DecoderResolver may lead to OOM of flink jobs writing to iceberg tables
Apache Iceberg version
0.13.1
Query engine
Flink
Please describe the bug 🐞
I have a flink job writing to iceberg tables. When the job runs for several days, an OOM occurs. The reason is described below:
The DecoderResolver holds a ThreadLocal variable of a two-layer map:
private static final ThreadLocal<Map<Schema, Map<Schema, ResolvingDecoder>>> DECODER_CACHES = ThreadLocal.withInitial(() -> {
return (new MapMaker()).weakKeys().makeMap();
});
private static ResolvingDecoder resolve(Decoder decoder, Schema readSchema, Schema fileSchema) throws IOException {
Map<Schema, Map<Schema, ResolvingDecoder>> cache = (Map)DECODER_CACHES.get();
Map<Schema, ResolvingDecoder> fileSchemaToResolver = (Map)cache.computeIfAbsent(readSchema, (k) -> {
return Maps.newHashMap();
});
...
}
The outer map has a weak key while the inner map has a strong one. As the inner map holds a reference to a Schema object, the outer map holding the same weak reference to the Schema object will not release the weak key. That leads to the OOM.
What I suggest is to change the inner map to one with weak key, too:
Map<Schema, ResolvingDecoder> fileSchemaToResolver = (Map)cache.computeIfAbsent(readSchema, (k) -> {
// return Maps.newHashMap();
return new WeakHashMap<>();
});
So far it seems working with my jobs.
@ldwnt while your analysis on the inner map makes sense to me, I have a couple of questions.
- shouldn't
DecoderResolveronly be used by reader (not writer)? - I assume you confirmed the memory issue from a heap dump?
@stevenzwu
- shouldn't
DecoderResolveronly be used by reader (not writer)?
I'm not familiar with Iceberg source code, but are meta files (manifest list/manifest) read during writing and that involves DecoderResolver?
- I assume you confirmed the memory issue from a heap dump?
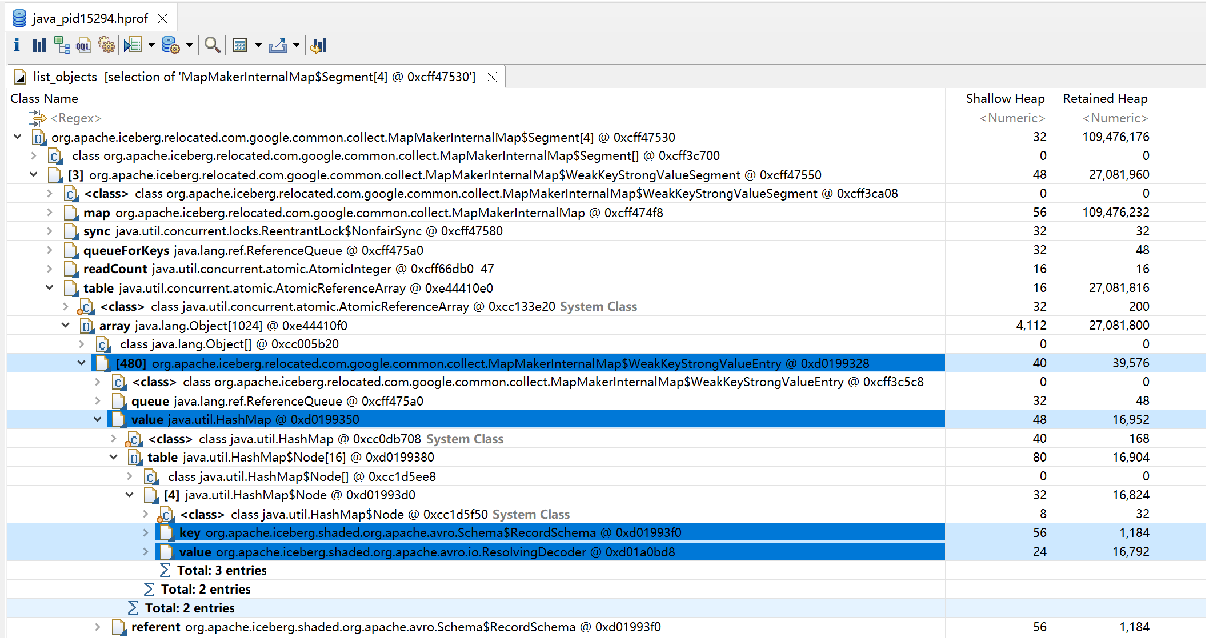
Yes, please refer to the snapshot below:
@ldwnt can you create a PR for the weak reference fix?
Regarding the OOM, does your use case have many different read schemas and file schemas?
@ldwnt can you create a PR for the weak reference fix?
Sure, I'll cerate one.
Regarding the OOM, does your use case have many different read schemas and file schemas?
I have a job writing to around 100 iceberg tables. The table schema barely changes, but snapshots and manifests are continuously generated due to incoming data.
Checking your heap dump. The whole map has retained memory of 109 MB, which doesn't seem too much? is that the main cause of the OOM?
Avro Schema implements equals and hashCode. If there is no frequent schema change, the size of the DecoderResolver cache should remain stable. there is no memory leak. Now I think I understand why the file schema is not weak reference. Otherwise, we would invalidate the cached resolver on the file schema and create a new resolver for every data file. So it seems that the current behavior is the right behavior.
I have a job writing to around 100 iceberg tables. The table schema barely changes, but snapshots and manifests are continuously generated due to incoming data.
We also have a similar setup internally. We didn't run into OOM issue. Not sure what's the difference here.
Did you run all 100 tables and writer threads in a single JVM? how big is the JVM heap size?
This issue has been automatically marked as stale because it has been open for 180 days with no activity. It will be closed in next 14 days if no further activity occurs. To permanently prevent this issue from being considered stale, add the label 'not-stale', but commenting on the issue is preferred when possible.
Our flink app that commits every minute had caused OOM after a month. This may be because each commit generates a avro reader/writer to read/write the manifest.
With the current implementation, when readSchema and fileSchema are the same reference (this can happen), the weak map entry is not released even if the reference holder disappears. This is because the reference continues to exist as a key for the inner map.
So the fileSchema used as the key needs to be a cloned one.
We have met a similar problem and I have submitted a PR for this. @stevenzwu Could you help to review it?