ARROW-9773: [C++] Implement Take kernel for ChunkedArray
Benchmark runs are scheduled for baseline = e63a13aacbf67897202c8a56fccb3a86f624a96e and contender = a43fa07eda14d3f36a9dda593af03d5f1a26325d. Results will be available as each benchmark for each run completes.
Conbench compare runs links:
[Skipped :warning: Only ['Python'] langs are supported on ec2-t3-xlarge-us-east-2] ec2-t3-xlarge-us-east-2
[Failed :arrow_down:1.19% :arrow_up:1.02%] test-mac-arm
[Skipped :warning: Only ['JavaScript', 'Python', 'R'] langs are supported on ursa-i9-9960x] ursa-i9-9960x
[Finished :arrow_down:0.53% :arrow_up:1.49%] ursa-thinkcentre-m75q
Buildkite builds:
[Finished] a43fa07e test-mac-arm
[Finished] a43fa07e ursa-thinkcentre-m75q
[Finished] e63a13aa ec2-t3-xlarge-us-east-2
[Failed] e63a13aa test-mac-arm
[Failed] e63a13aa ursa-i9-9960x
[Finished] e63a13aa ursa-thinkcentre-m75q
Supported benchmarks:
ec2-t3-xlarge-us-east-2: Supported benchmark langs: Python, R. Runs only benchmarks with cloud = True
test-mac-arm: Supported benchmark langs: C++, Python, R
ursa-i9-9960x: Supported benchmark langs: Python, R, JavaScript
ursa-thinkcentre-m75q: Supported benchmark langs: C++, Java
I started by working on the Take implementation for primitive values, so I could familiarize myself with how the Take kernels work. But based on the benchmark I added, it seems like I actually made performance much worse (except in the monotonic case)! I suspect this is because having to use ChunkResolver for every index is more expensive than just copying the values into a contiguous array. Does that sounds reasonable? Or is there something obviously wrong?
Benchmark results
Baseline:
--------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
--------------------------------------------------------------------------------------------------------------
TakeChunkedInt64RandomIndicesNoNulls/4194304/1000 19362199 ns 19358250 ns 36 items_per_second=216.668M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/10 19504339 ns 19494278 ns 36 items_per_second=215.156M/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/2 34162071 ns 34146150 ns 20 items_per_second=122.834M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/1 10458465 ns 10455803 ns 66 items_per_second=401.146M/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/0 12260952 ns 12258093 ns 54 items_per_second=342.166M/s null_percent=0 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1000 19419778 ns 19412389 ns 36 items_per_second=216.063M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/10 29953237 ns 29944261 ns 23 items_per_second=140.07M/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/2 51350571 ns 51330500 ns 14 items_per_second=81.7117M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1 3319791 ns 3318972 ns 214 items_per_second=1.26374G/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/0 12277404 ns 12275145 ns 55 items_per_second=341.691M/s null_percent=0 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1000 24581060 ns 24574690 ns 29 items_per_second=170.676M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/10 22506711 ns 22501129 ns 31 items_per_second=186.404M/s null_percent=10 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/2 20736080 ns 20730853 ns 34 items_per_second=202.322M/s null_percent=50 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1 16202271 ns 16196349 ns 43 items_per_second=258.966M/s null_percent=100 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/0 15727504 ns 15721614 ns 44 items_per_second=266.786M/s null_percent=0 size=4.1943M
Proposed:
--------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
--------------------------------------------------------------------------------------------------------------
TakeChunkedInt64RandomIndicesNoNulls/4194304/1000 142831500 ns 142791200 ns 5 items_per_second=29.3737M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/10 144134633 ns 144110400 ns 5 items_per_second=29.1048M/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/2 125704833 ns 125667167 ns 6 items_per_second=33.3763M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/1 84408114 ns 84386875 ns 8 items_per_second=49.7033M/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/0 88094063 ns 88072375 ns 8 items_per_second=47.6234M/s null_percent=0 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1000 111903111 ns 111859500 ns 6 items_per_second=37.4962M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/10 113359923 ns 113286667 ns 6 items_per_second=37.0238M/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/2 95110995 ns 95098625 ns 8 items_per_second=44.1048M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1 1613900 ns 1613515 ns 437 items_per_second=2.59948G/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/0 88383021 ns 88365750 ns 8 items_per_second=47.4653M/s null_percent=0 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1000 23783853 ns 23776276 ns 29 items_per_second=176.407M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/10 24145126 ns 24140310 ns 29 items_per_second=173.747M/s null_percent=10 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/2 23058231 ns 23046233 ns 30 items_per_second=181.995M/s null_percent=50 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1 16306472 ns 16301465 ns 43 items_per_second=257.296M/s null_percent=100 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/0 15400245 ns 15398652 ns 46 items_per_second=272.381M/s null_percent=0 size=4.1943M
@wjones127 The numbers seem a bit low to be honest, but perhaps that's just me. I haven't looked at the implementation. @lidavidm What do you think?
The numbers seem a bit low to be honest
You are correct on that. Both too low in test and baseline, by about the same factor. I was creating too large of a chunked array for the indices.
Benchmark results
Baseline:
--------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
--------------------------------------------------------------------------------------------------------------
TakeChunkedInt64RandomIndicesNoNulls/4194304/1000 2770528 ns 2769802 ns 232 items_per_second=1.5143G/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/10 2802730 ns 2802061 ns 246 items_per_second=1.49686G/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/2 4277424 ns 4276390 ns 164 items_per_second=980.805M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/1 2143412 ns 2142790 ns 305 items_per_second=1.9574G/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/0 1886756 ns 1886230 ns 374 items_per_second=2.22364G/s null_percent=0 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1000 2799584 ns 2799301 ns 249 items_per_second=1.49834G/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/10 3865247 ns 3864123 ns 179 items_per_second=1085.45M/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/2 6030057 ns 6028330 ns 103 items_per_second=695.765M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1 1441460 ns 1440831 ns 498 items_per_second=2.91103G/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/0 1923944 ns 1923507 ns 371 items_per_second=2.18055G/s null_percent=0 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1000 1827538 ns 1827005 ns 383 items_per_second=2.29573G/s null_percent=0.1 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/10 1806226 ns 1805824 ns 387 items_per_second=2.32265G/s null_percent=10 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/2 2600097 ns 2599818 ns 269 items_per_second=1.61331G/s null_percent=50 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1 1069649 ns 1069057 ns 667 items_per_second=3.92337G/s null_percent=100 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/0 949020 ns 948810 ns 738 items_per_second=4.42059G/s null_percent=0 size=4.1943M
Proposed:
--------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
--------------------------------------------------------------------------------------------------------------
TakeChunkedInt64RandomIndicesNoNulls/4194304/1000 12734298 ns 12731491 ns 53 items_per_second=329.443M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/10 13030870 ns 13027741 ns 54 items_per_second=321.952M/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/2 11699983 ns 11697067 ns 60 items_per_second=358.577M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/1 8201179 ns 8200176 ns 85 items_per_second=511.489M/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesNoNulls/4194304/0 8281752 ns 8280094 ns 85 items_per_second=506.553M/s null_percent=0 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1000 10054480 ns 10052444 ns 54 items_per_second=417.242M/s null_percent=0.1 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/10 10256613 ns 10254956 ns 68 items_per_second=409.003M/s null_percent=10 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/2 8735435 ns 8734213 ns 80 items_per_second=480.215M/s null_percent=50 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/1 98487 ns 98479 ns 7191 items_per_second=42.5911G/s null_percent=100 size=4.1943M
TakeChunkedInt64RandomIndicesWithNulls/4194304/0 8187746 ns 8186131 ns 84 items_per_second=512.367M/s null_percent=0 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1000 2008840 ns 2007886 ns 352 items_per_second=2.08892G/s null_percent=0.1 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/10 2467236 ns 2466807 ns 285 items_per_second=1.7003G/s null_percent=10 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/2 3366623 ns 3365923 ns 208 items_per_second=1.24611G/s null_percent=50 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/1 1295032 ns 1294838 ns 538 items_per_second=3.23925G/s null_percent=100 size=4.1943M
TakeChunkedInt64MonotonicIndices/4194304/0 1240969 ns 1240848 ns 566 items_per_second=3.38019G/s null_percent=0 size=4.1943M
After some more testing it seems like concatenating buffers and indexing into that always wins over using ChunkResolver, both in primitive and string case.
From my quick test of Take on chunked string arrays:
- Concatenating: items_per_second=50.3014M/s
- ChunkResolver: items_per_second=6.9115M/s
Unless there is a more performant way, we might just only have Take kernels specialized for ChunkedArrays for String / Binary / List (and also Struct since it will then need to handle rechunking of child arrays.)
@edponce I know you looked at ChunkResolver recently in #12055. Do these results seem reasonable to you?
String ChunkedArray Take Benchmark Code
void BenchStringTest() {
// Create chunked string array
int32_t string_min_length = 0, string_max_length = 32;
const int64_t n_chunks = 10;
const int64_t array_size = args.size / n_chunks;
ArrayVector chunks;
for (int64_t i = 0; i < n_chunks; ++i) {
auto chunk = std::static_pointer_cast<StringArray>(
rand.String(args.size, string_min_length, string_max_length, 0));
chunks.push_back(chunk);
}
auto values = ChunkedArray(chunks);
// Create indices
auto indices =
rand.Int32(values.length(), 0, static_cast<int32_t>(values.length() - 1), 0);
for (auto _ : state) {
TypedBufferBuilder<int32_t> offset_builder;
TypedBufferBuilder<uint8_t> data_builder;
const int32_t* indices_values = indices->data()->GetValues<int32_t>(1);
if (concat_chunks) {
// Concat the chunks
ASSIGN_OR_ABORT(std::shared_ptr<Array> values_combined,
Concatenate(values.chunks()));
const uint8_t* values_data = values_combined->data()->GetValues<uint8_t>(1);
const int32_t* values_offsets = values_combined->data()->GetValues<int32_t>(2);
// for each value
for (int i = 0; i < indices->length(); ++i) {
int32_t index = indices_values[i];
// get the offset and size
int32_t offset = values_offsets[index];
int64_t length = values_offsets[index + 1] - offset;
// throw them on the builder
data_builder.UnsafeAppend(values_data + offset, length);
}
} else {
using arrow::internal::ChunkLocation;
using arrow::internal::ChunkResolver;
ChunkResolver resolver(values.chunks());
std::vector<const uint8_t*> values_data(values.num_chunks());
std::vector<const int32_t*> values_offsets(values.num_chunks());
for (int i = 0; i < values.num_chunks(); ++i) {
values_data[i] = values.chunks()[i]->data()->GetValues<uint8_t>(1);
values_offsets[i] = values.chunks()[i]->data()->GetValues<int32_t>(2);
}
// for each index
for (int i = 0; i < indices->length(); ++i) {
// Resolve the location
ChunkLocation location = resolver.Resolve(indices_values[i]);
// Get the offset and size
int32_t offset = values_offsets[location.chunk_index][location.index_in_chunk];
int32_t length =
values_offsets[location.chunk_index][location.index_in_chunk + 1] - offset;
// throw them on the builder
data_builder.UnsafeAppend(values_data[location.chunk_index] + offset, length);
}
}
}
}
@wjones127 I think the benchmark test is not doing a fair comparison as there is no need on copying the data and offsets into the temporary std::vectors. The first loop is not necessary. Nevertheless, there are only 10 chunks, so I wouldn't expect a significant penalty from it but better measure than assume.
Also, IIRC the binary search in ChunkResolver performs best when "taking" values pertaining to the same chunk (e.g., large chunks) because the previous chunk is cached.
Now, definitely a fixed array will be quicker to access (simple offset calculation) than a binary search across allocations that are not necessarily contiguous in hardware and may even reside in different OS pages. I'd be curious how the benchmark compares when using a large number of chunks: 10, 100, 1000 which is where the concatenation penalty is noticeable. Obviously, the sizes of the chunks also matter.
I'd be curious how the benchmark compares when using a large number of chunks: 10, 100, 1000 which is where the concatenation penalty is noticeable. Obviously, the sizes of the chunks also matter.
Reran with a variety of chunk sizes and total array sizes. It seems like ChunkResolver is only better in the extreme case of extremely small chunks (chunk size of 1000 and size of 4,194 means each chunk has about 4 elements).

@wjones127 Thanks for sharing these benchmarks. Are these results measured without the extra overhead of the temporary std::vector for the ChunkResolver case?
It is reasonable that the smaller the chunk size the better performance ChunkResolver cases are, due to chunk caching and the higher probability of hitting the same chunk consecutively.
Performance is a tricky business bc it depends on the metrics you are evaluating for. Both approaches have advantage and disadvantage. If you have a large dataset and are somewhat memory constrained, the concatenation approach may not be adequate due to the extra storage. The ChunkResolver is the most general solution with least overhead on memory use and still reasonable performance. AFAIK, Arrow does not tracks memory statistics to permit selecting which of these approaches should be used. Well, maybe adding an option for the client code to decide but this does not seem to follow Arrow's general design.
@wjones127 These numbers are for the random or monotonic use case?
That's for random. Here is it including monotonic, which makes it more complex:
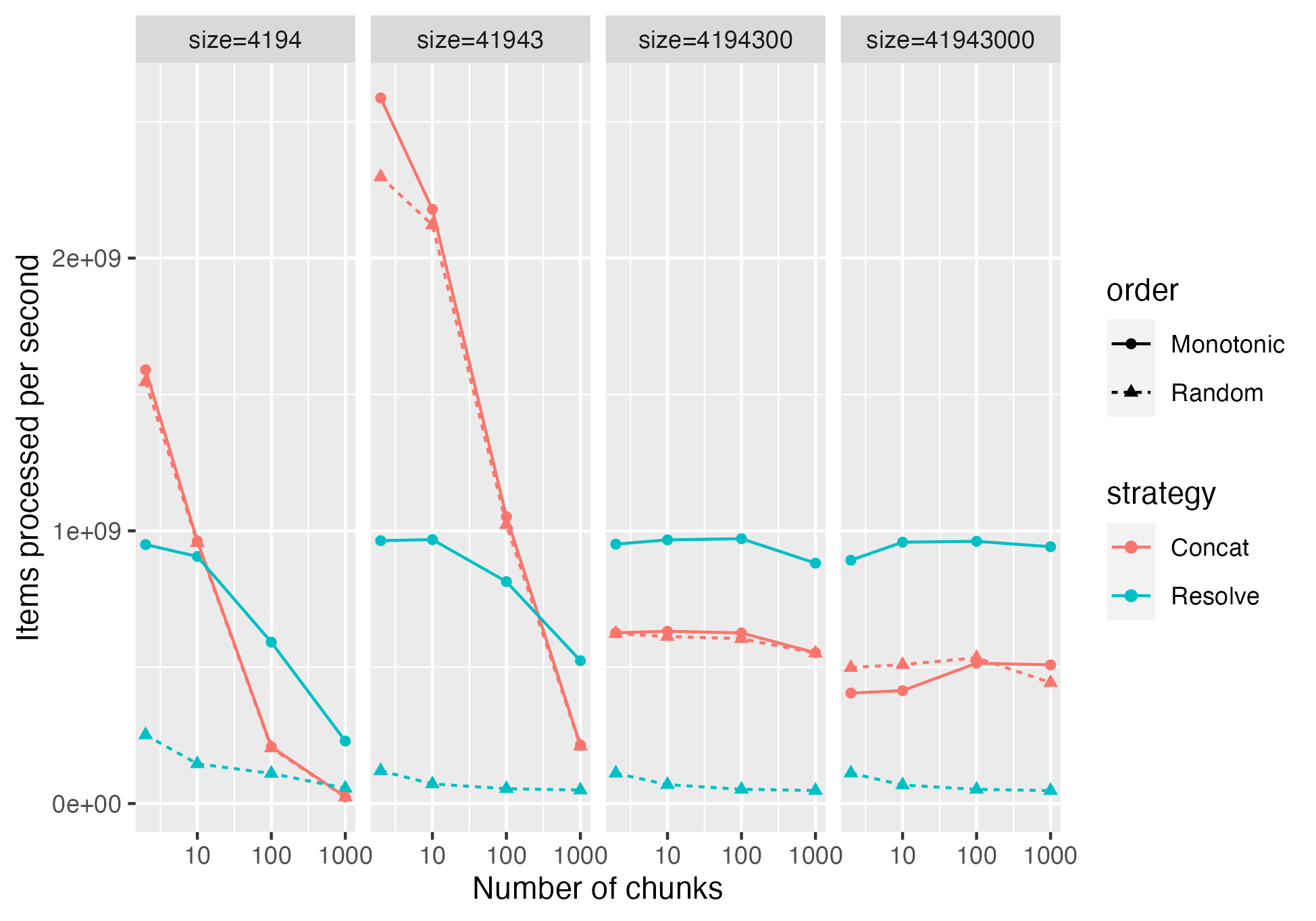
So it seems like it's better in the monotonic case, but worse in the random case. My benchmark code is available here: https://github.com/wjones127/arrow/blob/370d0870c68627224aedcfb79cfd7ceb7d0dfa99/cpp/src/arrow/compute/kernels/vector_selection_benchmark.cc#L206-L277
Are these results measured without the extra overhead of the temporary std::vector for the ChunkResolver case?
I hadn't removed it. Removed it in the test that I'm showing results for above.
The ChunkResolver is the most general solution with least overhead on memory use and still reasonable performance.
In some cases it seems like it would be a serious regression; so I'm trying to figure out which cases those are if we can avoid using ChunkResolver in those cases.
It's hard to say if that extra memory usage is that significant. I feel like some extra memory usage will always happen within compute function. This is large since it needs to operate on the entire chunk, rather than just a chunk at a time. But also with memory pools we can rapidly reuse memory; so I imagine for example if we are running Take() on a Table with multiple string columns, the memory used temporarily for the first one could be re-used when processing the second.
From the results above, before performing the Take operation what information do we know that could allow us to select the adequate strategy?
- The main factor driving the differences is the indices access order (random vs monotonic). I do not think we can identify a priori if the take indices are monotonic or random. If so, we can clearly select a strategy. Please correct me if I'm wrong here.
- Number of chunks and size we can get from the chunked array.
Now let's try to very hand-wavy summarize some observations based on logical array size.
Random order
- 1K --> concat is ~2x faster
- 10K --> concat is ~4x faster
- 1M and 10M --> concat is ~1.5x faster
Monotonic order
- 1K and 10K --> concat is significantly faster for up to 10's number of chunks, ChunkResolver is faster for 100 and 1K chunks
- 1M and 10M --> ChunkResolver is ~1.5x faster
Based on this a general decision rule could be, if indices are random or array size and number of chunks is not that large, use concat, otherwise ChunkResolver. But if we can't identify access order, then it does looks like concat would be a better choice assuming most use cases of Take make random accesses.
An alternative approach could be to add a configuration flag in Arrow that states "optimize for speed or optimize for storage", and this could be used to select strategies all throughout.