[SUPPORT] Hudi creates duplicate, redundant file during clustering
Summary During clustering, Hudi creates duplicate parquet file with the same file group ID and identical content. One of the two files are later marked as a duplicate and deleted. I'm using inline clustering with a single writer, so there's no concurrency issues at play.
Details


The two spark jobs above are triggered during inline clustering.


As can be seen above, both of these Spark jobs trigger MultipleSparkJobExecutionStrategy.performClustering method. This ends up creating and storing two identical clustered files.
When HoodieTable.reconcileAgainstMarkers runs, the newer file is identified as a duplicate, and is deleted.
Expected behavior
Hudi should only store the clustered file once. Storing a duplicate of the file unnecessarily increases the duration.
Environment Description
-
Hudi version : 0.11.0
-
Spark version : 3.1.2
-
Storage (HDFS/S3/GCS..) : S3
-
Running on Docker? (yes/no) : No
Additional context
I'm using Copy on Write and inline clustering. My write config is:
.write
.format(HUDI_WRITE_FORMAT)
.option(TBL_NAME.key(), tableName)
.option(TABLE_TYPE.key(), COW_TABLE_TYPE_OPT_VAL)
.option(PARTITIONPATH_FIELD.key(), ...)
.option(PRECOMBINE_FIELD.key(), ...)
.option(COMBINE_BEFORE_INSERT.key(), "true")
.option(KEYGENERATOR_CLASS_NAME.key(), CUSTOM_KEY_GENERATOR)
.option(URL_ENCODE_PARTITIONING.key(), "true")
.option(HIVE_SYNC_ENABLED.key(), "true")
.option(HIVE_DATABASE.key(), ...)
.option(HIVE_PARTITION_FIELDS.key(), ...)
.option(HIVE_TABLE.key(), tableName)
.option(HIVE_TABLE_PROPERTIES.key(), tableName)
.option(HIVE_PARTITION_EXTRACTOR_CLASS.key(), MULTI_PART_KEYS_VALUE_EXTRACTOR)
.option(HIVE_USE_JDBC.key(), "false")
.option(HIVE_SUPPORT_TIMESTAMP_TYPE.key(), "true")
.option(HIVE_STYLE_PARTITIONING.key(), "true")
.option(KeyGeneratorOptions.Config.TIMESTAMP_TYPE_FIELD_PROP, INPUT_TIMESTAMP_TYPE)
.option(KeyGeneratorOptions.Config.INPUT_TIME_UNIT, INPUT_TIMESTAMP_UNIT)
.option(KeyGeneratorOptions.Config.TIMESTAMP_OUTPUT_DATE_FORMAT_PROP, OUTPUT_TIMESTAMP_FORMAT)
.option(OPERATION.key(), UPSERT_OPERATION_OPT_VAL)
.option(INLINE_CLUSTERING.key(), "true")
.option(INLINE_CLUSTERING_MAX_COMMITS.key(), "2")
.option(PLAN_STRATEGY_SMALL_FILE_LIMIT.key(), "73400320") // 70MB
.option(PLAN_STRATEGY_TARGET_FILE_MAX_BYTES.key(), "209715200") // 200MB
.option(COPY_ON_WRITE_RECORD_SIZE_ESTIMATE.key(), ...)
.option(PARQUET_MAX_FILE_SIZE.key(), "104857600") // 100MB
.option(PARQUET_SMALL_FILE_LIMIT.key(), "104857600") // 100MB
.option(PARALLELISM_VALUE.key(), getParallelism().toString)
.option(FILE_LISTING_PARALLELISM_VALUE.key(), getParallelism().toString)
.option(FINALIZE_WRITE_PARALLELISM_VALUE.key(), getParallelism().toString)
.option(DELETE_PARALLELISM_VALUE.key(), getParallelism().toString)
.option(INSERT_PARALLELISM_VALUE.key(), getParallelism().toString)
.option(ROLLBACK_PARALLELISM_VALUE.key(), getParallelism().toString)
.option(UPSERT_PARALLELISM_VALUE.key(), getParallelism().toString)
.option(INDEX_TYPE.key(), indexType)
.option(SIMPLE_INDEX_PARALLELISM.key(), getParallelism().toString)
.option(AUTO_CLEAN.key(), "true")
.option(CLEANER_PARALLELISM_VALUE.key(), getParallelism().toString)
.option(CLEANER_COMMITS_RETAINED.key(), "10")
.option(PRESERVE_COMMIT_METADATA.key(), "true")
.option(HoodieMetadataConfig.ENABLE.key(), "true")
.option(META_SYNC_CONDITIONAL_SYNC.key(), "false")
.option(ROLLBACK_PENDING_CLUSTERING_ON_CONFLICT.key(), "true")
.option(UPDATES_STRATEGY.key(), "org.apache.hudi.client.clustering.update.strategy.SparkAllowUpdateStrategy")
.option(MARKERS_TYPE.key(), MarkerType.DIRECT.toString)
.mode(SaveMode.Append)
@xushiyan any updates on this? We seem to be impacted as well, observing the same behavior.
@HEPBO3AH It looks like the clustering DAG is triggered twice. This needs reproducing. Could you also provide the timeline under <base_path>/.hoodie?
Hi,
Here is the code sample to replicate it:
val spark = SparkSession
.builder()
.master("local[3]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.hadoop.fs.s3a.aws.credentials.provider", "com.amazonaws.auth.profile.ProfileCredentialsProvider")
.config("spark.eventLog.enabled", "true")
.config("spark.eventLog.dir", logPath)
.getOrCreate();
import spark.implicits._
val ids = 1 to 5000 grouped(1000) toSeq
for (idSection <- ids) {
val df = idSection.toDF("id")
df
.write
.format("org.apache.hudi")
.option(TBL_NAME.key(), tableName)
.option(TABLE_TYPE.key(), COW_TABLE_TYPE_OPT_VAL)
.option(RECORDKEY_FIELD.key(), "id")
.option(PARTITIONPATH_FIELD.key(), "")
.option(OPERATION.key(), INSERT_OPERATION_OPT_VAL)
.option(INLINE_CLUSTERING.key(), "true")
.option(INLINE_CLUSTERING_MAX_COMMITS.key(), "1")
.mode(SaveMode.Append)
.save(path)
}
What we see in .hoodie:
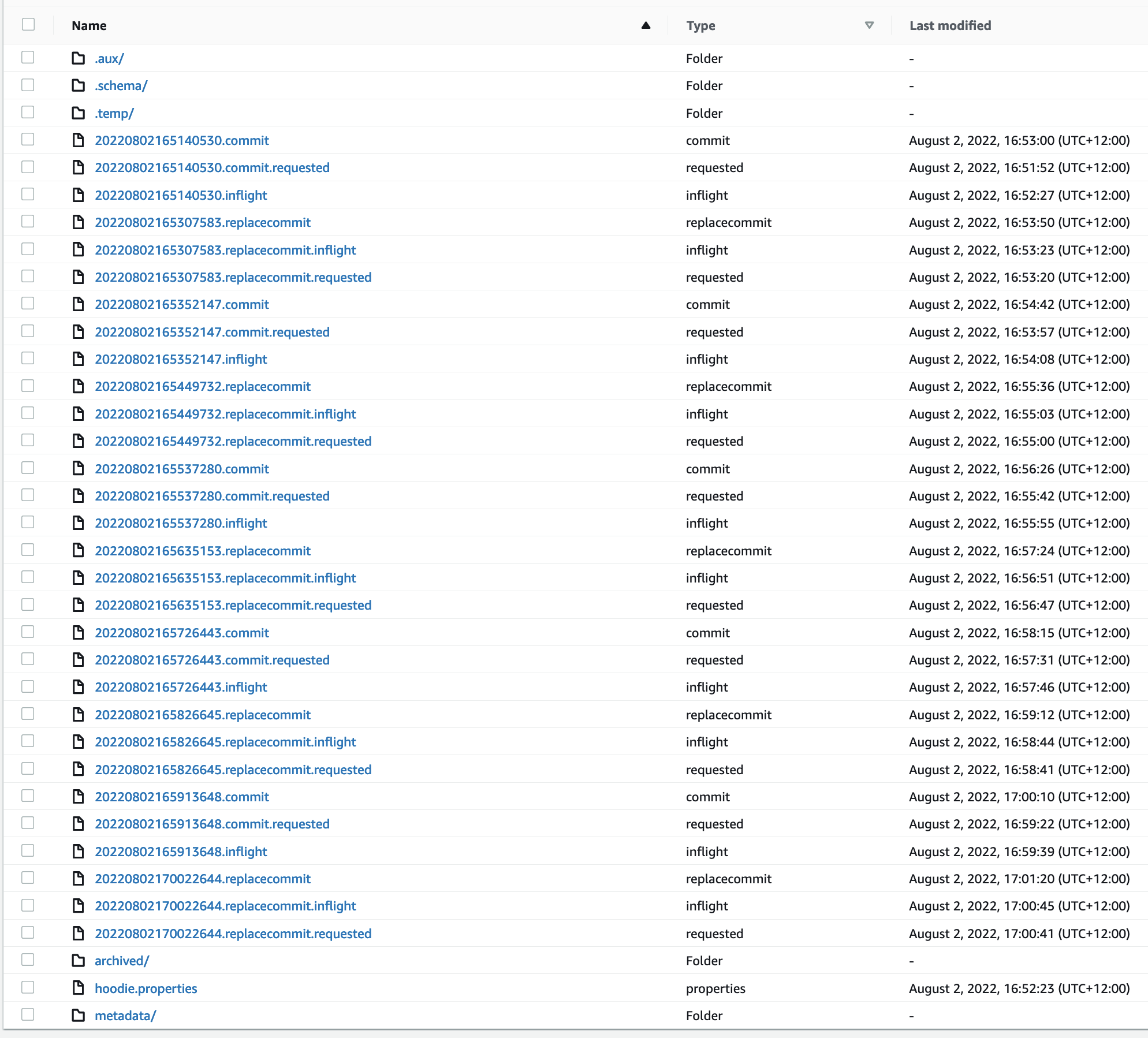
The files that were double created and then deleted. The delete markers correspond to the the clustering commit ids:
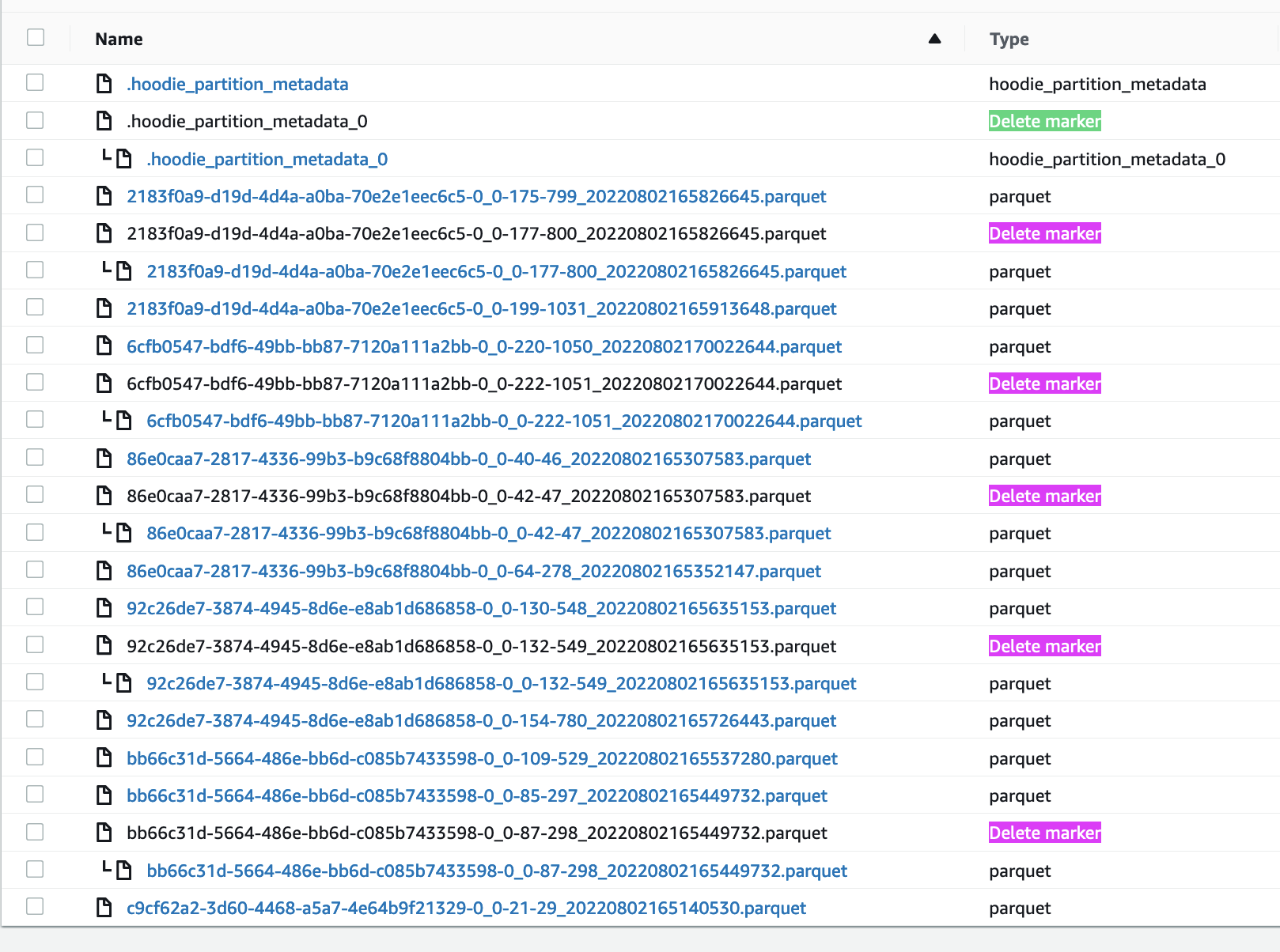
These have 1 to 1 relationship with clustering. If you set clustering to happen every 2 commits, only 2 delete markers will be present - one for each clustering as we do 5 passes in total in the code sample.
@HEPBO3AH : Can we try few things.
- increase the
INLINE_CLUSTERING_MAX_COMMITS.key()to say 3. and lets see if we encounter this issue. - can we add a delay of say 30 secs between successive commits in your for loop.
Let us know if the issue is still reproducible for above cases as well.
increase the INLINE_CLUSTERING_MAX_COMMITS.key() to say 3. and lets see if we encounter this issue.
It is still happening.
can we add a delay of say 30 secs between successive commits in your for loop.
Adding 30 seconds sleep between runs didn't solve the issue.
Gentle bump to see if anyone has any further recommendations on what information we could provide to help with reproducing the issue.
Hi @nsivabalan, sorry to be a hassle but do you have any updates on this one?
yes, I could able to reproduce :( https://issues.apache.org/jira/browse/HUDI-4760 will put up a fix shortly.
Here is the fix https://github.com/apache/hudi/pull/6561 Can you verify w/ the patch, you don't see such duplicates.
Did a quick test with your fix. I don't see any duplicates anymore during clustering! 👯