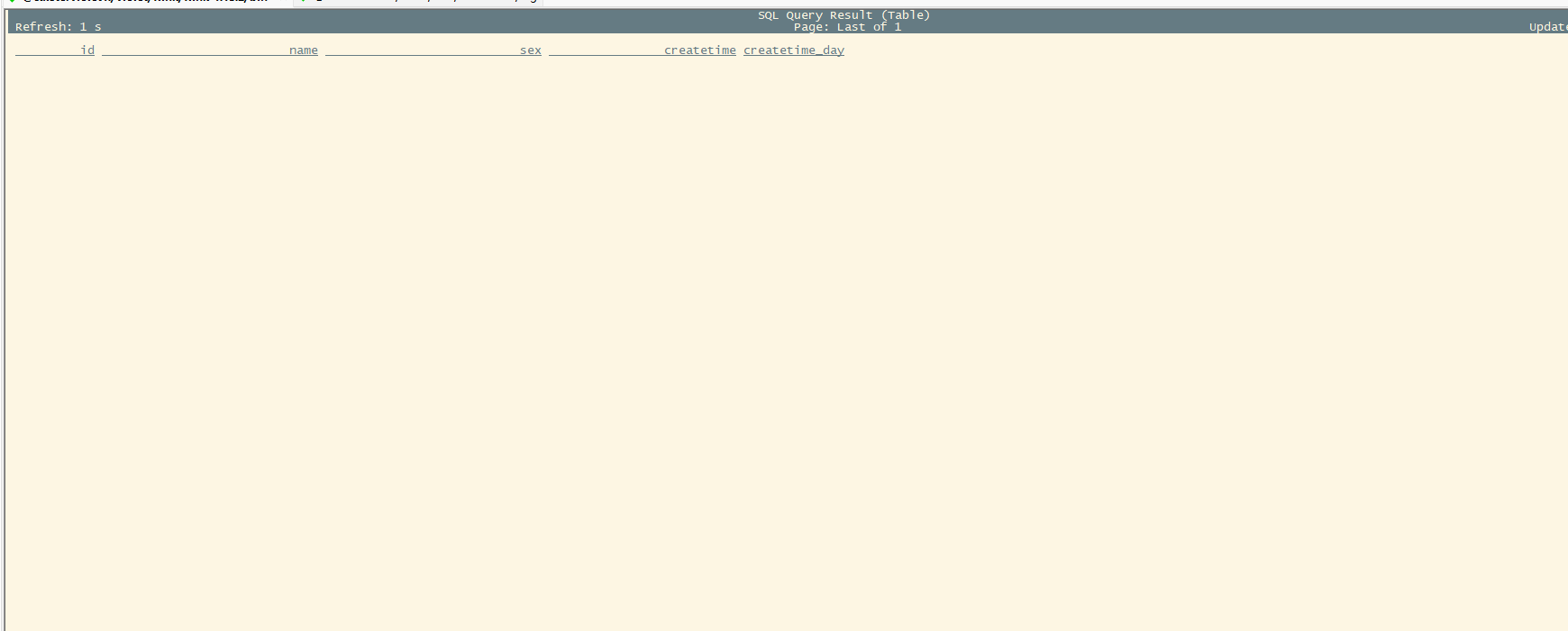
SET execution.runtime-mode = batch;
batch result:

batch is normal ,but streaming is not normal.
@zixiao144 stream read will discover new snapshots with data files appended. if you launch a Flink SQL job with streaming read, you would need to insert new rows to the table for the streaming SQL jobs to discover. By default, the streaming read starts from the latest snapshot. if there are no rows/snapshots appended to the table after the job started, there won't be new data to be read.
thanks @stevenzwu I use hadoop catelog . step1 stream read step2 appended data not work,no result.


Can you provide the log file for Flink jobmanager with DEBUG enabled for org.apache.iceberg.flink.source.StreamingMonitorFunction? Then we can check the periodical split discovery for the streaming execution.
For FLIP-27 source, SQL is not available in 0.14.1. Did you try it with build from master branch? If yes, we also need jobmanager log file (with INFO level) to investigate.
jobmanager_log.txt flink-root-taskexecutor-0-violet.log flink--sql-client-violet.log taskmanager_localhost_44203-b19935_log.txt
I use flink1.15.2 ,iceberg 0.14.1 Flink 1.15 runtime Jar
the jobmanager log doesn't contain any log lines from org.apache.iceberg. is the logging level set properly?
in flink-root-taskexecutor log lines from org.apache.iceberg .
2022-09-27 00:19:28,670 DEBUG org.apache.flink.streaming.runtime.tasks.StreamTask [] - Legacy source Source: Iceberg table (iotCatalog.iotdw.test) monitor (1/1)#0 (d77ec0c3c3c1493cb4a6a506b8648be3) skip execution since the task is finished on restore DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 11883ms
 I opened debug
I opened debug
2022-09-27 08:19:21,864 INFO org.apache.flink.api.java.typeutils.TypeExtractor [] - class org.apache.iceberg.flink.source.FlinkInputSplit does not contain a getter for field task 2022-09-27 08:19:21,864 INFO org.apache.flink.api.java.typeutils.TypeExtractor [] - class org.apache.iceberg.flink.source.FlinkInputSplit does not contain a setter for field task 2022-09-27 08:19:21,864 INFO org.apache.flink.api.java.typeutils.TypeExtractor [] - Class class org.apache.iceberg.flink.source.FlinkInputSplit cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance.
Is it working well in flink 1.15.0 instead of 1.15.2? The default flink version for iceberg 0.14.0 is 1.15.0. And I have another wired issue with 1.14.3 in iceberg 0.13.2. The small version fix might cause a problem. Can some developer answer the question?
@zixiao144 yes, saw the logs in taskmanager log file. Sorry, I forgot the the StreamingMonitorFunction runs on taskmanagers. Flink streaming read only discovers append snapshot. How did you append data to the table? it seems that Flink source see the snapshots but didn't find any splits from snapshots with append operation.
Can you run java API to check the snapshot history and the operation type of the Snapshot? Alternatively, you can run Spark SQL to query the metadata table: https://iceberg.apache.org/docs/latest/spark-queries/#snapshots.
2022-09-27 00:19:28,682 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Start discovering splits from -1 (exclusive) to 6496244702617183271 (inclusive)
2022-09-27 00:19:40,565 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 11883ms
2022-09-27 00:19:40,566 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Forwarded 0 splits, time elapsed 1ms
2022-09-27 00:19:57,703 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Start discovering splits from 6496244702617183271 (exclusive) to 2877339576078753525 (inclusive)
2022-09-27 00:19:57,704 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 1ms
2022-09-27 00:19:57,705 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Forwarded 0 splits, time elapsed 0ms
2022-09-27 00:20:02,759 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Start discovering splits from 2877339576078753525 (exclusive) to 9205452674806088860 (inclusive)
2022-09-27 00:20:02,759 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 0ms
2022-09-27 00:20:02,759 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Forwarded 0 splits, time elapsed 0ms
2022-09-27 00:20:52,053 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Start discovering splits from 9205452674806088860 (exclusive) to 85589348609116719 (inclusive)
2022-09-27 00:20:52,070 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 17ms
2022-09-27 00:20:52,070 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Forwarded 0 splits, time elapsed 0ms
2022-09-27 00:21:42,325 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Start discovering splits from 85589348609116719 (exclusive) to 519180963154444509 (inclusive)
2022-09-27 00:21:42,345 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 20ms
2022-09-27 00:21:42,345 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Forwarded 0 splits, time elapsed 0ms
2022-09-27 00:22:32,575 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Start discovering splits from 519180963154444509 (exclusive) to 2413530983076443232 (inclusive)
2022-09-27 00:22:32,595 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 20ms
2022-09-27 00:22:32,595 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Forwarded 0 splits, time elapsed 0ms
2022-09-27 00:23:21,804 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Start discovering splits from 2413530983076443232 (exclusive) to 5161337709432232128 (inclusive)
2022-09-27 00:23:21,819 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Discovered 0 splits, time elapsed 15ms
2022-09-27 00:23:21,819 DEBUG org.apache.iceberg.flink.source.StreamingMonitorFunction [] - Forwarded 0 splits, time elapsed 0ms
I use flink cdc to iceberg ,I test it .before insert, snapshots is 19.
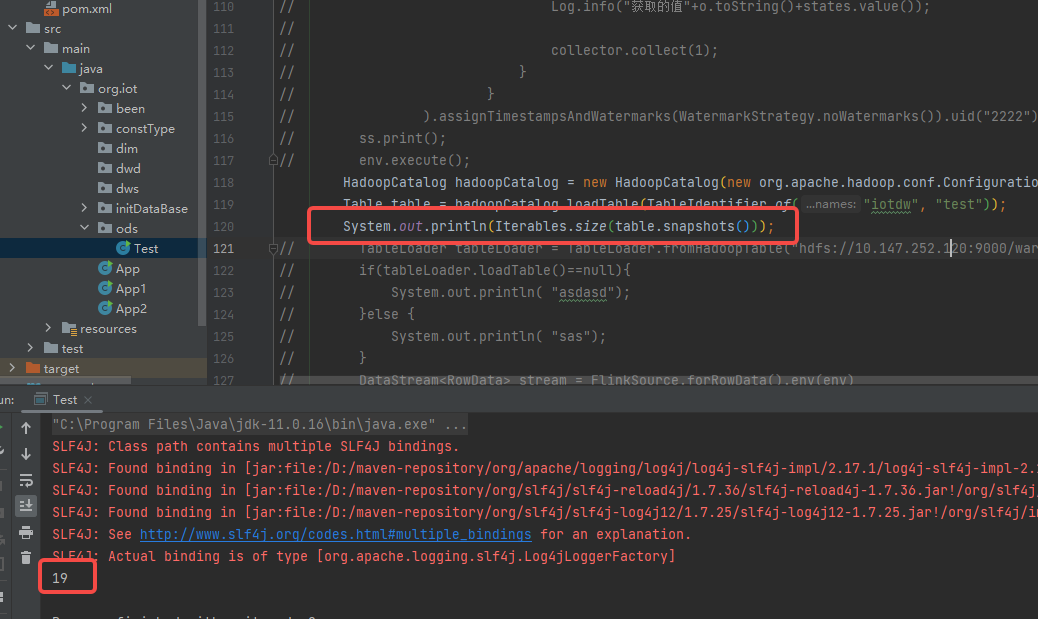 and I insert one row ,it is 19.
and I insert one row ,it is 19.
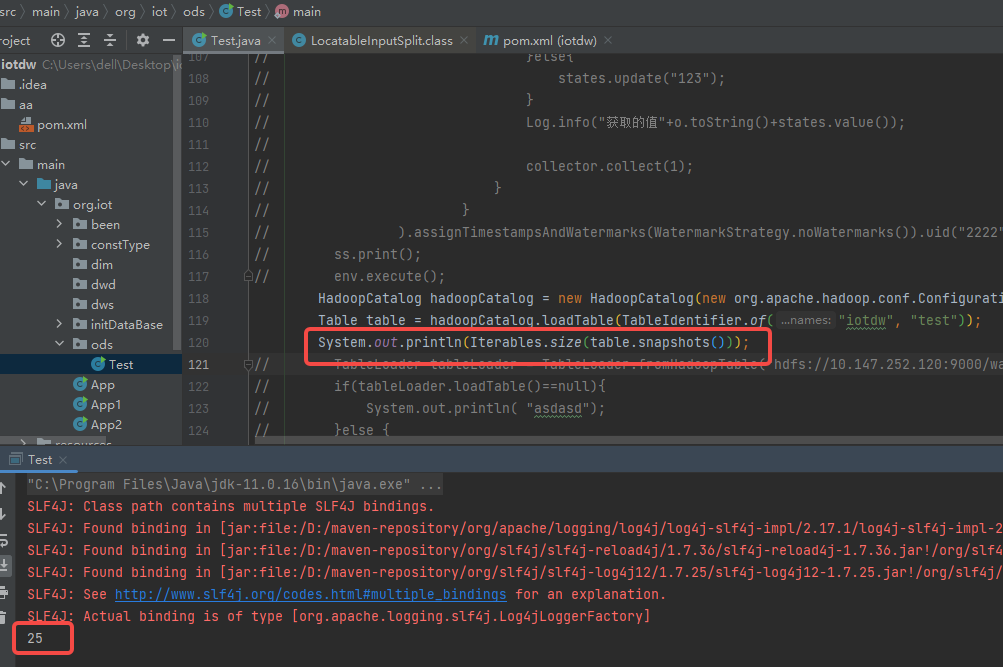
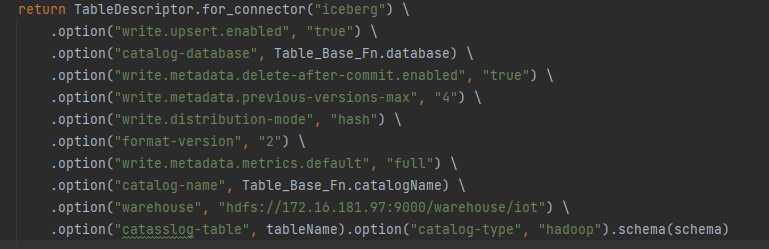 create table by the way
create table by the way
Ah. You are doing CDC write to Iceberg. For the streaming read out of Iceberg CDC table, you want to read rows out with proper row type (like insert, delete, etc.). Then this is expected as the current Flink streaming read doesn't support upsert/row-level deletes.
Anton has been working on supporting CDC reads from Iceberg core and Spark. iceberg-flink can leverage the new APIs in Iceberg-api/core. don't think there is anyone picking it up from Flink side yet.
thanks. cdc doesn't supprot upsert.I disable iceberg's option . it can work.
This issue has been automatically marked as stale because it has been open for 180 days with no activity. It will be closed in next 14 days if no further activity occurs. To permanently prevent this issue from being considered stale, add the label 'not-stale', but commenting on the issue is preferred when possible.
This issue has been closed because it has not received any activity in the last 14 days since being marked as 'stale'