hudi
 hudi copied to clipboard
hudi copied to clipboard
[SUPPORT] Incremental and snapshot reads shows different results
Hudi version: 0.11.1 Spark version: 3.1.1 Storage: S3 AWS Glue: 3
Function
import org.apache.spark.sql.{functions => fn}
def readAndShow(path: String) {
val df = spark.read.format("hudi").load(path)
df.select(fn.min(fn.col("updated_at")), fn.min(fn.col("_hoodie_commit_time"))) show false
val idf = spark.read.format("hudi")
.option("hoodie.datasource.query.type", "incremental")
.option("hoodie.datasource.read.begin.instanttime", "0")
.option("hoodie.datasource.read.incr.fallback.fulltablescan.enable", "true")
.load(path)
idf.select(fn.min(fn.col("updated_at")), fn.min(fn.col("_hoodie_commit_time"))) show false
}
shows different results, but because hoodie.datasource.read.begin.instanttime is 0, the same ones should appear.
Examples of output
+-------------------+------------------------+
|min(updated_at) |min(_hoodie_commit_time)|
+-------------------+------------------------+
|2018-09-05 13:29:40|20220608041038459 |
+-------------------+------------------------+
+-----------------------+------------------------+
|min(updated_at) |min(_hoodie_commit_time)|
+-----------------------+------------------------+
|2022-07-06 12:02:04.736|20220706130300379 |
+-----------------------+------------------------+
+-------------------+------------------------+
|min(updated_at) |min(_hoodie_commit_time)|
+-------------------+------------------------+
|2019-08-28 08:47:12|20220606081029941 |
+-------------------+------------------------+
+-------------------+------------------------+
|min(updated_at) |min(_hoodie_commit_time)|
+-------------------+------------------------+
|2022-07-06 00:02:04|20220706010239483 |
+-------------------+------------------------+
These results are reproducible, but unfortunately I can't provide the dataset. I tried with and without hoodie.datasource.read.incr.fallback.fulltablescan.enable option, but the result is the same all the time. Could you please help me to read data with the incremental query from the beginning?
When I tried to replace 0 with commit time from the first request of function, I receive the same result.
It looks like the response is here: https://github.com/apache/hudi/issues/2841
So if I have a job that commits data 1 time per 15 minutes, to keep weekly data do I need to set the parameter hoodie.cleaner.commits.retained to 4 * 24 * 7?
no, Hudi always keeps the latest version of records in DFS.
It looks like the response is here: #2841
So if I have a job that commits data 1 time per 15 minutes, to keep weekly data do I need to set the parameter
hoodie.cleaner.commits.retainedto 4 * 24 * 7?
For the different result issue, could you upload the file under /.hoodie here? or just give a screenshot first is also ok
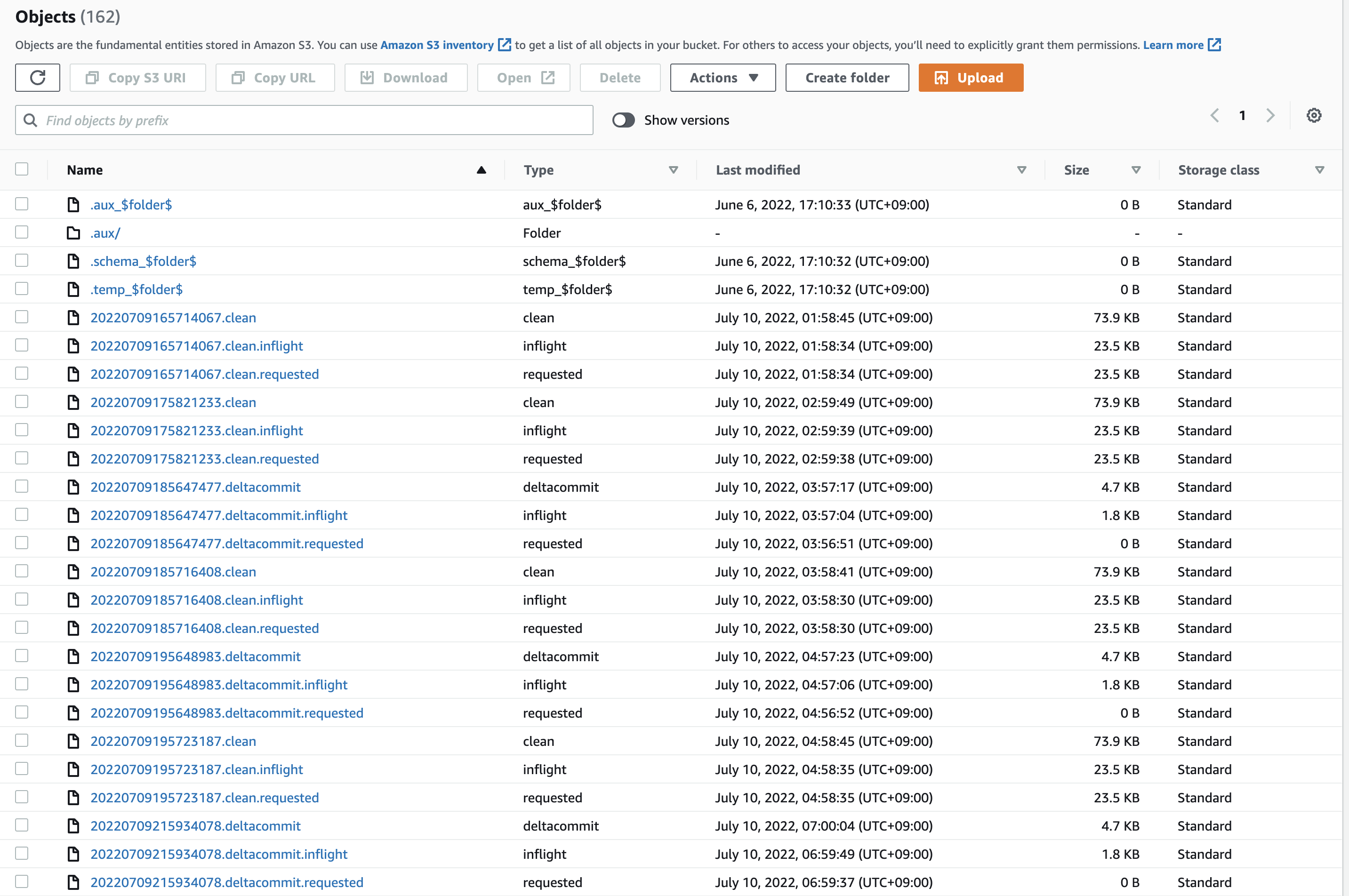
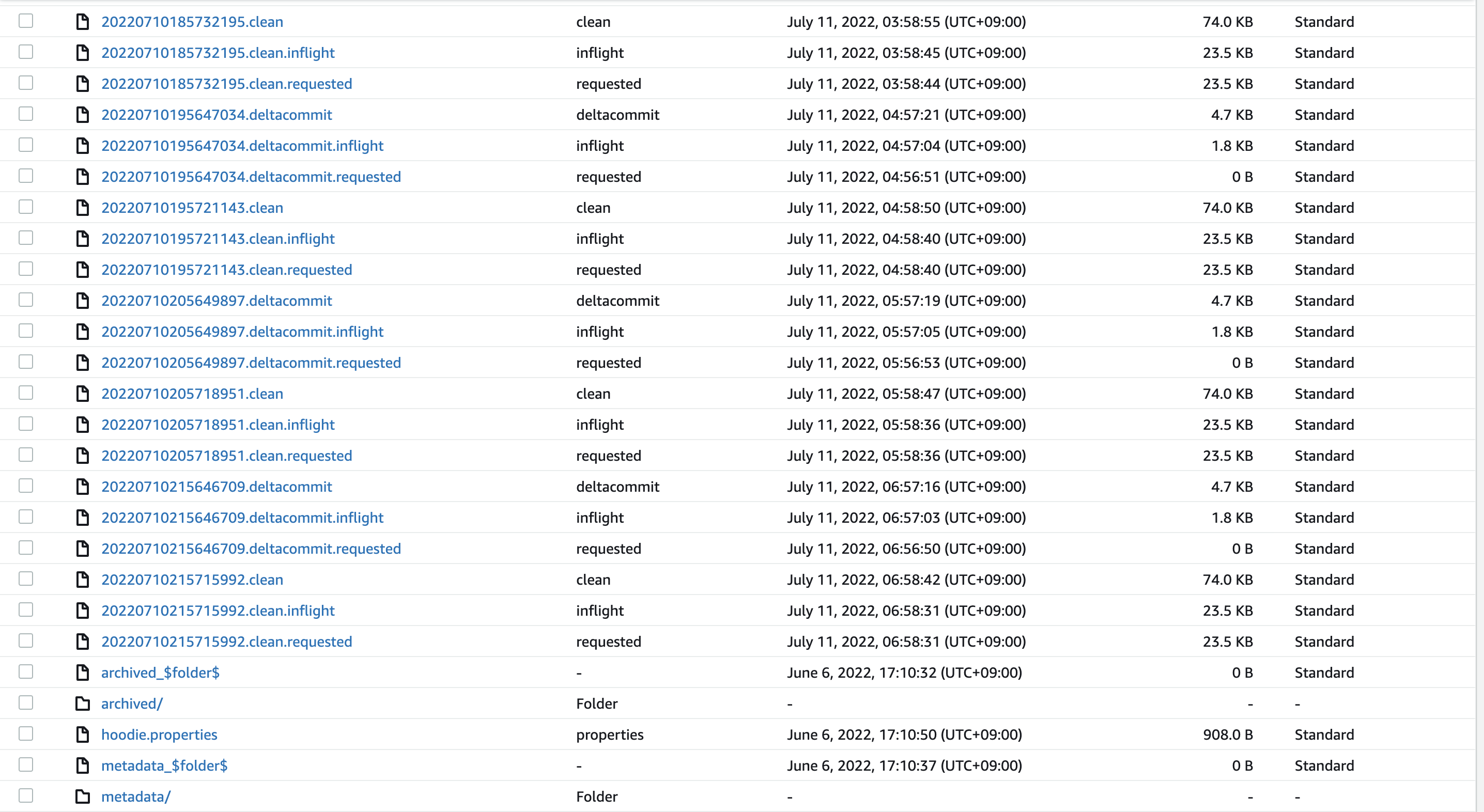
Current situation with incremental read: Case 1, previous commit time from the incremental reading was 20220706130300379
+-----------------------+------------------------+
|min(updated_at) |min(_hoodie_commit_time)|
+-----------------------+------------------------+
|2022-07-10 00:15:00.727|20220710011447293 |
+-----------------------+------------------------+
Case 2, previous commit time was 20220706010239483:
+-------------------+------------------------+
|min(updated_at) |min(_hoodie_commit_time)|
+-------------------+------------------------+
|2022-07-09 18:05:41|20220709185647477 |
+-------------------+------------------------+
It looks a cleaner process is involved here. We lost more records from the incremental read. Snapshot read have the same commit times (20220606082430597 and 20220608041038459 respectively).
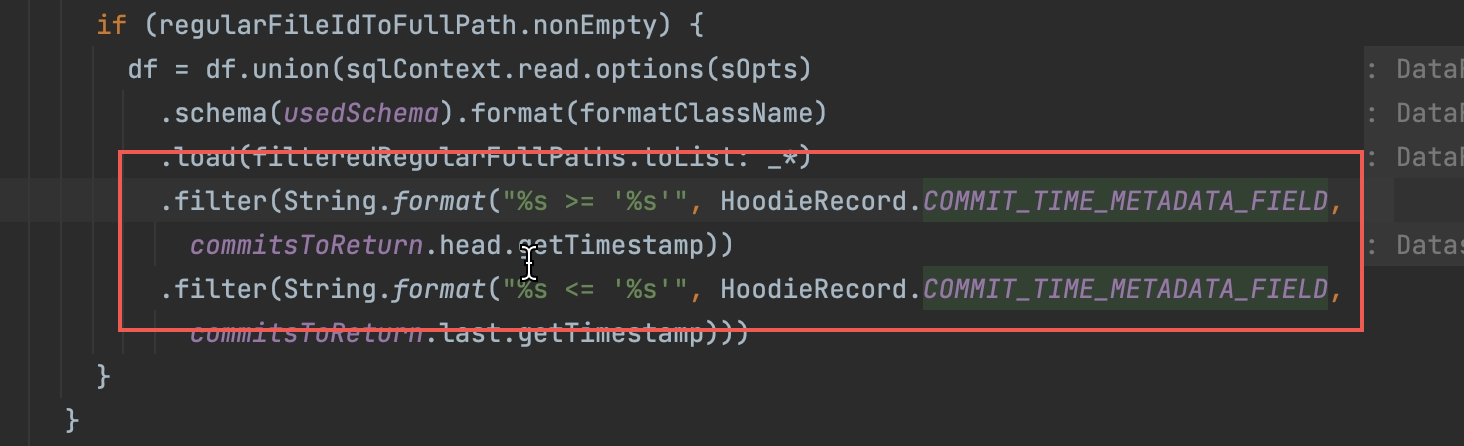 when using the incremental query, Hudi only will construct a timeline with commits that have not been cleand&achieved. and it will filter data out by the head commit. I can create a pr to fix this. but I'm not very sure whether this is a by-design behavior or not
when using the incremental query, Hudi only will construct a timeline with commits that have not been cleand&achieved. and it will filter data out by the head commit. I can create a pr to fix this. but I'm not very sure whether this is a by-design behavior or not
create a Jira ticket to track https://issues.apache.org/jira/browse/HUDI-4402
Let me try to explain how incremental query works.
Lets say, you have made 10 commits to hudi table. out of which first 5 are archived already. So, active timeline only has 5 commits i.e. C6 to C10.
When you do snapshot query now, you will be able to read all records ingested from C1 until C10. But when you trigger incremental query, it fetches records ingested with certain commit times. So, starting from C6, lets say you have set end commit to C7. what incremental query serves is, only those records which got ingested in C6 and C7. C6, bcoz thats the first commit in the active timeline.
Hope this gives you a picture of how incremental query works. not sure if we can do any fix around this. let me know if you have any further question.
@eshu : did you checkout my previous msg. does that makes sense. Feel free to close out the issue if you don't have further questions.
@nsivabalan If there is no way to read all records since a specified time, it makes no sense in incremental read at all. Is it possible to implement incremental readin for the whole dataset?
My goal was to get all changed records from a bookmark point. I have no idea, what the point in reading latest commited records...