brpc单个请求延时较高
Describe the bug (描述bug) 使用redis-benchmark -t set -c 1 -n 100000单链接无压力测试,对比redis server的20+us的单个请求延时,brpc redis server一般达到了40us+
To Reproduce (复现方法) redis-benchmark -t set -c 1 -n 100000
Expected behavior (期望行为) 较低的延时。
Versions (各种版本) OS: Compiler: brpc: protobuf:
Additional context/screenshots (更多上下文/截图) int Socket::StartInputEvent(SocketId id, uint32_t events, const bthread_attr_t& thread_attr) { SocketUniquePtr s; if (Address(id, &s) < 0) { return -1; } if (NULL == s->_on_edge_triggered_events) { // Callback can be NULL when receiving error epoll events // (Added into epoll by `WaitConnected') return 0; } if (s->fd() < 0) { #if defined(OS_LINUX) CHECK(!(events & EPOLLIN)) << "epoll_events=" << events; #elif defined(OS_MACOSX) CHECK((short)events != EVFILT_READ) << "kqueue filter=" << events; #endif return -1; }
// if (events & has_epollrdhup) {
// s->_eof = 1;
// }
// Passing e[i].events causes complex visibil2ity issues and
// requires stronger memory fences, since reading the fd returns
// error as well, we don't pass the events.
if (s->_nevent.fetch_add(1, butil::memory_order_acq_rel) == 0) {
// According to the stats, above fetch_add is very effective. In a
// server processing 1 million requests per second, this counter
// is just 1500~1700/s
g_vars->neventthread << 1;
bthread_t tid;
// transfer ownership as well, don't use s anymore!
Socket* const p = s.release();
bthread_attr_t attr = thread_attr;
attr.keytable_pool = p->_keytable_pool;
//如果此处注释了if, 不使用bthread 执行task,而是直接执行,则延时直接下降到20us if (bthread_start_urgent(&tid, &attr, ProcessEvent, p) != 0) { LOG(FATAL) << "Fail to start ProcessEvent"; ProcessEvent(p); } } return 0; }
可能我描述的不是很清楚,和多线程应该没有直接关系。其他的类redis数据库,比如DragonFly DB,延时也很低。 我对ProcessEvent加了bvar统计,如果ProcessEvent走bthread,则ProcessEvent函数的处理平均耗时为26us。如果不走,则ProcessEvent只有6us。单链接下最明显。
所以,我奇怪的是,ProcessEvent在redis协议下处理很简单,主要是系统调用read和write。而且ProcessEvent在bthread里调度时,自身并没有切线程,只是线程将函数调用栈从Socket::StartInputEvent切换到ProcessEvent函数,为何会影响系统调用read和write的开销呢?
Socket::StartInputEvent 里如果直接调用ProcessEvent函数,也是函数调用过程和栈切换,为何brpc jumpstack就能影响系统调用。是否和jumpstack的处理有关系?jumpstack是汇编代码,能力有限,看不大懂。
如果将进程用taskset绑定到固定的CPU上,也没有此差异。是不是brpc jumpstack的过程导致线程pthread切换了CPU,导致了cache miss,从而影响系统调用的开销。
bthread_start_urgent会把当前pthread的栈切到ProcessEvent函数,同时也会将当前bthread挂起并signal其它的worker来继续执行这个bthread,所以会对性能带来一定影响。并不是jumpstack带来的影响。
不不,我的重点不是当前bthread挂起并signal其它的worker来继续执行这个bthread带来的性能损耗,我的重点是经过bthread的ProcessEvent并没有切换pthread,为何系统调用函数write和read的开销高于直接调用ProcessEvent时的系统调用函数write和read的开销。
不不,我的重点不是当前bthread挂起并signal其它的worker来继续执行这个bthread带来的性能损耗,我的重点是经过bthread的ProcessEvent并没有切换pthread,为何系统调用函数write和read的开销高于直接调用ProcessEvent时的系统调用函数write和read的开销。
有关系的。当前bthread负责IO事件的处理,如果当前bthread挂起并signal其它的worker来继续执行,那么后续的read和write动作就会跑到其它的worker的,这就会影响到系统调用函数write和read的开销
它处理过程是这样的。Pthread A上运行bthreadA(epoll_wait),然后处理epoll事件,即ProcessEvent过程,其为bthread B,PthreadA会去执行bthread B,而将bthread A丢给队列,由其他pthread去继续执行。write和read是在ProcessEvent内部执行的,还在PthreadA上执行。
之前怀疑pthread 在bthread调度过程中切换了cpu,线程绑核后并没有效果。
之所以怀疑jump stack,因为jump stack各系统实现的汇编代码不同,而mac pro上ProcessEvent是否基于bthread没有任何区别。当然也有可能是CPU架构或操作系统不同的原因。 现在就是不清楚ProcessEvent走bthread影响系统调用的真实原因具体在哪里,从而无法进行优化。
还有一个原因可能是因为同1个socket的write调用一直在不同的线程里切换导致开销变高?因为看其他的网络框架,一般socket会绑到一个固定io线程处理。
write和read是在ProcessEvent内部执行的,还在PthreadA上执行。
这个请求是在pthread A 执行,下一个请求就到pthread B(接收了epoll bthread的那个pthread)执行了呀。每个请求都换pthread,这样效率就降低了
那感觉是不是还是像其他网络框架那样,io线程和socket是绑定的,只是rpc process那里用bthread去做负载均衡要好一点呢?这样也可以避免长尾请求的阻塞效应。
独立的io线程性能不一定会好,因为存在io线程和process线程之间同步的开销 你这里减小pthread worker的数量(最小是4),应该会好一些
独立的io线程性能不一定会好,因为存在io线程和process线程之间同步的开销 你这里减小pthread worker的数量(最小是4),应该会好一些
我测试了一下,确实worker少的时候,write的开销也较小。深层原因是什么呢?线程数越少?write落在同一个CPU核上的概率越高,cpu cache失效的概率越低,性能越好?对吗?
补充开销统计: 1个worker ProcessEvent:9us, Write:5us 2个worker ProcessEvent:12us, Write:7us 4个worker ProcessEvent:29us, Write:16us 8个worker ProcessEvent:28us, Write:16us 16个worker ProcessEvent:26us, Write:15us 24个worker ProcessEvent:29us, Write:16us 48个worker ProcessEvent:61us, Write:30us 不同worker下,处理的开销统计,非线性概率,呈现阶梯性概率曲线。
我测试了一下,确实worker少的时候,write的开销也较小。深层原因是什么呢?线程数越少?write落在同一个CPU核上的概率越高,cpu cache失效的概率越低,性能越好?对吗?
是的
@wwbmmm 你好,我这里同样是 redis-benchmark 对比 brpc 与 redis 的性能,观察到 redis 的 qps 能达到 9w,brpc-redis 只能达到 6w。brpc server 不是可以利用多线程的吗,为何会比不过 redis 呢?是因为 brpc-redis server 的实现是只有一个 bthread 在做 epoll_wait 吗?
@wwbmmm 你好,我这里同样是 redis-benchmark 对比 brpc 与 redis 的性能,观察到 redis 的 qps 能达到 9w,brpc-redis 只能达到 6w。brpc server 不是可以利用多线程的吗,为何会比不过 redis 呢?是因为 brpc-redis server 的实现是只有一个 bthread 在做 epoll_wait 吗?
你是单个连接下的benchmark吗?单个连接下按照redis协议的要求是需要串行处理的,这种情况下多线程并没有优势,你试试用多个连接并行压测看看
@wwbmmm 你好,我这里同样是 redis-benchmark 对比 brpc 与 redis 的性能,观察到 redis 的 qps 能达到 9w,brpc-redis 只能达到 6w。brpc server 不是可以利用多线程的吗,为何会比不过 redis 呢?是因为 brpc-redis server 的实现是只有一个 bthread 在做 epoll_wait 吗?
你是单个连接下的benchmark吗?单个连接下按照redis协议的要求是需要串行处理的,这种情况下多线程并没有优势,你试试用多个连接并行压测看看
是多个连接,ec2 上测的 qps 最高只有 6w 左右,增加连接数 qps 也上不去,只有 latency 上去了。。
是多个连接,ec2 上测的 qps 最高只有 6w 左右,增加连接数 qps 也上不去,只有 latency 上去了。。
可以看下bvar监控,bthread_worker_usage是否已经达到上限?process_cpu_usage和bthread_worker_usage的比值是多少? 另外brpc-redis server的处理逻辑是什么,是直接从内存里访问key进行响应,还是有其它逻辑?
是多个连接,ec2 上测的 qps 最高只有 6w 左右,增加连接数 qps 也上不去,只有 latency 上去了。。
可以看下bvar监控,bthread_worker_usage是否已经达到上限?process_cpu_usage和bthread_worker_usage的比值是多少? 另外brpc-redis server的处理逻辑是什么,是直接从内存里访问key进行响应,还是有其它逻辑?
好的我看一下。brpc redis server 里边没有任何逻辑,单纯的 no-op,使用的是 brpc 的 redis example,并且把 commandhandler 里的内存操作都注掉了,因为想测试的是 brpc 的性能上限。
@wwbmmm 你好,更新一下我这边的新发现。
首先是 redis_benchmark 是单线程的,之前的测试请求压力不够高,换成支持多线程的 memtier_benchmark 之后 brpc-redis 和 redis 的 qps 都有显著提升,brpc 的 redis example 的 qps 达到 10w 左右,而 redis 的 qps 能达到 17w。
跑的时候 brpc-redis 的 cpu 明显是没满的,猜测可能是 epoll 线程瓶颈,然后我把 event_dispatcher_num 设成 2 之后 qps 有明显上升,能达到 20w,而且 cpu 利用率高了很多,几乎能跑满 bthread_concurrency 对应的核数。并发设成 4 的情况下 bthread_worker_usage 稳定在 3.74,process_cpu_usage 最终稳定在 3.68 左右。
现在的问题增加并发无法带来 qps 提升,4 并发跟 9 并发的 qps 是几乎没有提升,19.9w 对比 20w,空有 cpu 消耗多了很多,9 并发下 bthread_worker_usage 稳定在 6.6,process_cpu_usage 最终稳定在 7.0 左右。请问这里不 scale 的可能原因是什么呢,因为 bthread 的调度不 scale?是否可能跟 brpc 针对 redis 协议单连接请求串行处理有关?
另外就是相同机器下使用自带的 rpc_press 压测 echo example 测出来 qps 最多能稳定在 22w多接近 23w,是否可以认为这是 brpc 的极限性能?brpc-redis 的 20w qps 是否还有提升空间呢?
4 并发跟 9 并发的 qps 是几乎没有提升,19.9w 对比 20w,空有 cpu 消耗多了很多
从4并发到9并发,是否有增加对应的event_dispatcher_num呢?
从4并发到9并发,是否有增加对应的event_dispatcher_num呢?
增加到3也没有提升,似乎到了瓶颈,增加线程数和 event_dispatcher_num 不会带来提升。
这点在另外一台64核的机器上更为明显。
ec2 server 机器类型是 c7g.16xlarge,同样的压力测试 memtier_benchmark -s 172.31.18.183 -d 256 –distinct-client-seed –expiry-range=500-500 -p 6379 -t 64 -c 30 -n 200000。
测 Dragonfly 的 qps 能达到 300w 并最终稳定在 200w 多一点,与宣称的基本一致;
测 brpc-redis 默认选项(64线程,1 event_dispatcher)下只能达到 70w,而且增加 event_dispatcher 反而会降低。线程越多反而越低,最佳的 qps 在 -bthread_concurrency=24 -event_dispatcher_num=4 选项下能达到 260w 并且很稳定,比 Dragonfly 还要高。并发超过 24 再增加的话就 latency 上升,qps 下降明显,无论 event_dispatcher_num 如何改变。而且 cpu 似乎全部花在了绿色 100%,
这是 brpc-redis 在最佳配置 -bthread_concurrency=24 -event_dispatcher_num=4 下的 cpu:
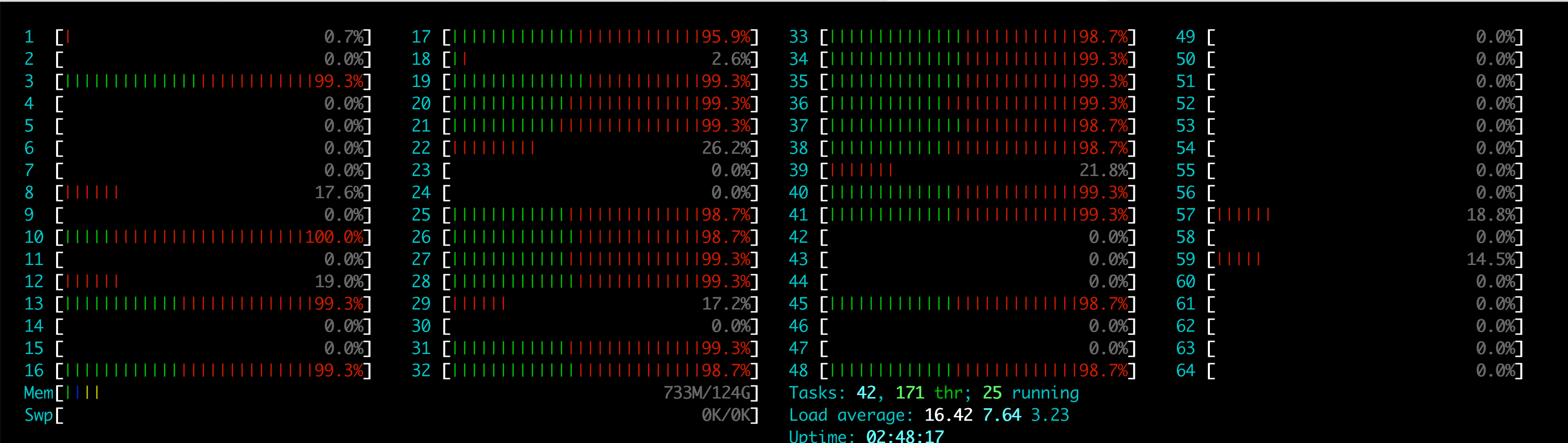 这是在配置
这是在配置 -bthread_concurrency=64 -event_dispatcher_num=4 下的 cpu:
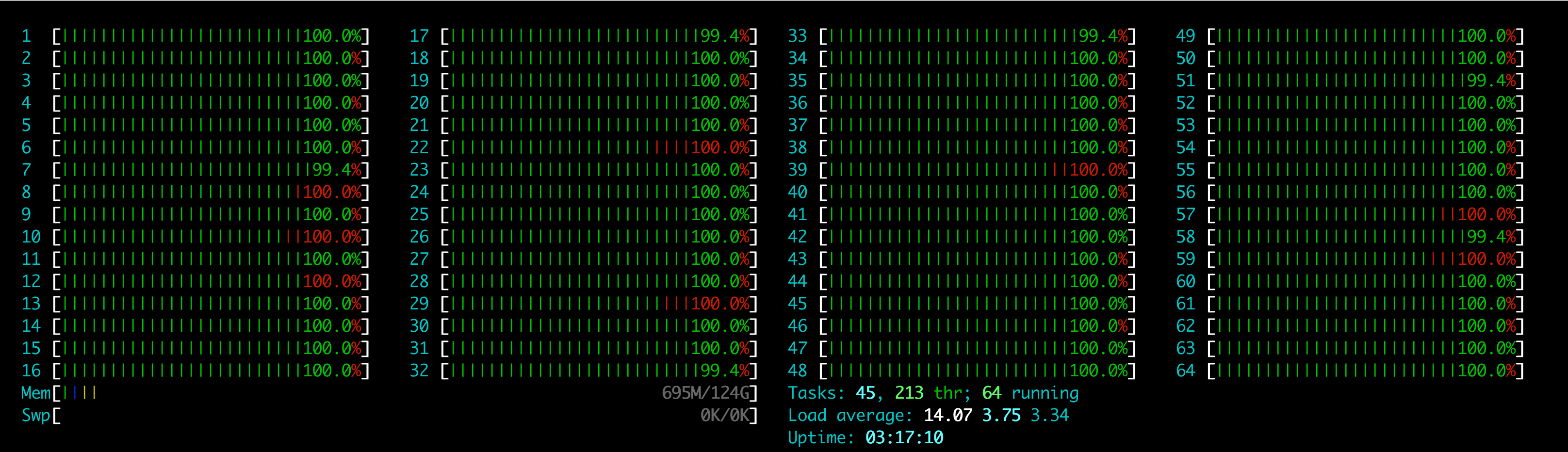
cpu 似乎全花在了调度跟空转和争抢上。
总结下就是超过一定阈值后增加并发数,latency 会上升,带来 qps 下降,似乎是调度带来的开销。现在看来每次部署都要专门调试选择最佳的配置。brpc 的潜力还是很大的,请问该怎么进一步分析,以及如何能让 cpu 能够真正地发挥呢?
cpu 似乎全花在了调度跟空转和争抢上。
总结下就是超过一定阈值后增加并发数,latency 会上升,带来 qps 下降,似乎是调度带来的开销。现在看来每次部署都要专门调试选择最佳的配置。brpc 的潜力还是很大的,请问该怎么进一步分析,以及如何能让 cpu 能够真正地发挥呢?
@MrGuin 可以试一下 #2819 。