hudi
 hudi copied to clipboard
hudi copied to clipboard
[HUDI-4586] Improve metadata fetching in bloom index
Change Logs
When enabling column stats and bloom filter reading from metadata table for Bloom index (hoodie.bloom.index.use.metadata=true), frequent S3 timeouts like below happen and cause the write job to retry a lot or fail:
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading logblock from log file HoodieLogFile{pathStr='s3a://<>/.hoodie/metadata/column_stats/.col-stats-0000_00000000000000.log.4_5-116-20141', fileLen=-1}
at org.apache.hudi.common.table.log.HoodieLogFileReader.next(HoodieLogFileReader.java:389)
at org.apache.hudi.common.table.log.HoodieLogFormatReader.next(HoodieLogFormatReader.java:123)
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.scanInternal(AbstractHoodieLogRecordReader.java:229)
... 38 more
Caused by: org.apache.hadoop.fs.s3a.AWSClientIOException: re-open s3a://<>/.hoodie/metadata/column_stats/.col-stats-0000_00000000000000.log.4_5-116-20141 at 475916 on s3a://<>/.hoodie/metadata/column_stats/.col-stats-0000_00000000000000.log.4_5-116-20141: com.amazonaws.SdkClientException: Unable to execute HTTP request: The target server failed to respond: Unable to execute HTTP request: The target server failed to respond
at org.apache.hadoop.fs.s3a.S3AUtils.translateException(S3AUtils.java:208)
at org.apache.hadoop.fs.s3a.Invoker.once(Invoker.java:117)
at org.apache.hadoop.fs.s3a.S3AInputStream.reopen(S3AInputStream.java:226)
at org.apache.hadoop.fs.s3a.S3AInputStream.lambda$lazySeek$1(S3AInputStream.java:392)
at org.apache.hadoop.fs.s3a.Invoker.lambda$maybeRetry$3(Invoker.java:228)
at org.apache.hadoop.fs.s3a.Invoker.once(Invoker.java:115)
at org.apache.hadoop.fs.s3a.Invoker.maybeRetry(Invoker.java:354)
at org.apache.hadoop.fs.s3a.Invoker.maybeRetry(Invoker.java:226)
at org.apache.hadoop.fs.s3a.Invoker.maybeRetry(Invoker.java:270)
at org.apache.hadoop.fs.s3a.S3AInputStream.lazySeek(S3AInputStream.java:384)
at org.apache.hadoop.fs.s3a.S3AInputStream.read(S3AInputStream.java:418)
at java.io.FilterInputStream.read(FilterInputStream.java:83)
at java.io.DataInputStream.readInt(DataInputStream.java:387)
at org.apache.hudi.common.table.log.block.HoodieLogBlock.getLogMetadata(HoodieLogBlock.java:228)
at org.apache.hudi.common.table.log.HoodieLogFileReader.readBlock(HoodieLogFileReader.java:193)
at org.apache.hudi.common.table.log.HoodieLogFileReader.next(HoodieLogFileReader.java:387)
... 40 more
Relevant Spark stages are (1) fetching column stats from the metadata table (Stage 86 below) (2) fetching bloom filters from metadata table and do record key lookup (Stage 141 below)
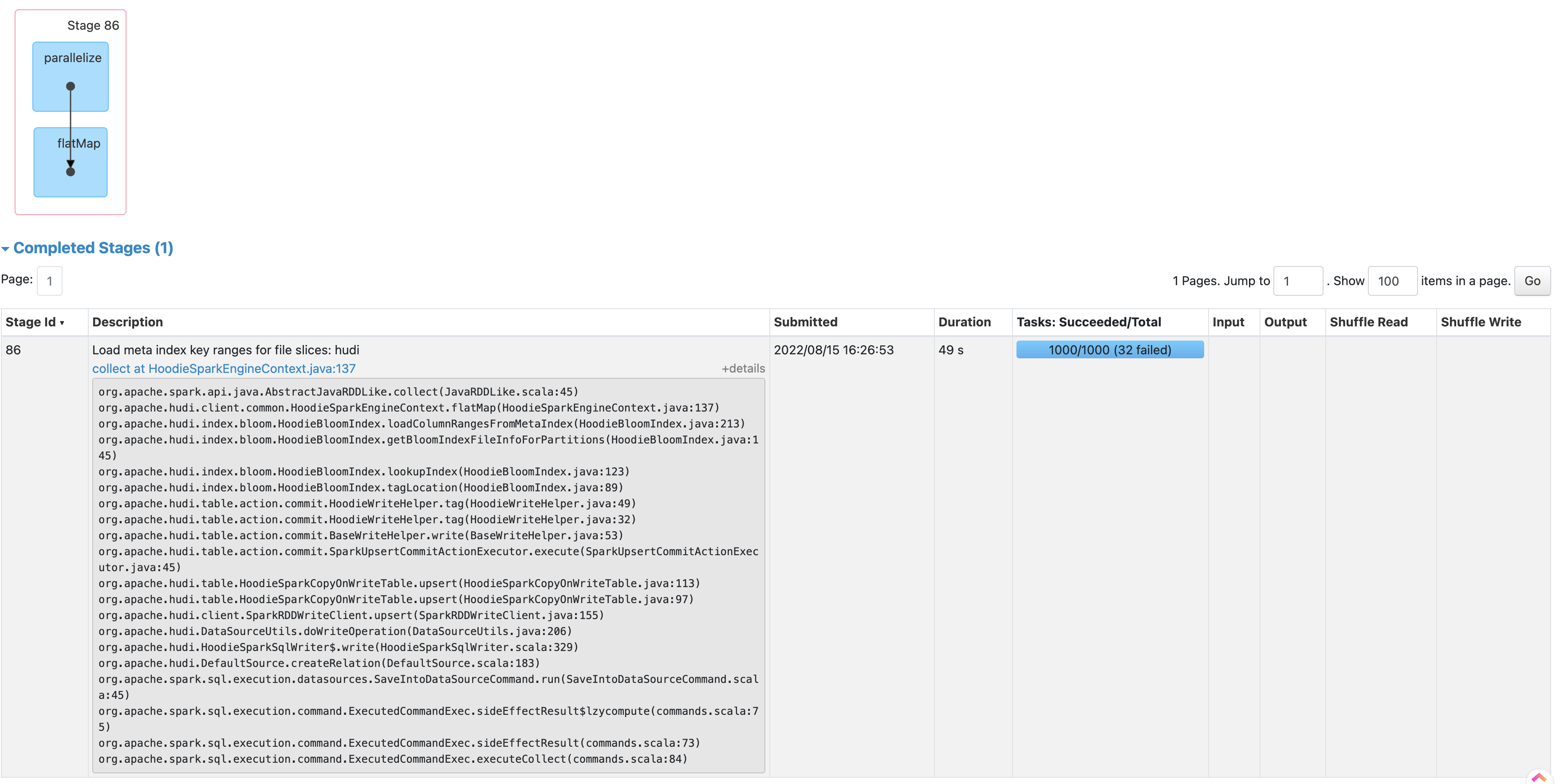
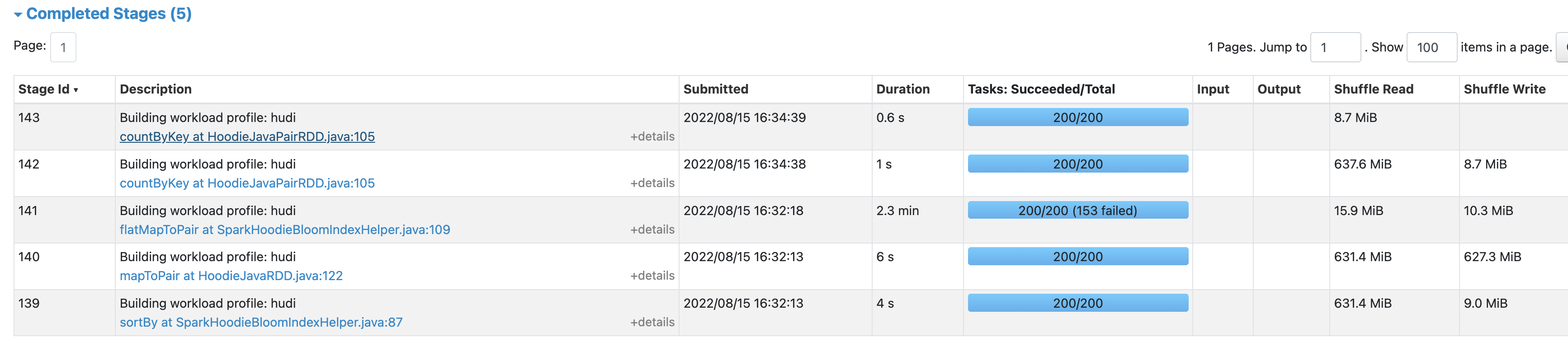
The root cause is that, the parallelism to fetch column stats and bloom filters is too high, causing too much concurrency reading metadata table from each executor, where HFiles and log files are scanned.
To address this problem, this PR adjusts the Bloom Index DAG to limit the parallelism to fetch column stats and bloom filters from the metadata table. Specifically,
- Adds a new write config
hoodie.bloom.index.metadata.read.parallelism(default10) to control the parallelism for reading the index from metadata table. This affects the fetching of both column stats and bloom filters.- Limits the parallelism of column stats fetching inside
HoodieBloomIndex::loadColumnRangesFromMetaIndex() - Limits the parallelism of bloom filter fetching inside
SparkHoodieBloomIndexHelper::findMatchingFilesForRecordKeys()
- Limits the parallelism of column stats fetching inside
- Rewrites
HoodieMetadataBloomIndexCheckFunctionto support batch processing of bloom filter fetching- Adds a new write config
hoodie.bloom.index.metadata.bloom.filter.read.batch.size(default128) to determine the batch size for reading bloom filters from metadata table. Smaller value puts less pressure on the executor memory.
- Adds a new write config
- Before the lookup of <file ID, and record key> pairs, sorts the list of pairs based on the bloom filter key entry in the metadata table, instead of file ID alone (which does not provide value). In this way, bloom filter keys are nicely laid out in sequential lookup.
- To support this, we need to have the file name (required for generating the hash key) stored alongside the file ID, by adding a new member in
BloomIndexFileInfo. To support efficient lookup of file name based on the file ID, the data structure of a few intermediate results are changed.
- To support this, we need to have the file name (required for generating the hash key) stored alongside the file ID, by adding a new member in
Impact
Risk level: high The changes are tested and benchmarked through upserts to Hudi tables on S3, using both 1GB and 100GB batches.
Below shows the Spark stages of fetching column stats and bloom filters after the fix. Timeouts are no longer present. The index fetching is much faster (column stats: 1min+ -> 7s, 2min+ -> 1min).


Based on the benchmarking, when enabling metadata table reading for column stats and bloom filters in Bloom index, the overall upsert latency is reduced by 1-3 min (10%+) after the fix.
Contributor's checklist
- [ ] Read through contributor's guide
- [ ] Change Logs and Impact were stated clearly
- [ ] Adequate tests were added if applicable
- [ ] CI passed
CI report:
- ed15f57dc58b2e9142dd33a0ecd078bf4c236afc Azure: FAILURE
Bot commands
@hudi-bot supports the following commands:@hudi-bot run azurere-run the last Azure build
Following up on my previous comment: taking a deeper look i see following issues in our code at the moment
- Creating
HoodieTableBackedMetadatainstance w/inHoodieTablewe don't specify that it should reuse MT readers. HoodieMetadataMergedLogRecordReader.getRecordsByKeysalways clears previously computedrecordsand always scans from scratch while instead we should NOT be re-processing records that have already been processed, and instead just incrementally process missing ones.