Resolve OOM When Reading Large Logs in Webserver
related issue: #45079 related PR: #45129 related discussion on slack: https://apache-airflow.slack.com/archives/CCZRF2U5A/p1736767159693839
Why
In short, this PR aims to eliminate OOM issues by:
- Replacing full log sorting with a K-Way Merge
- Making the entire log reading path streamable (using
yieldgenerators instead of returning a list of strings)
More detailed reasoning is already described in the linked issue.
Due to too many conflicts with the old PR (#45129), this PR reworks the changes on top of the latest FileTaskHandler.
What
This PR ports the original changes from #45129 to the current version of FileTaskHandler with the following updates:
- Fixed line-splitting error when reading in chunks using buffered line-splitting with a carry-over
- Adopted the new log metadata structure
- Introduced buffering for the log reader
Note: Recent Changes in FileTaskHandler
- Introduced
StructuredLogMessageto represent each log record #46827 - Added
RemoteLogIOinterface for remote log handling #48491
There is still an issue with the compat 3.0.0 tests for ElasticsearchTaskHandler and OpensearchTaskHandler, as they directly implement the FileTaskHandler._read method.
This refactor introduces a new streaming return type for _read, which causes a breaking change for both ElasticsearchTaskHandler and OpensearchTaskHandler in 3.0.0.
If we backport this PR to v3-0-test, it might fix the compat 3.0.0 tests — but we need to merge this first before cherry-picking.
I'm not entirely sure how to best handle this chicken-and-egg situation. Any suggestions?
If we backport this PR to
v3-0-test, it might fix thecompat 3.0.0tests — but we need to merge this first before cherry-picking. I'm not entirely sure how to best handle this chicken-and-egg situation. Any suggestions?
I am afraid we will have to make it backwards-compatible in some way. I don't think we are going to yank 3.0.0, so theorethically (and many people do that) someone could install airflow 3.0.0 and then use newer provider version. We could - of course- potentially add exclusion apache-airflow != 3.0.0 in those providers, but that would not be very nice message and we would have to - indeed - split it, backport only the the core change to 3.0.0, release 3.0.1, and only after that merge the changes to the providers and add != 3.0.0 there. But that is not a good idea I think unless we really cannot find a way to use common-compat or other if/else code to make things compatible.
I am afraid we will have to make it backwards-compatible in some way. I don't think we are going to yank 3.0.0, so theorethically (and many people do that) someone could install airflow 3.0.0 and then use newer provider version. We could - of course- potentially add exclusion
apache-airflow != 3.0.0in those providers, but that would not be very nice message and we would have to - indeed - split it, backport only the the core change to 3.0.0, release 3.0.1, and only after that merge the changes to the providers and add != 3.0.0 there. But that is not a good idea I think unless we really cannot find a way to use common-compat or other if/else code to make things compatible. Here’s a polished and more fluent version of your paragraph:
Thanks for the advice!
I'll proceed with defining the method conditionally inside the class.
Since the current _read implementation is already a bit complex due to compatibility with both 2.10+ and 3.0,
having a separate _read method using AIRFLOW_V_3_0 and AIRFLOW_V_3_0_PLUS flags to handle version-specific logic would make the code cleaner.
I'll mark the PR as draft for now — I’ll need a bit more time to make it compatible for both 3.0-specific and 3.0+ cases.
The PR to resolve OOM when reading large logs in the webserver, targeting the 3.0+ branch, is ready for review. I’d really appreciate your feedback.
Hi @uranusjr
I’ve resolved the compatibility issue related to the log_pos key in the log metadata by introducing a LogStreamCounter. This allows us to accurately determine the total line count while still supporting streaming log responses.
Additionally, I’ve added tests for the get_log endpoint to cover different Accept headers.
Thanks for the review!
A detailed benchmark covering various scenarios after this refactor is also included. cc @potiuk, @ashb
Setup
The benchmark is conducted using Breeze with only the api-server process running.
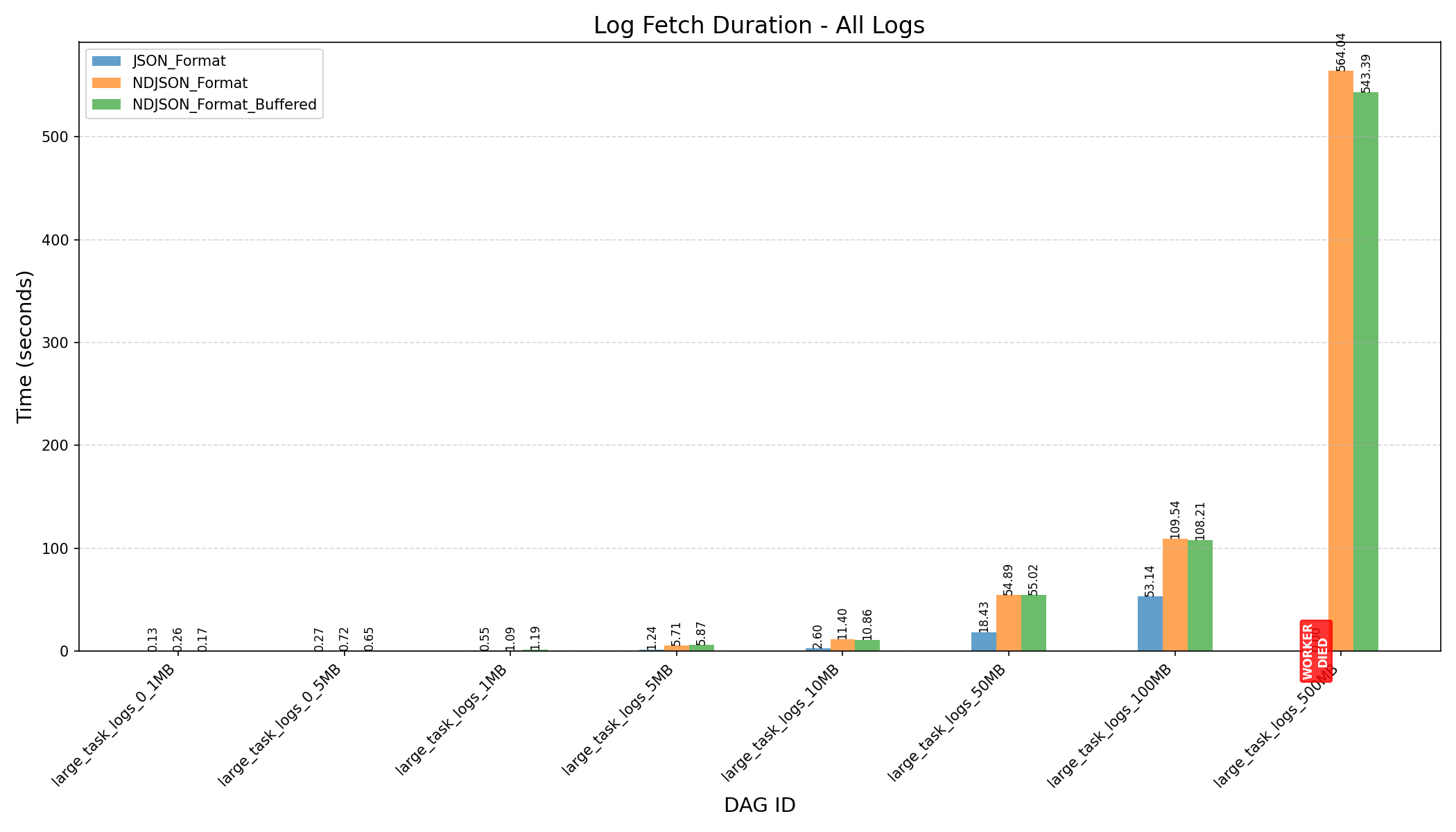
- Log Sizes:
- Small Logs (≤10MB):
- 800 lines, 0.1MB
- 4,000 lines, 0.5MB
- 8,000 lines, 1MB
- 40,000 lines, 5MB
- 80,000 lines, 10MB
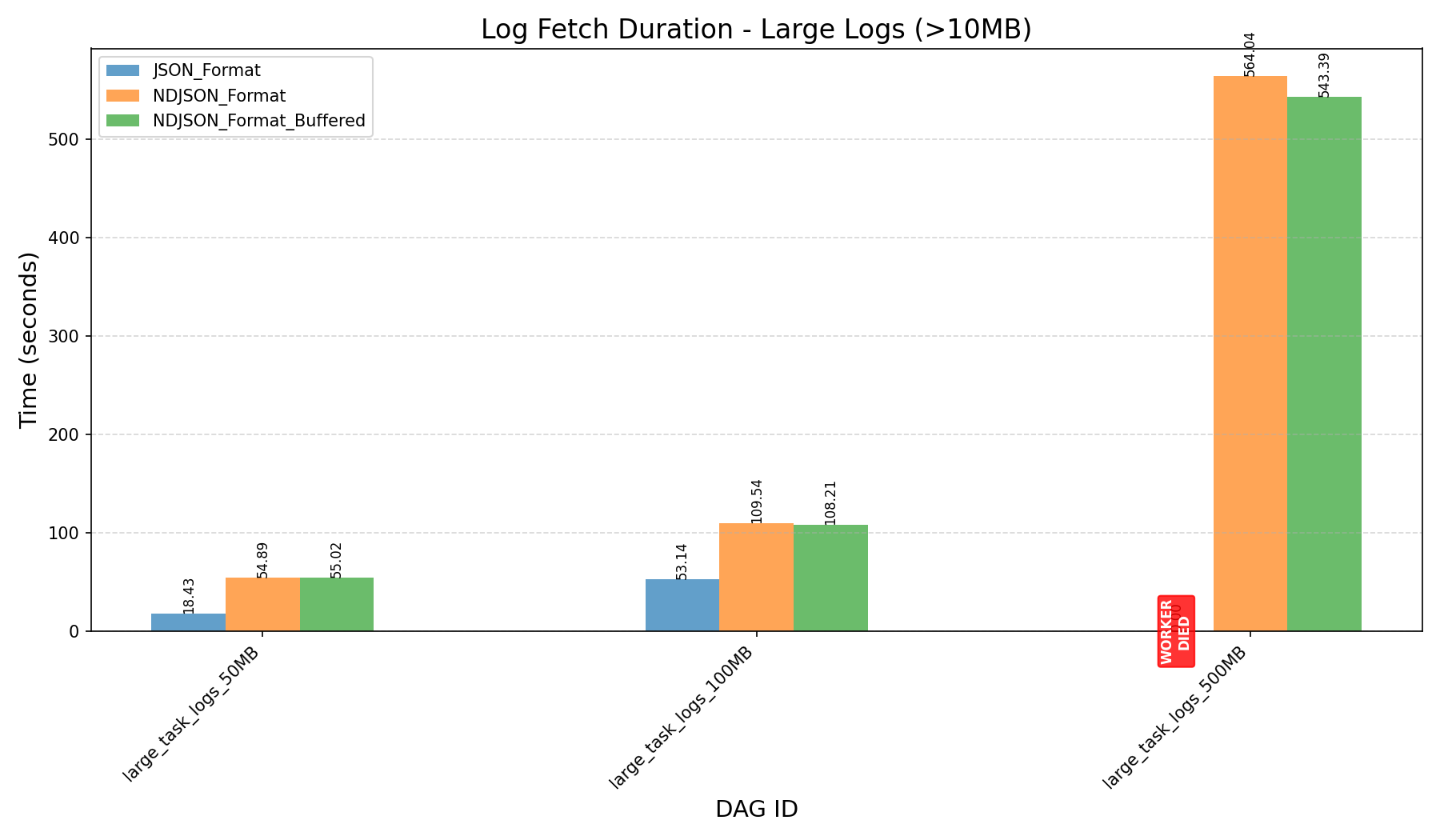
- Large Logs (≥50MB):
- 400,000 lines, 50MB
- 800,000 lines, 100MB
- 4,000,000 lines, 500MB
- Small Logs (≤10MB):
- Each log line is a simple
print(uuid4()), producing output like:{"timestamp":"2025-05-24T12:08:30.518970Z","event":"08e178da-c9ff-413d-8ce4-13765be56ca7","level":"info","chan":"stdout","logger":"task"} - Response Formats:
- JSON Format
- NDJSON Format (enables streaming, leveraging StreamingResponse in FastAPI)
- NDJSON Format + Buffered TaskLogReader
- HEAP_DUMP_SIZE: Various values tested for performance and memory impact.
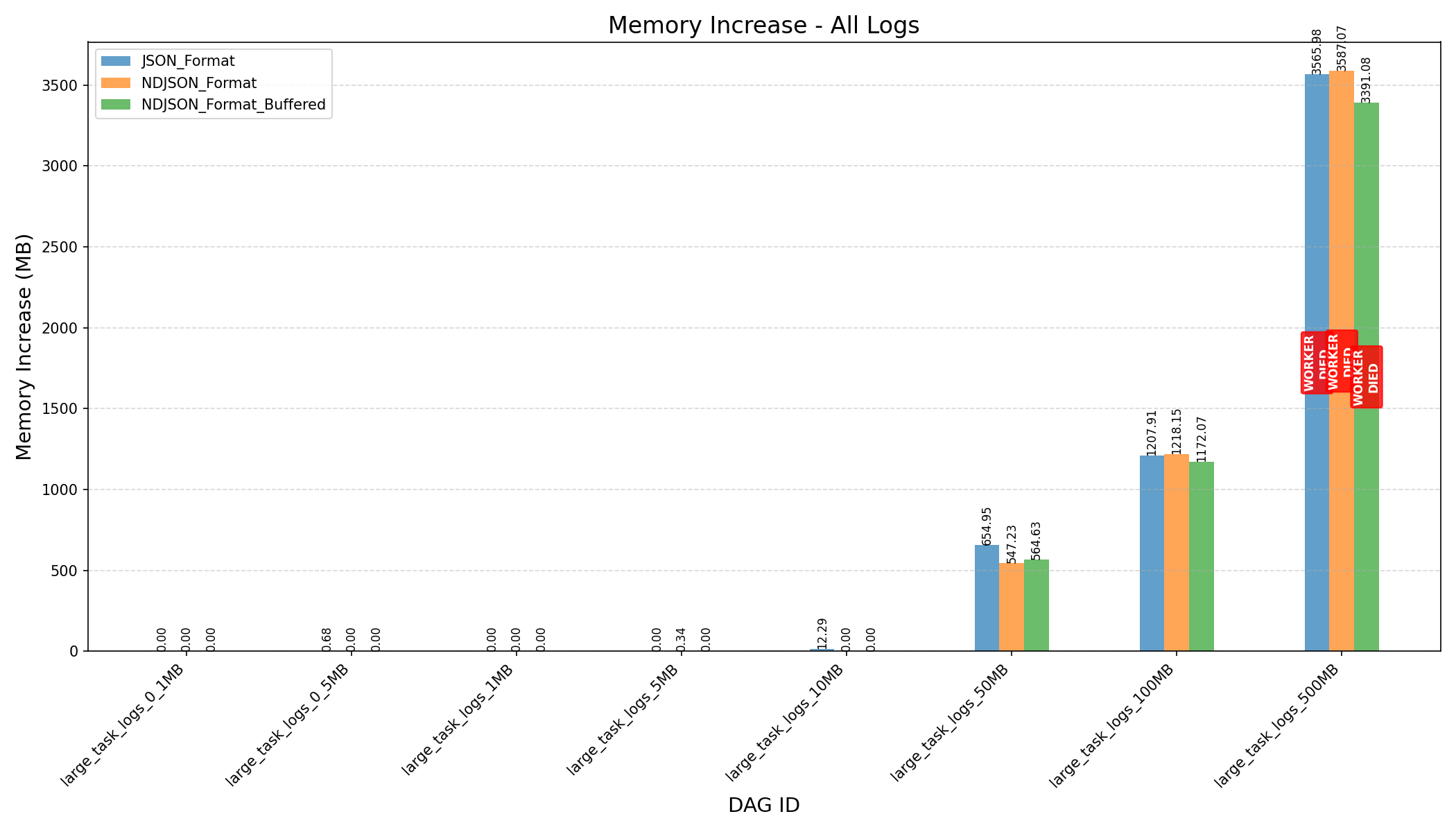
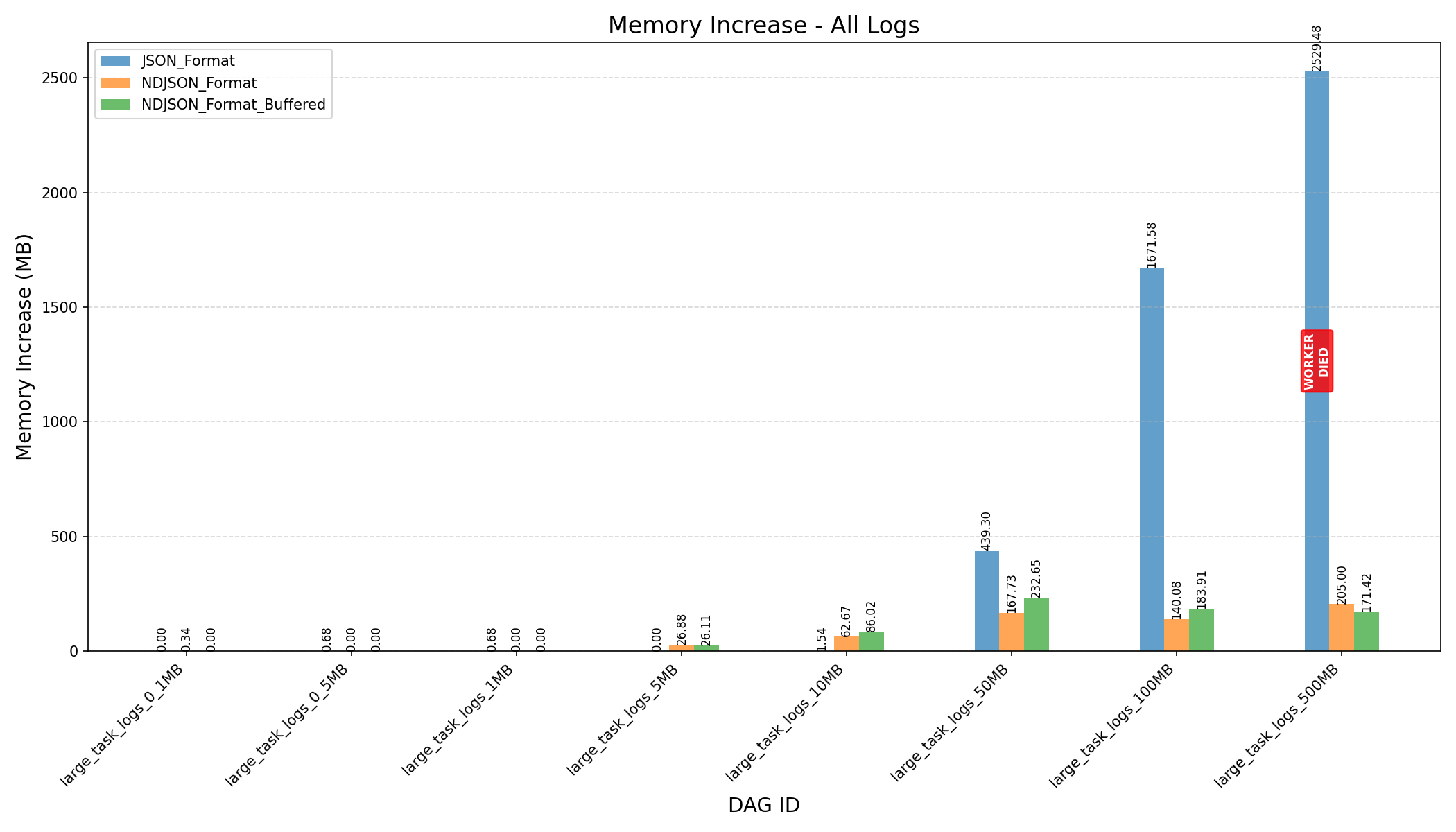
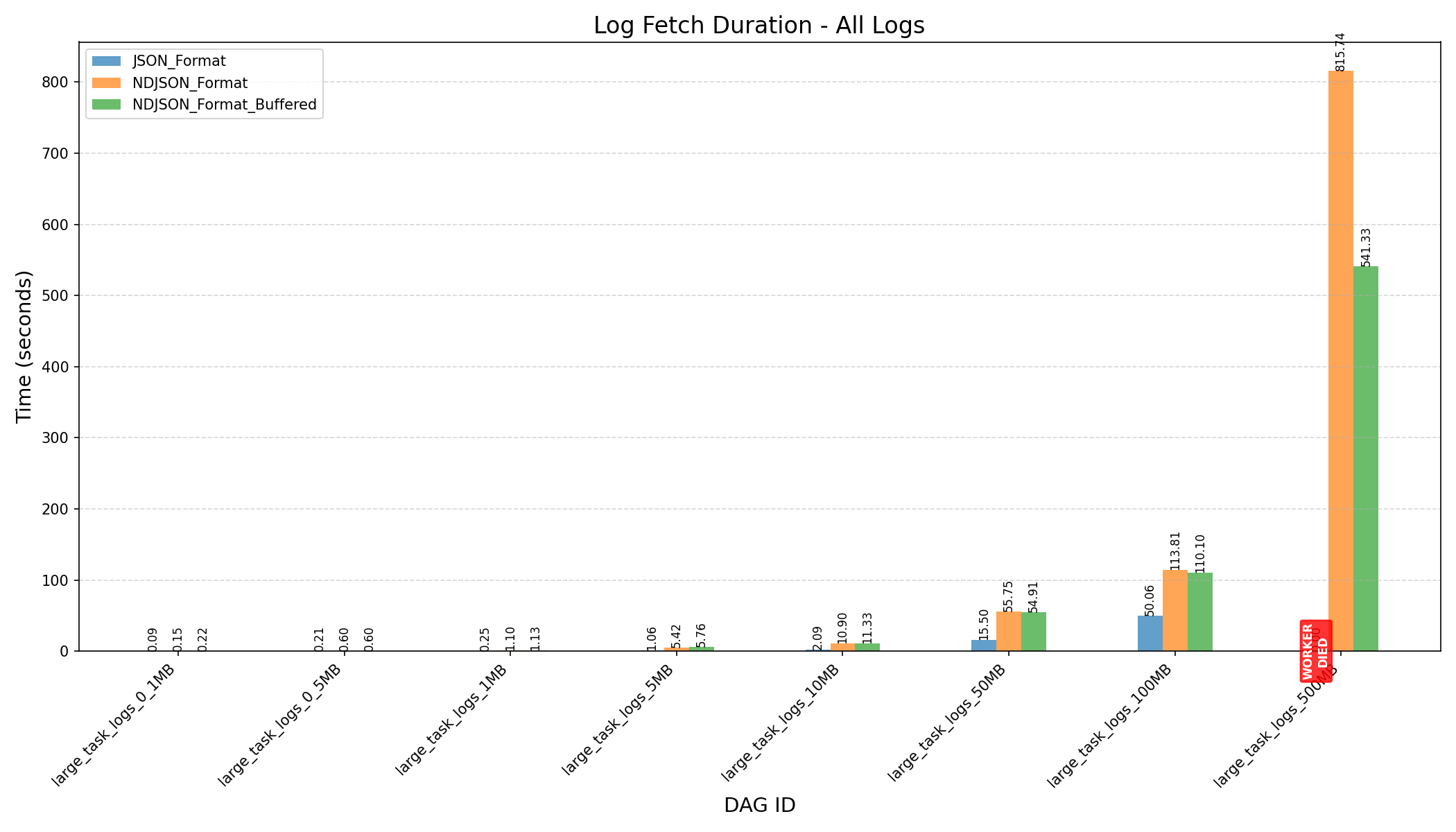
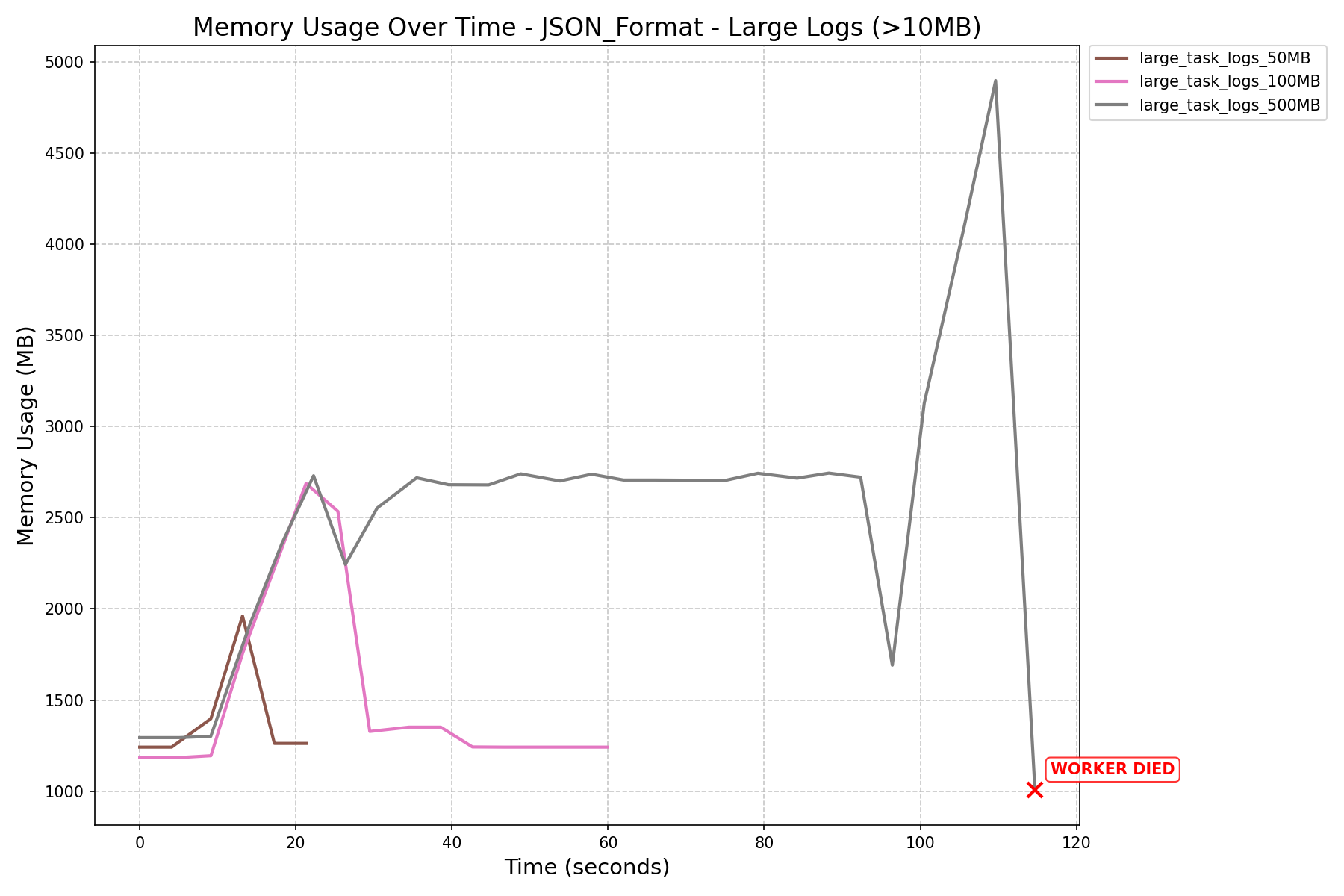
Summary
- K-Way Merge + Streaming:
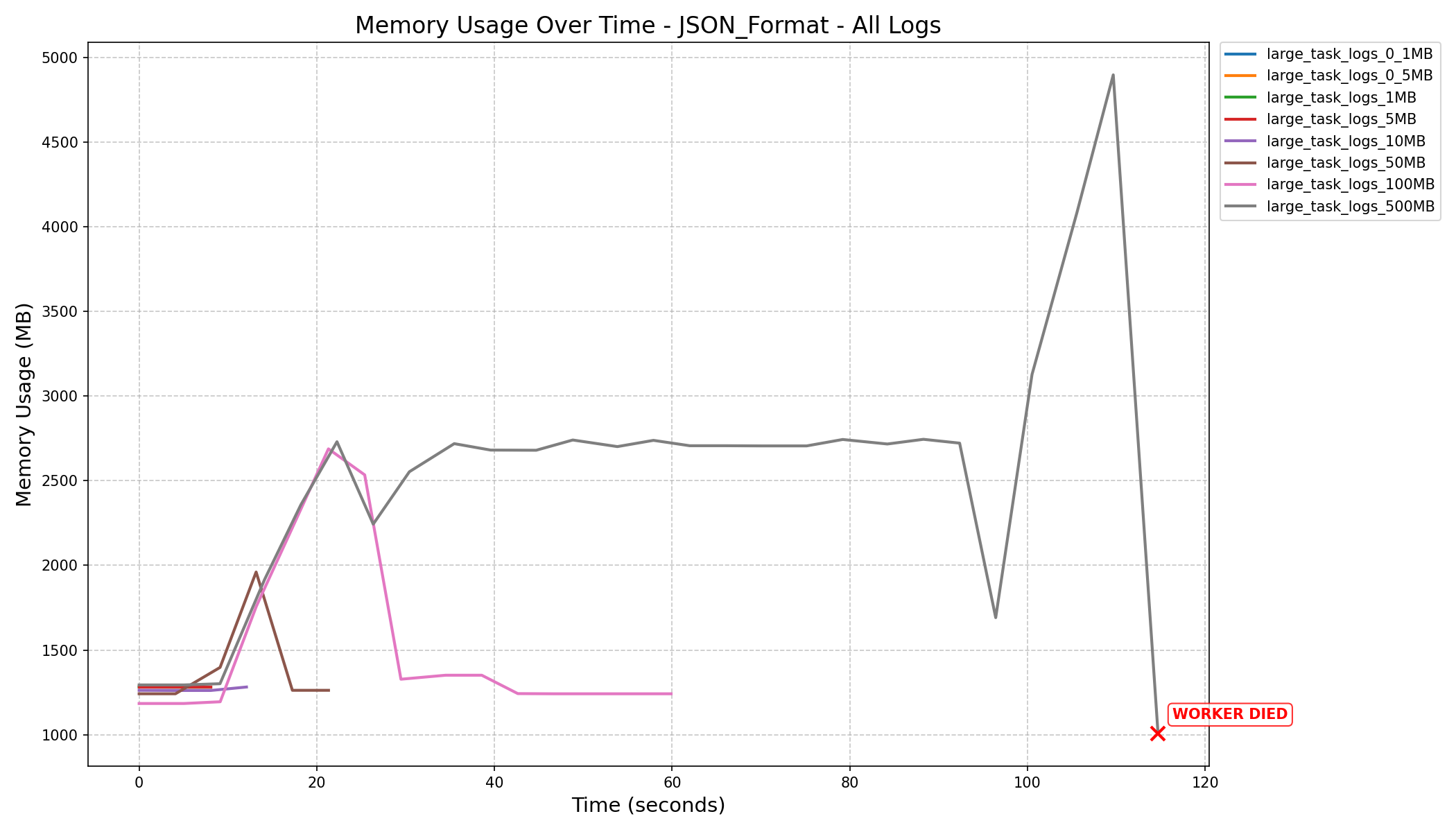
- Before the refactor, workers crashed when processing 500MB logs.
- After the refactor, with a fine-tuned
HEAP_DUMP_SIZE, memory usage dropped by nearly 100x (3587MB→33MBfor 500MB logs).
- HEAP_DUMP_SIZE:
- Significantly affects memory usage and log fetching performance.
- Setting
HEAP_DUMP_SIZE=5000(instead of the default500000) provides a good balance:- Fetch duration is similar between
5000and10000. - Memory usage is substantially lower with
5000, even for large logs.
- Fetch duration is similar between
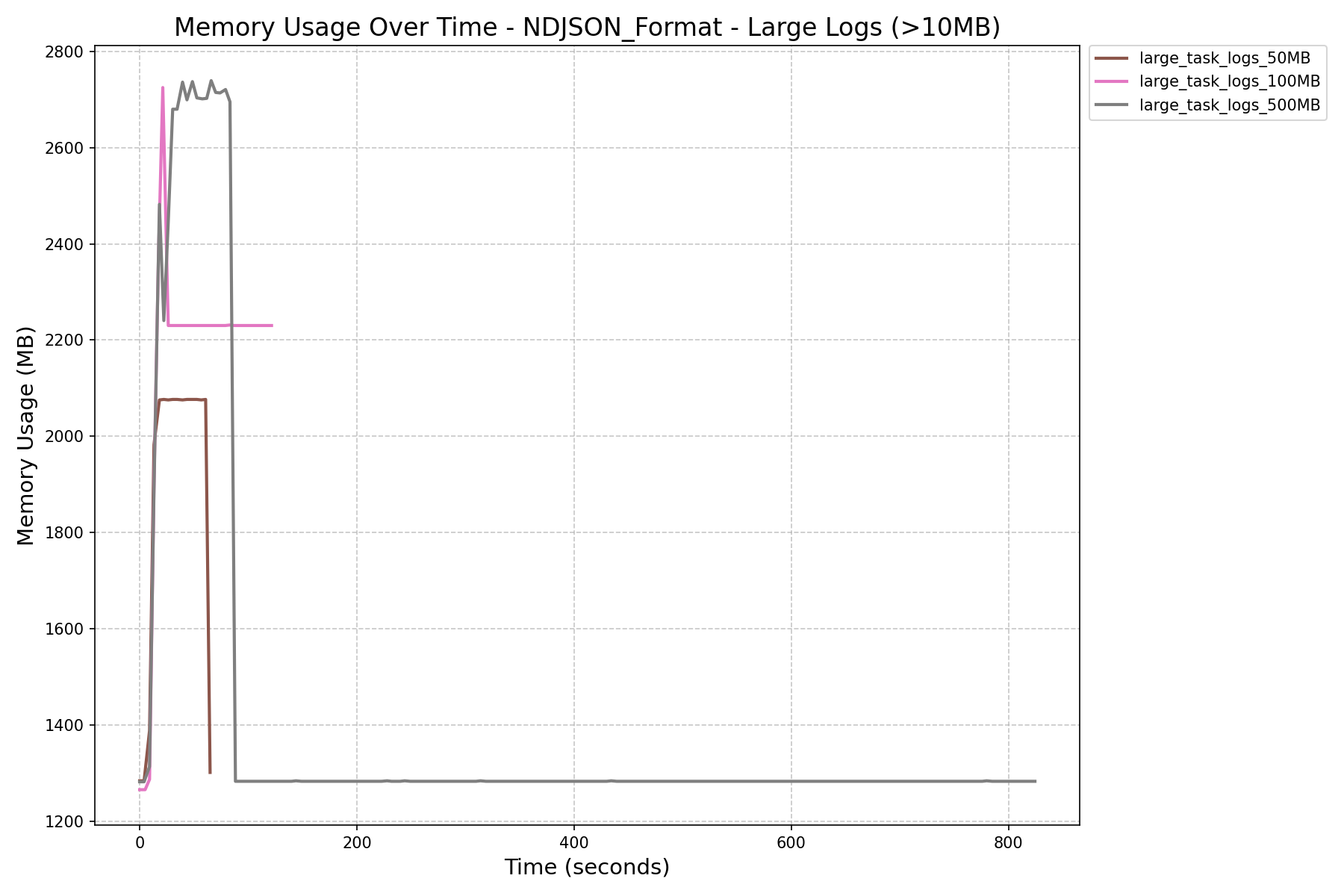
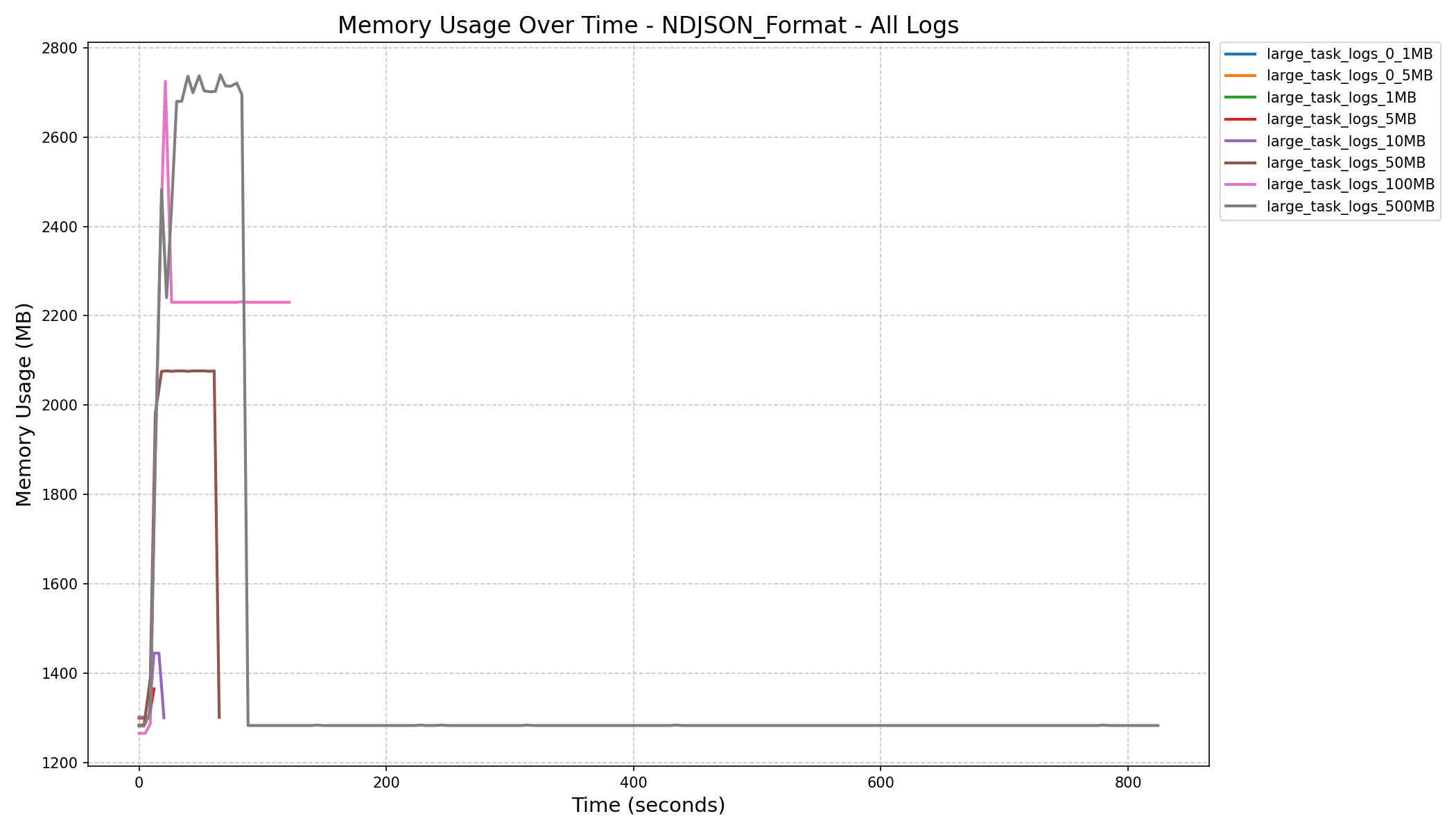
- JSON Format vs NDJSON Format:
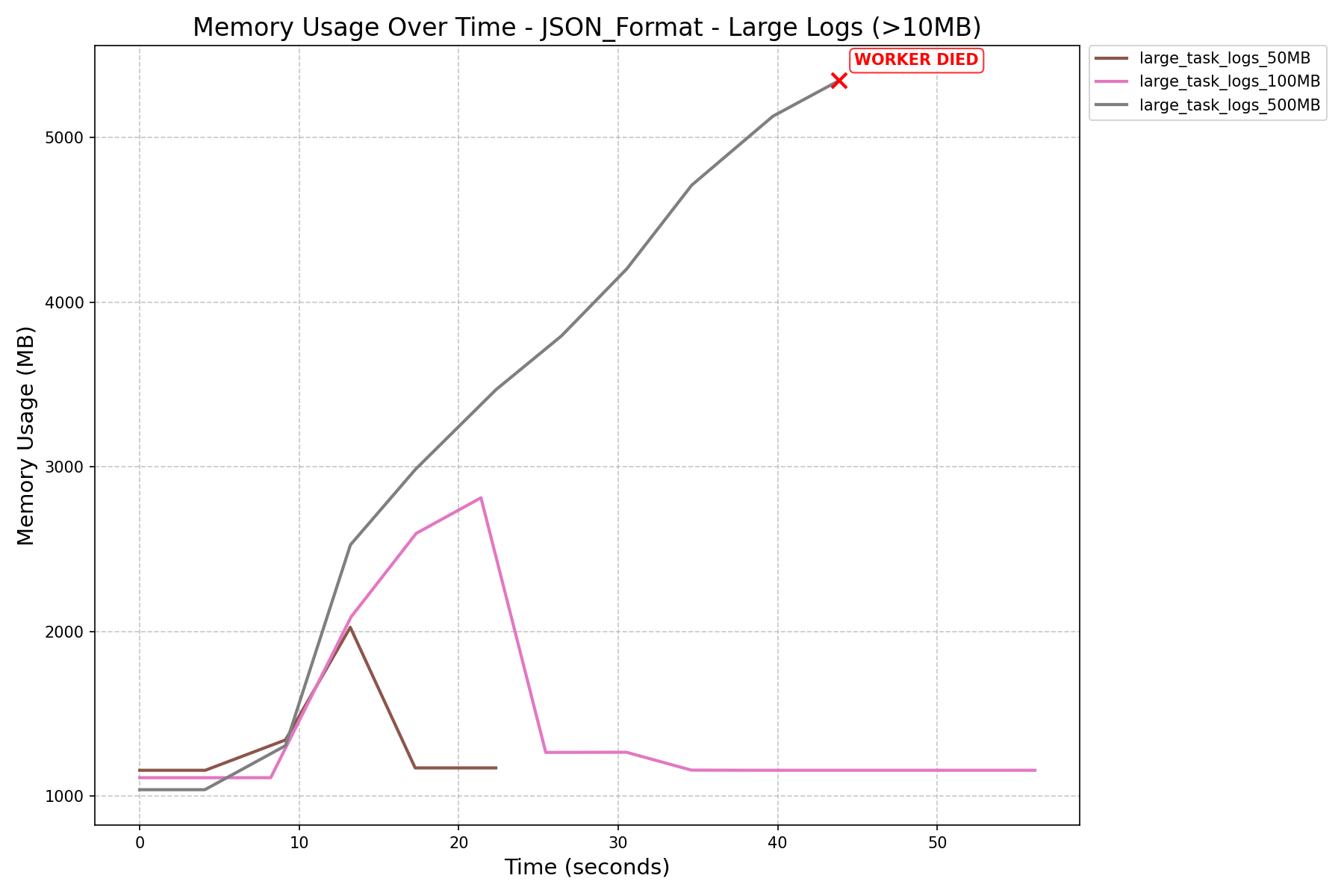
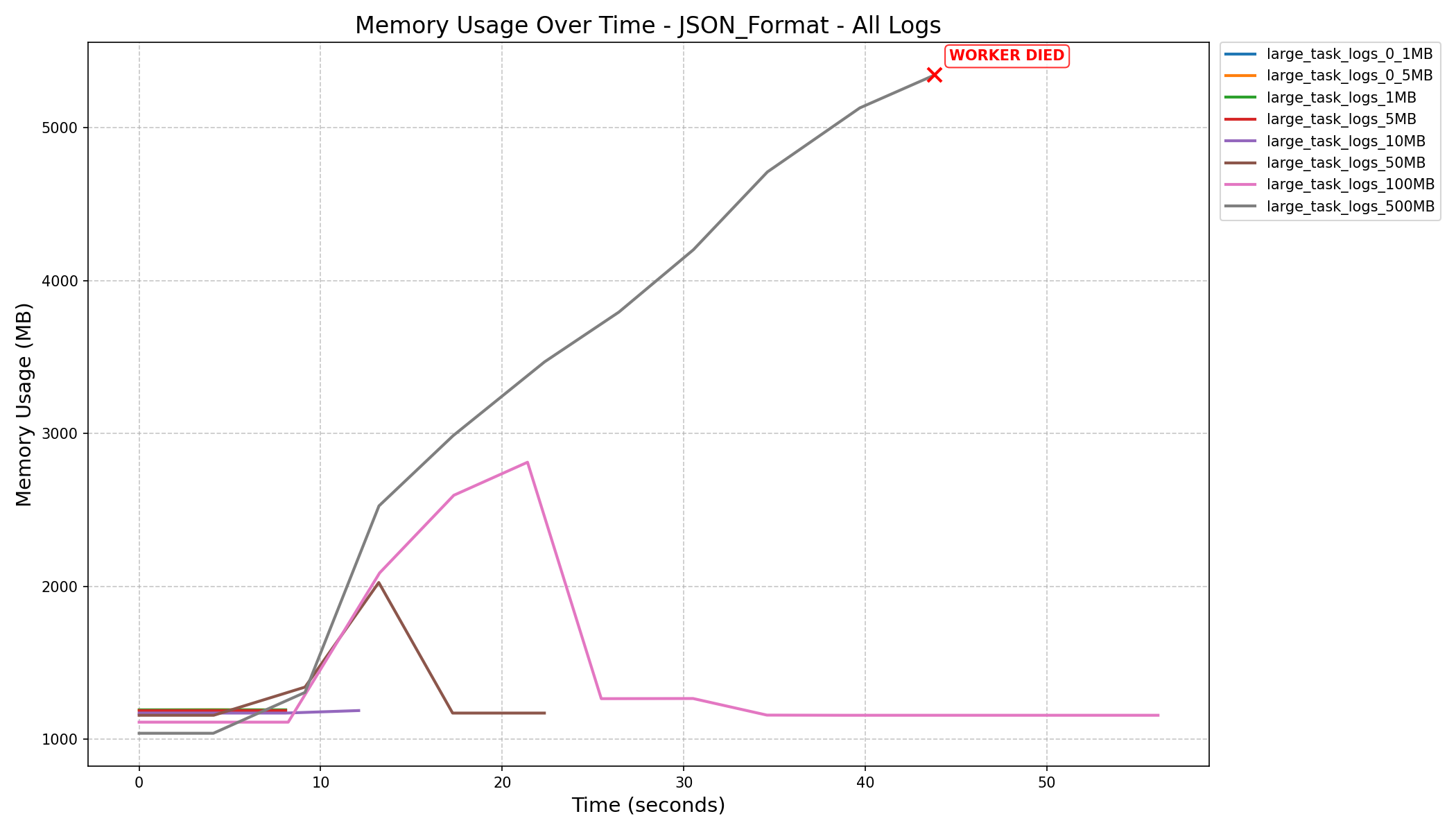
- JSON format consumes more memory and can still cause workers to crash on large logs, even after the refactor.
- Buffered TaskLogReader:
- Introducing a buffered reader in
TaskLogReaderyields, however only a ~1% performance improvement in fetching logs. - The buffered reader will be removed in the final PR.
- Introducing a buffered reader in
Benchmark Results: K-Way Merge + Streaming
Before Refactoring
| Small Logs (≤10MB) | Large Logs (≥ 50MB) | All Logs | |
|---|---|---|---|
| Log Fetch Duration (in seconds) | 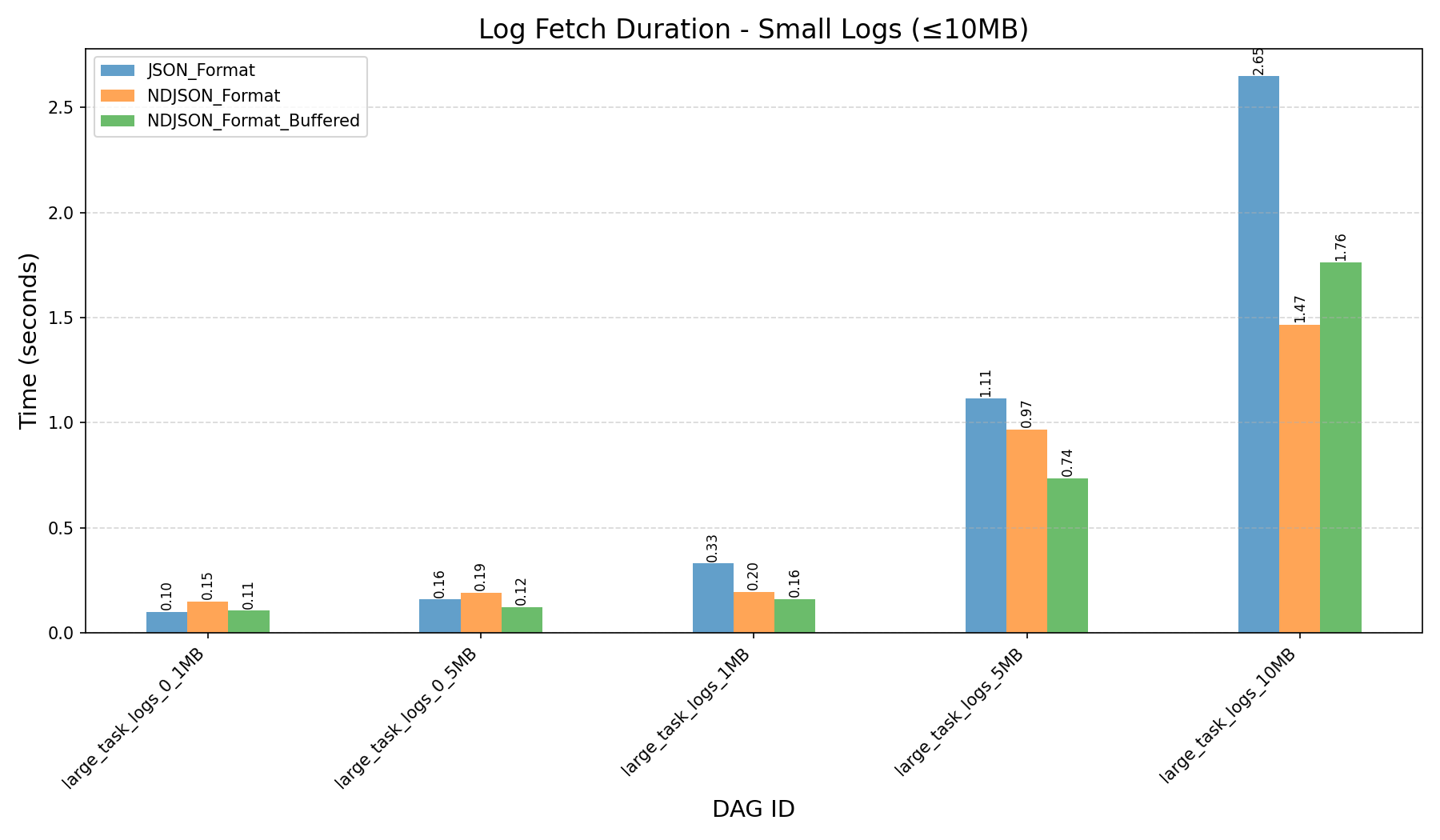 |
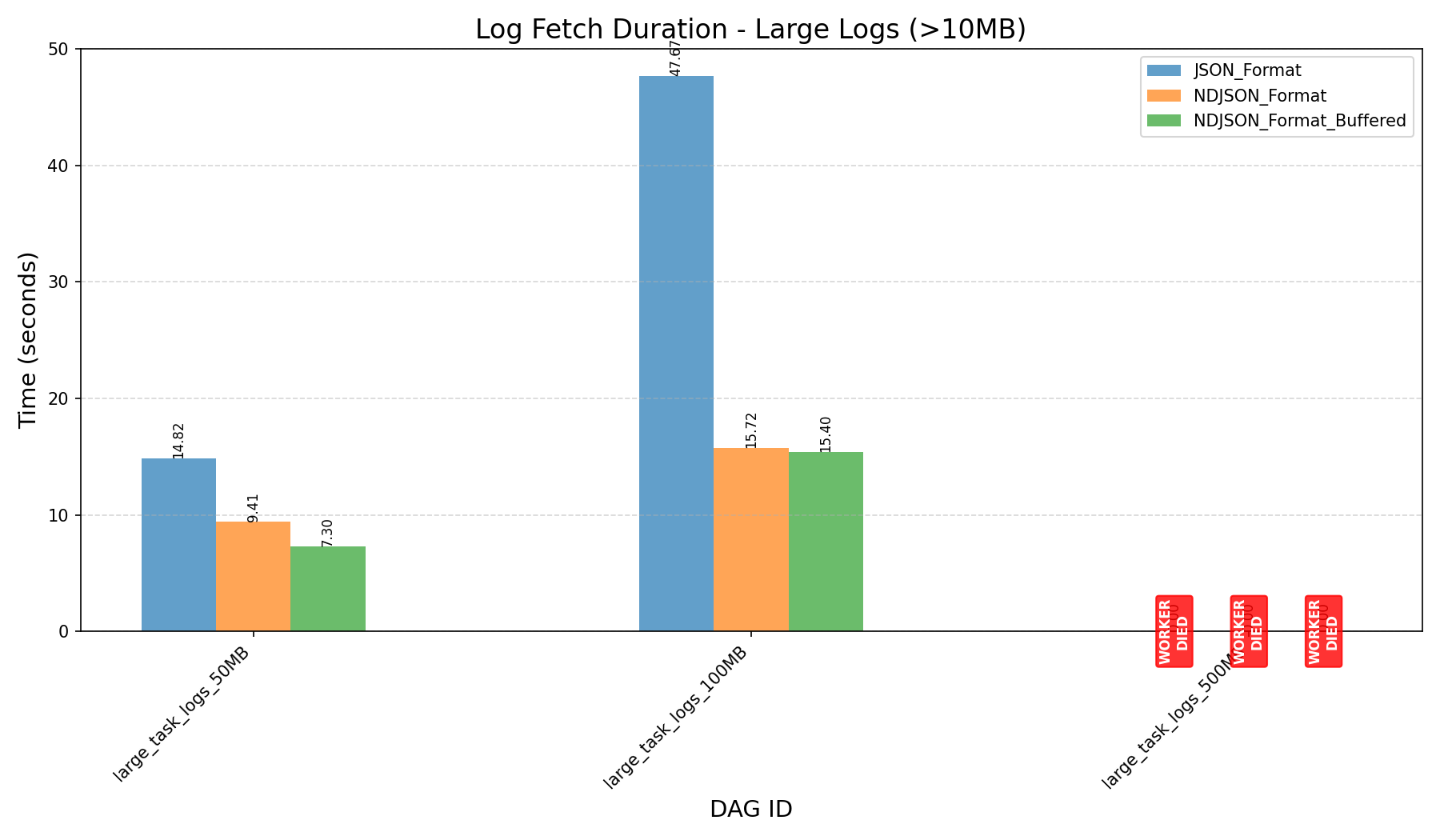 |
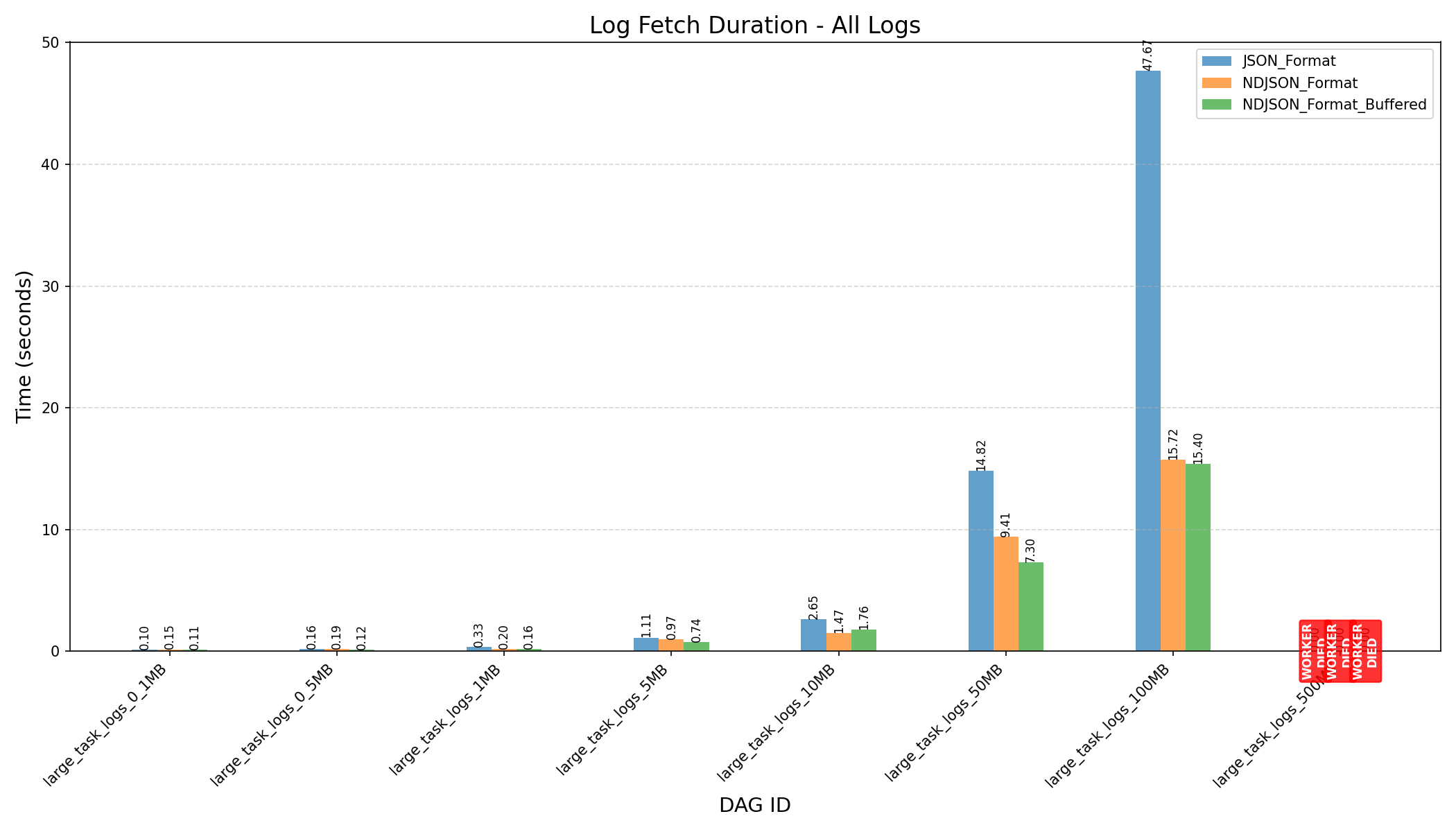 |
| JSON Format Memory History (in MB) | 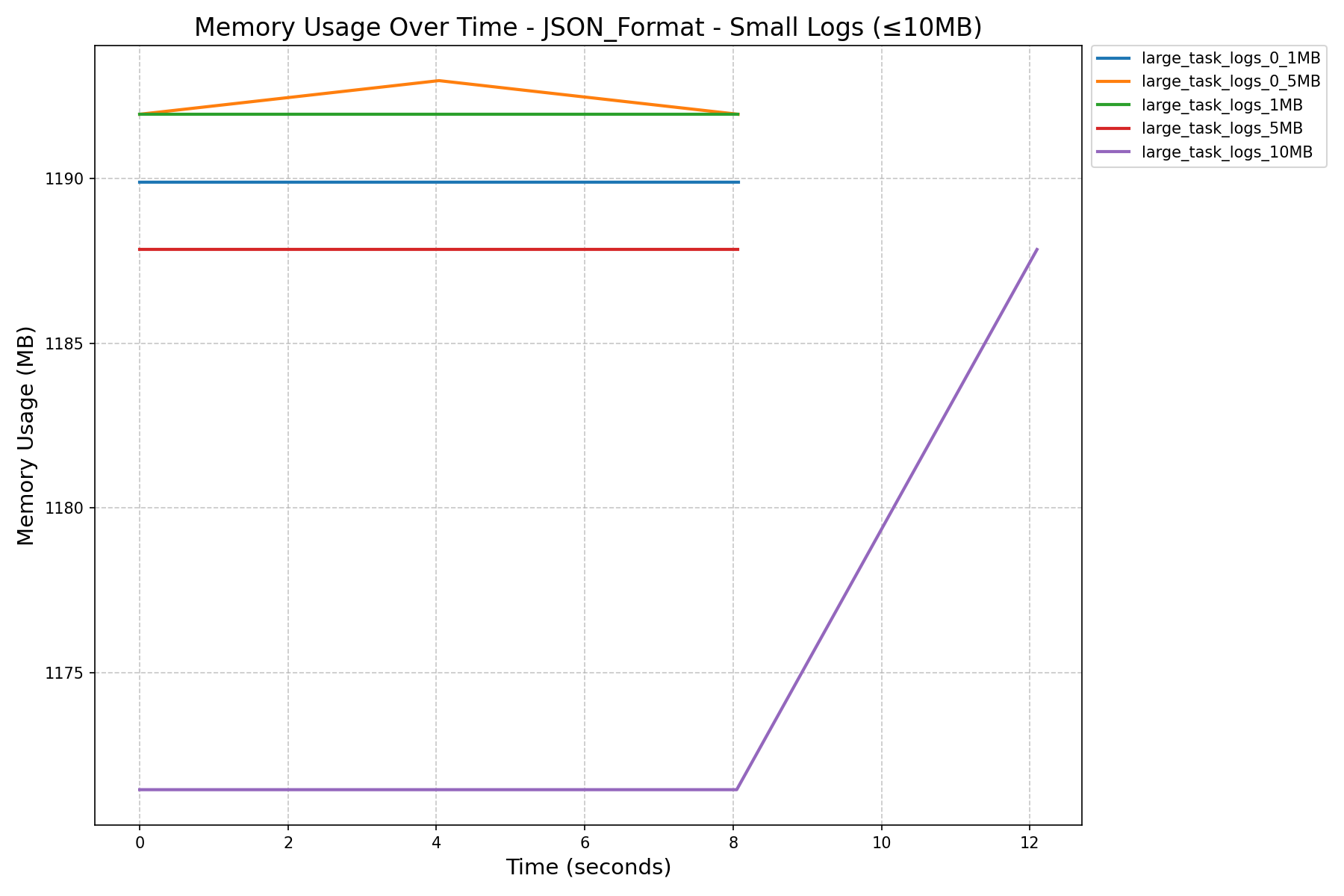 |
 |
 |
| Memory Increase (in MB) | 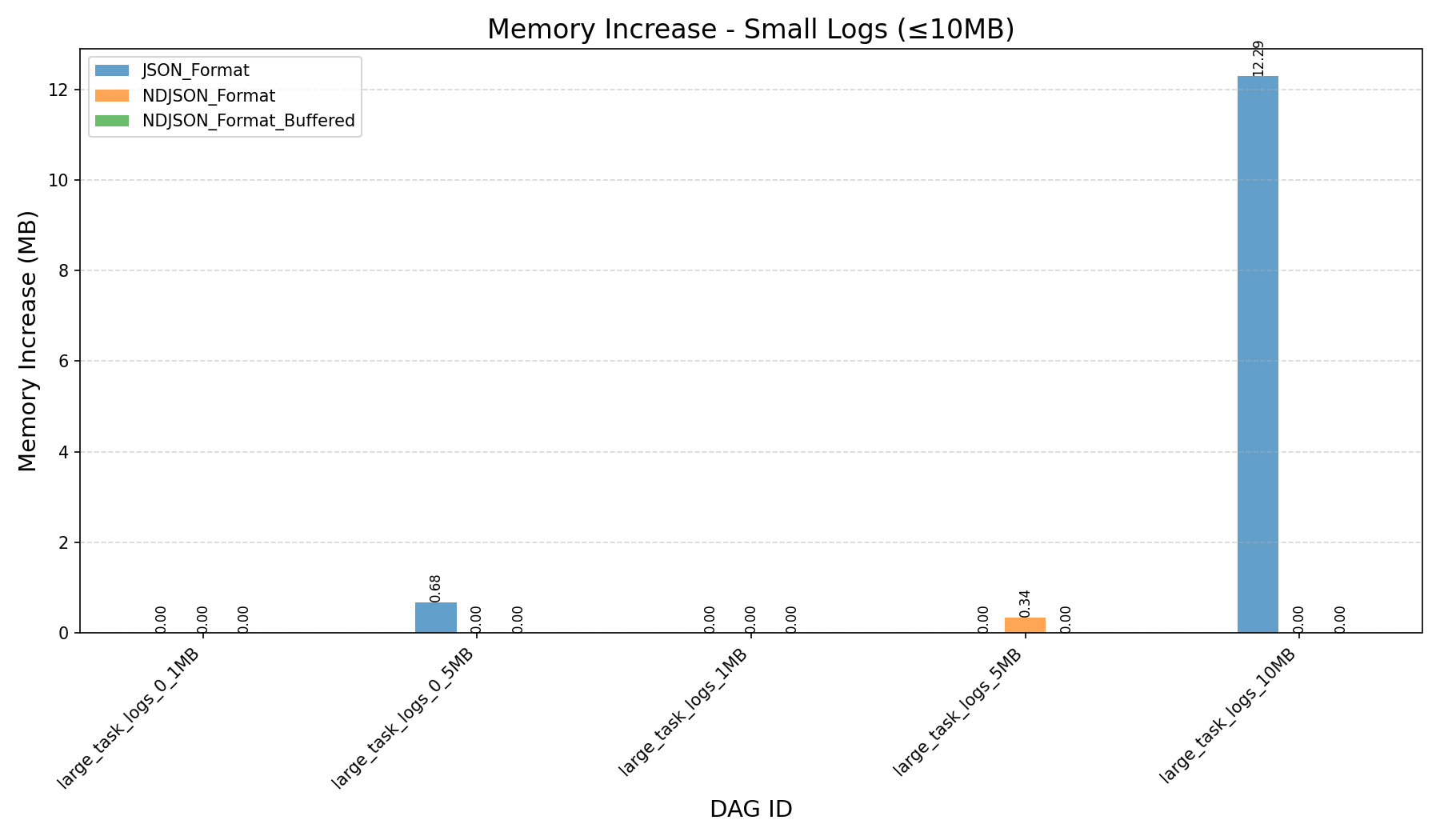 |
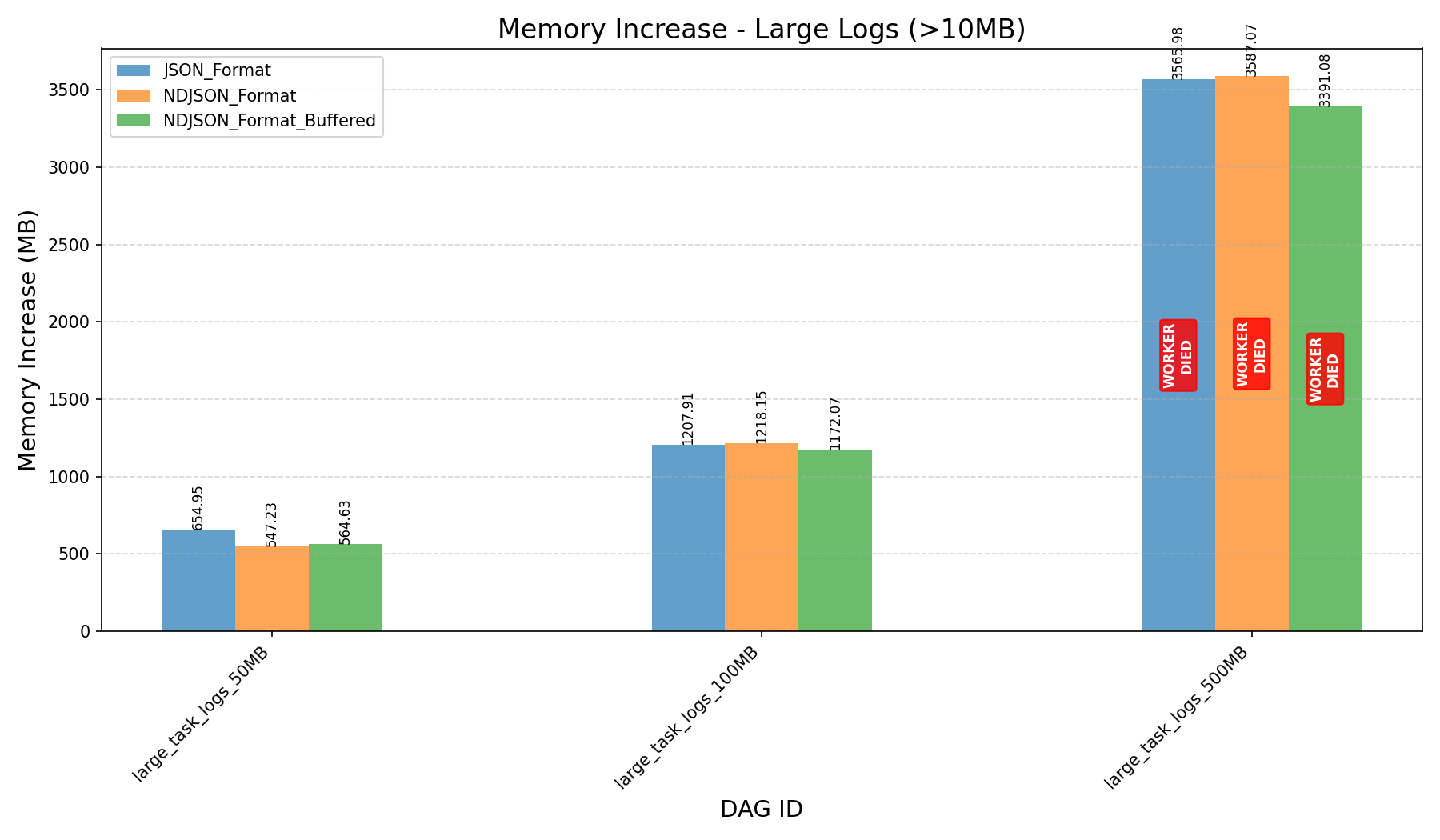 |
 |
After Refactoring HEAP_DUMP_SIZE = 100000
| Small Logs (≤10MB) | Large Logs (≥ 50MB) | All Logs | |
|---|---|---|---|
| Log Fetch Duration (in seconds) | 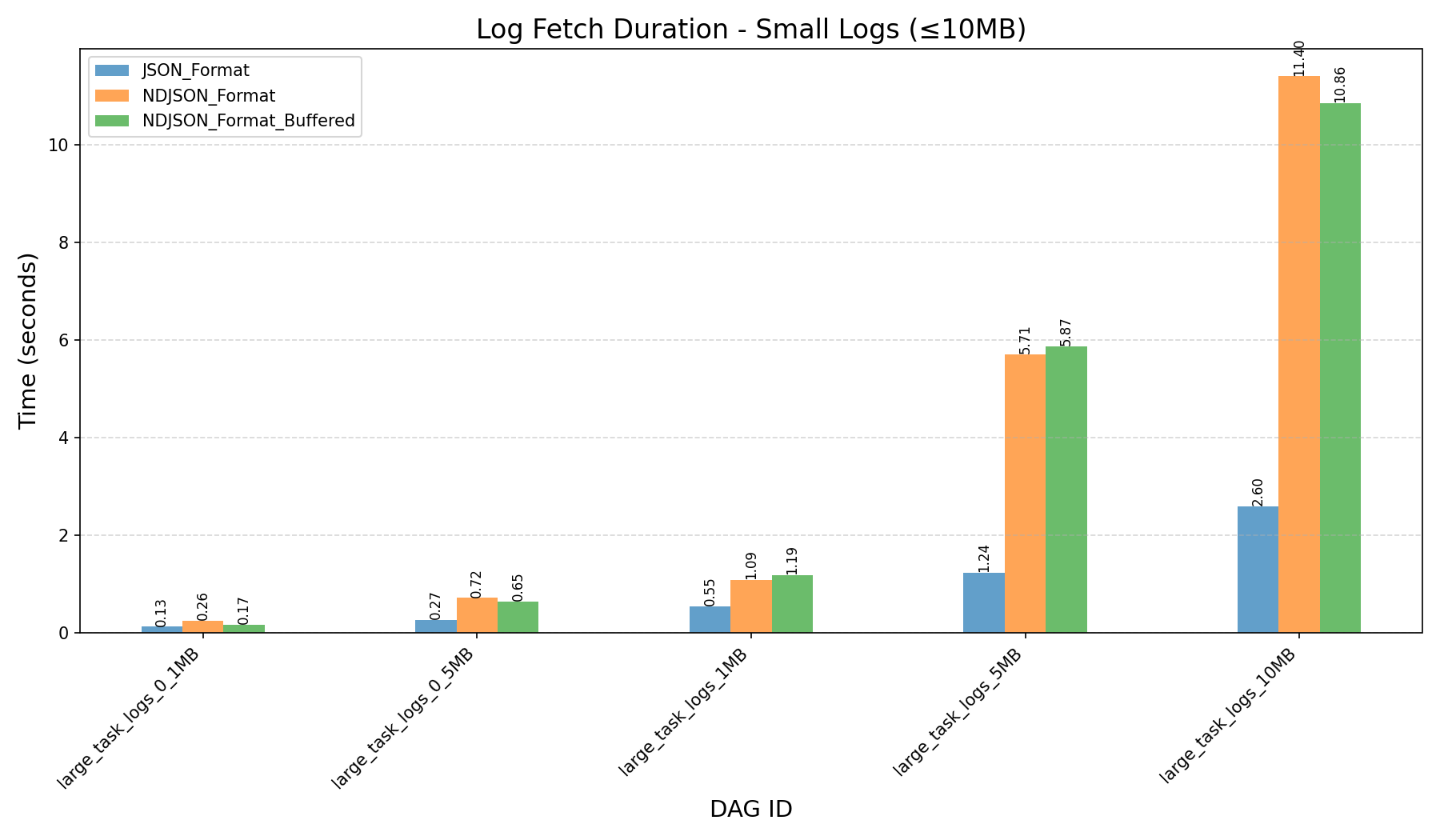 |
 |
 |
| JSON Format Memory History (in MB) | 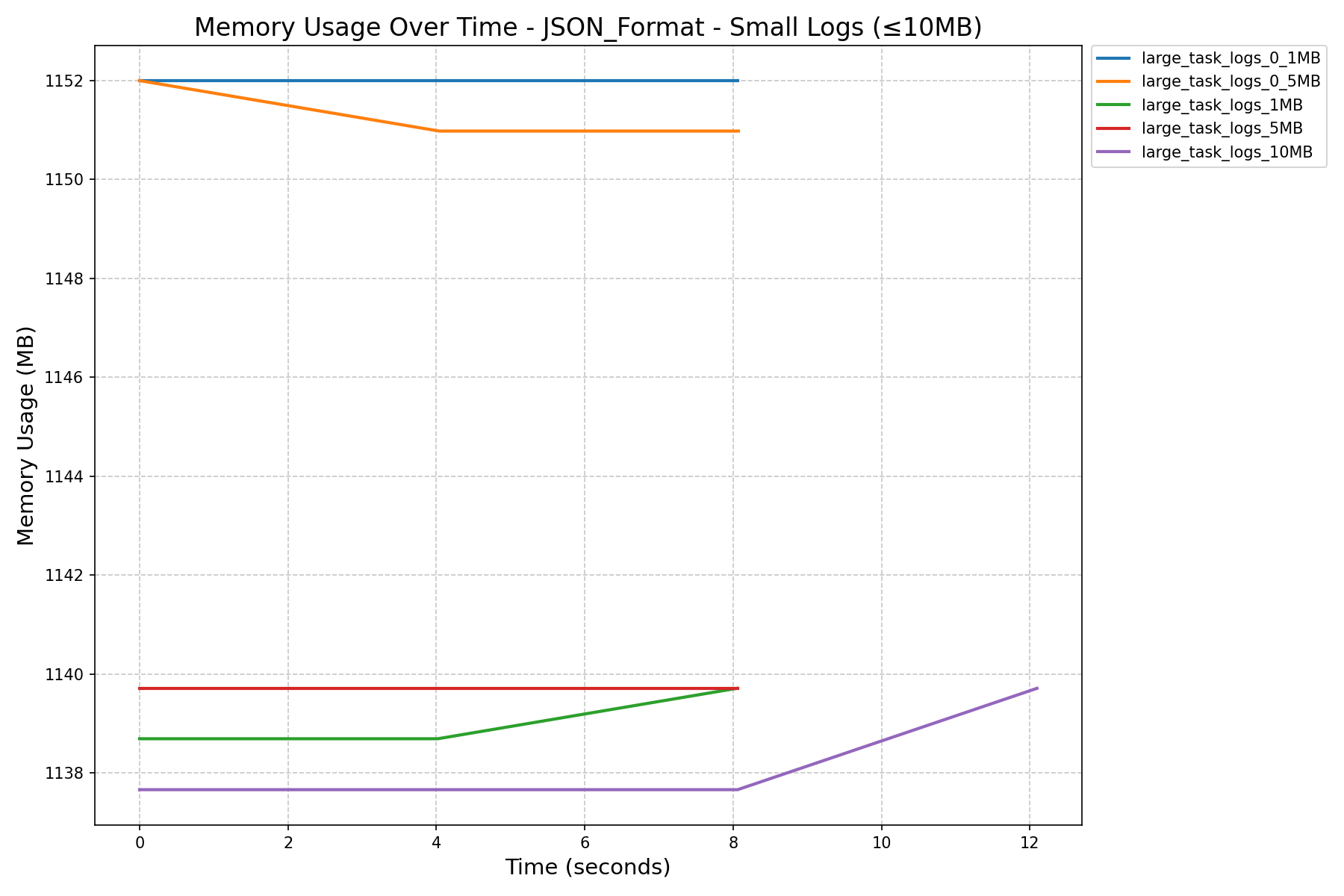 |
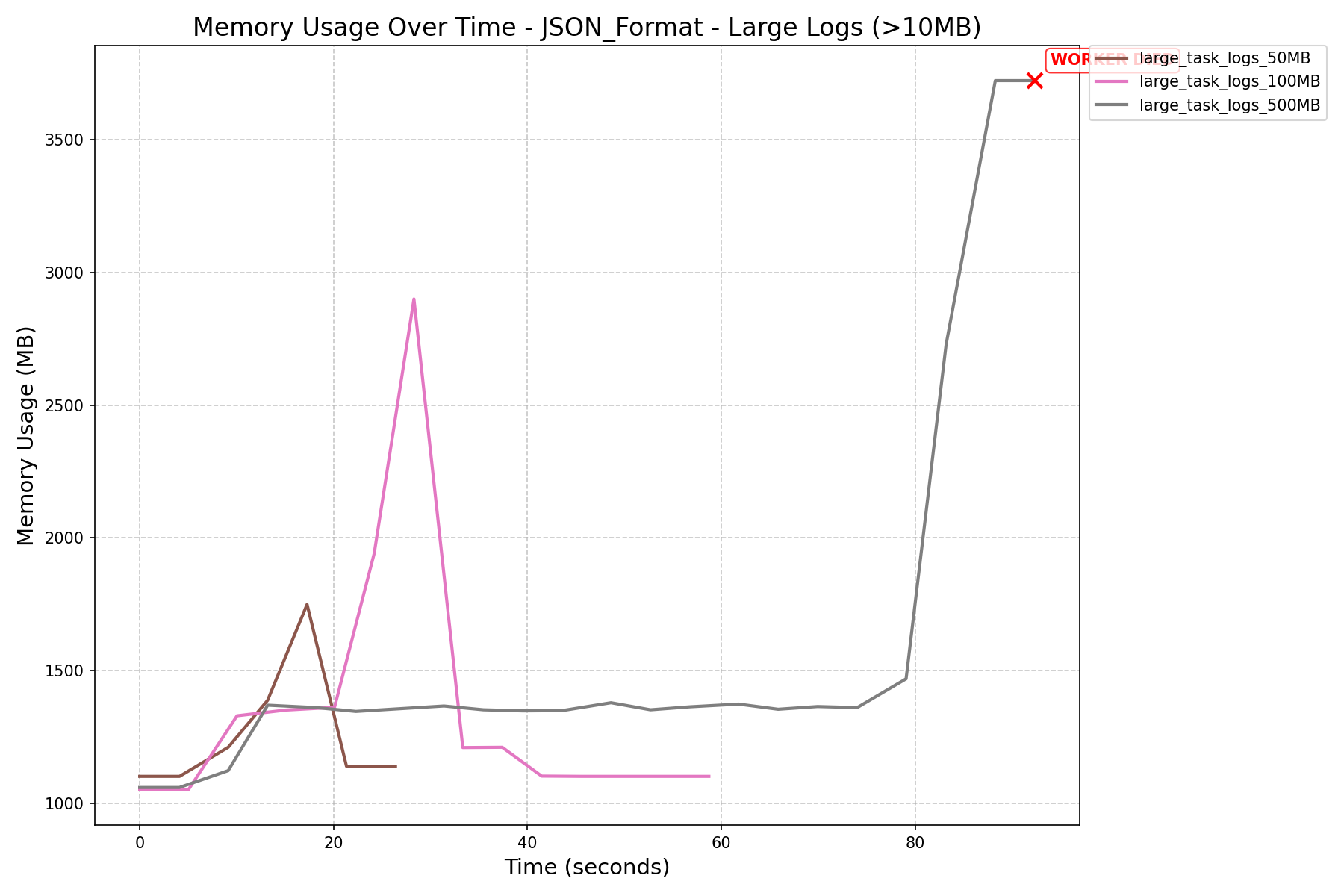 |
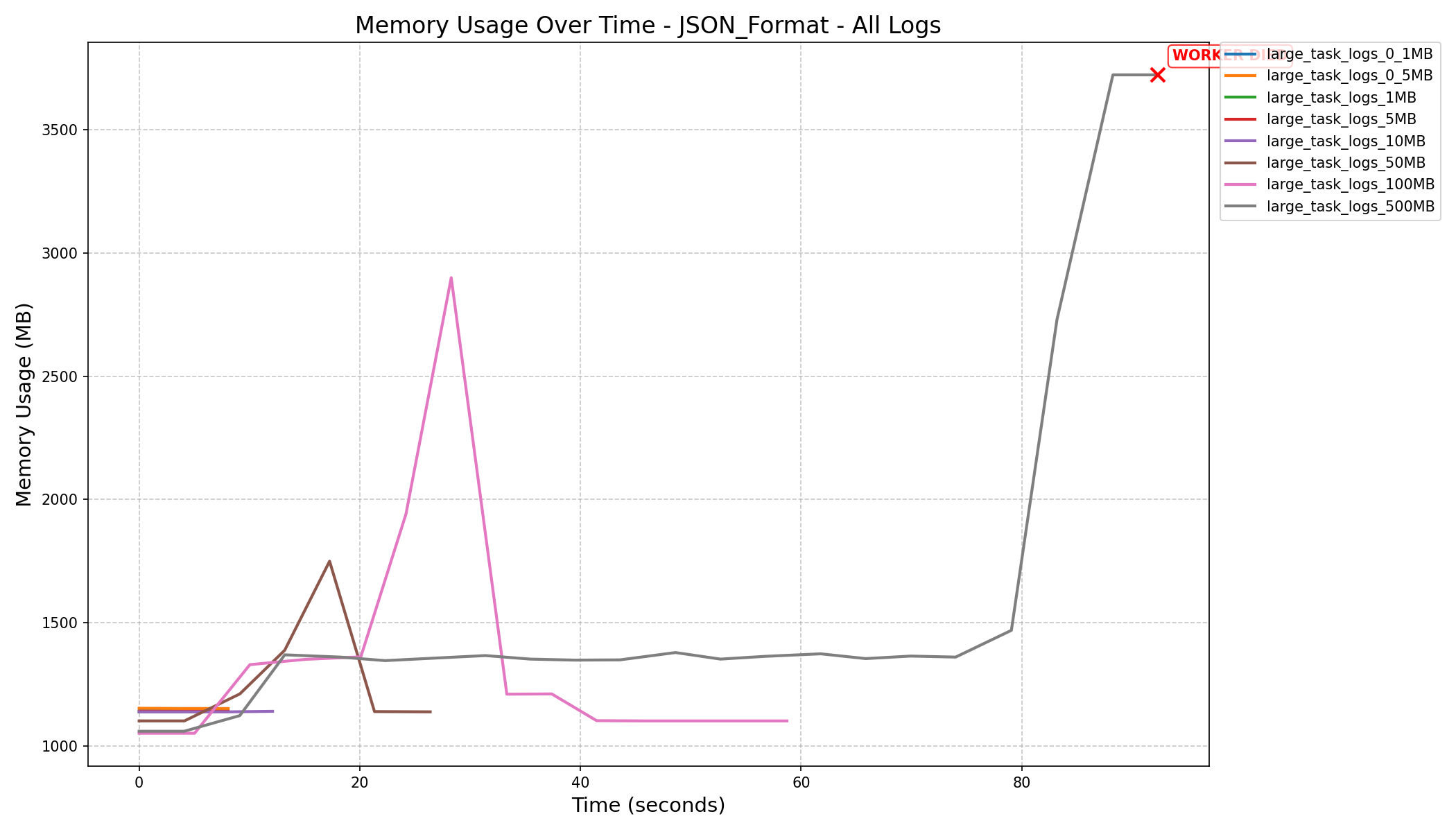 |
| NDJSON Format Memory History (in MB) | 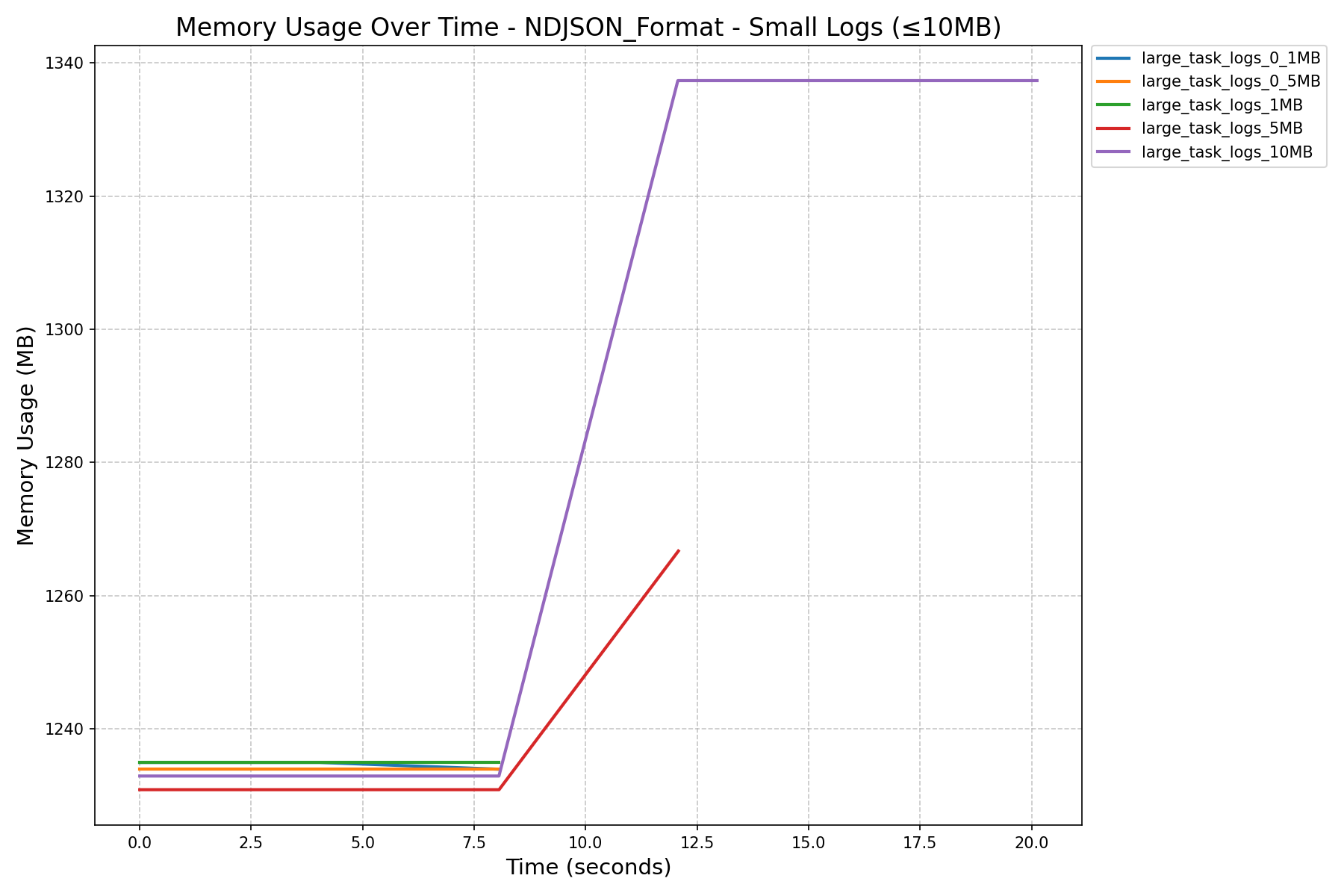 |
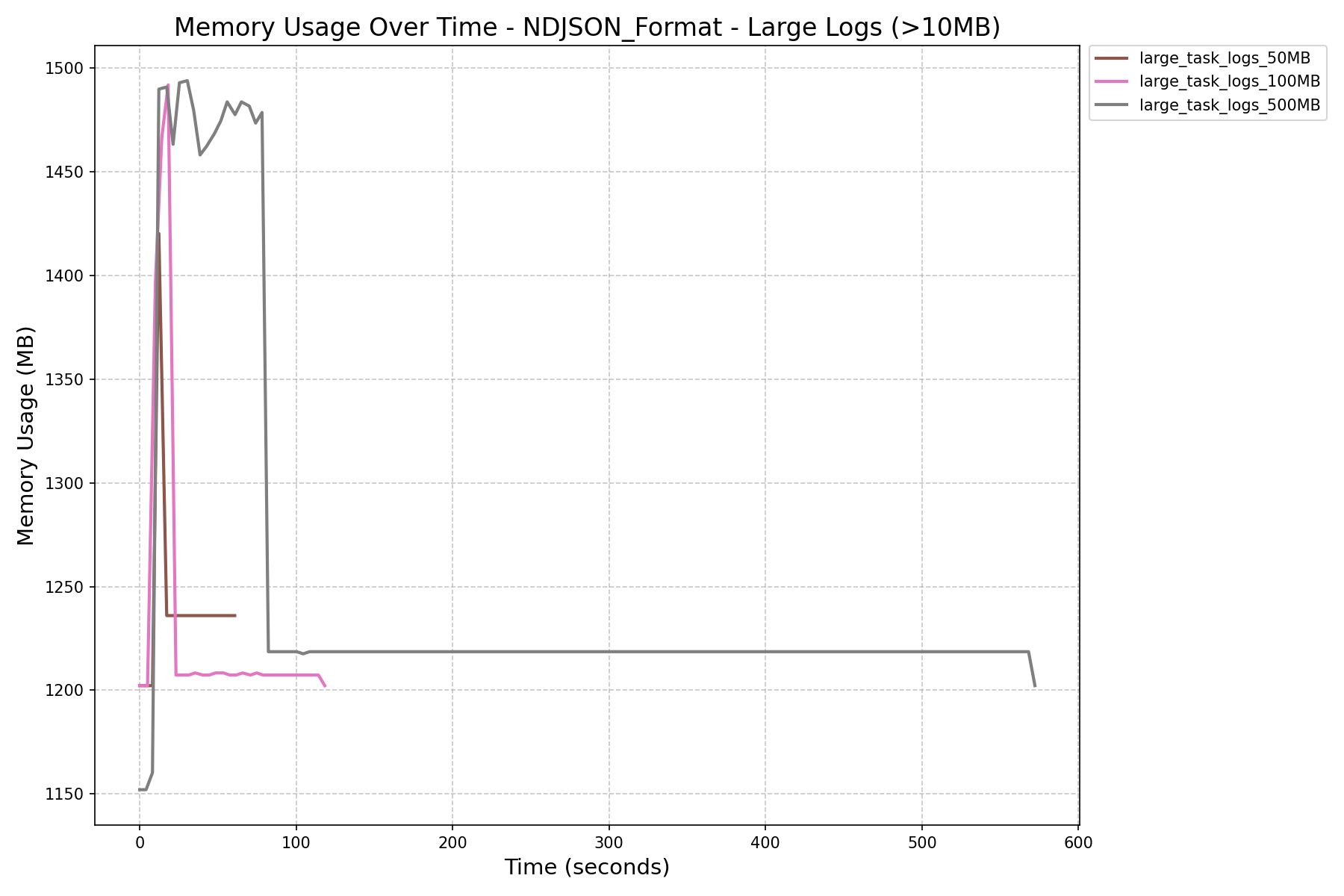 |
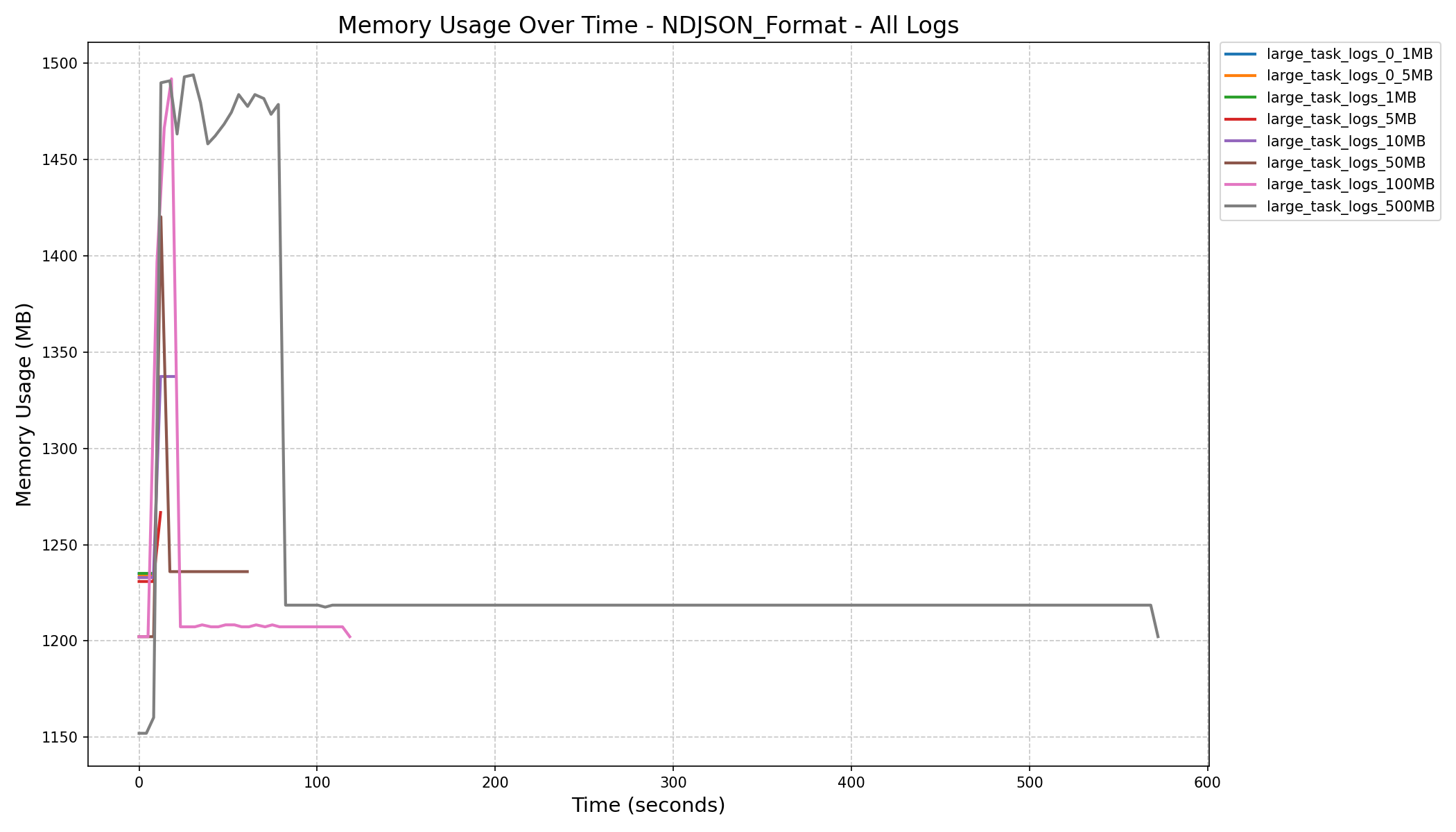 |
| Memory Increase (in MB) | 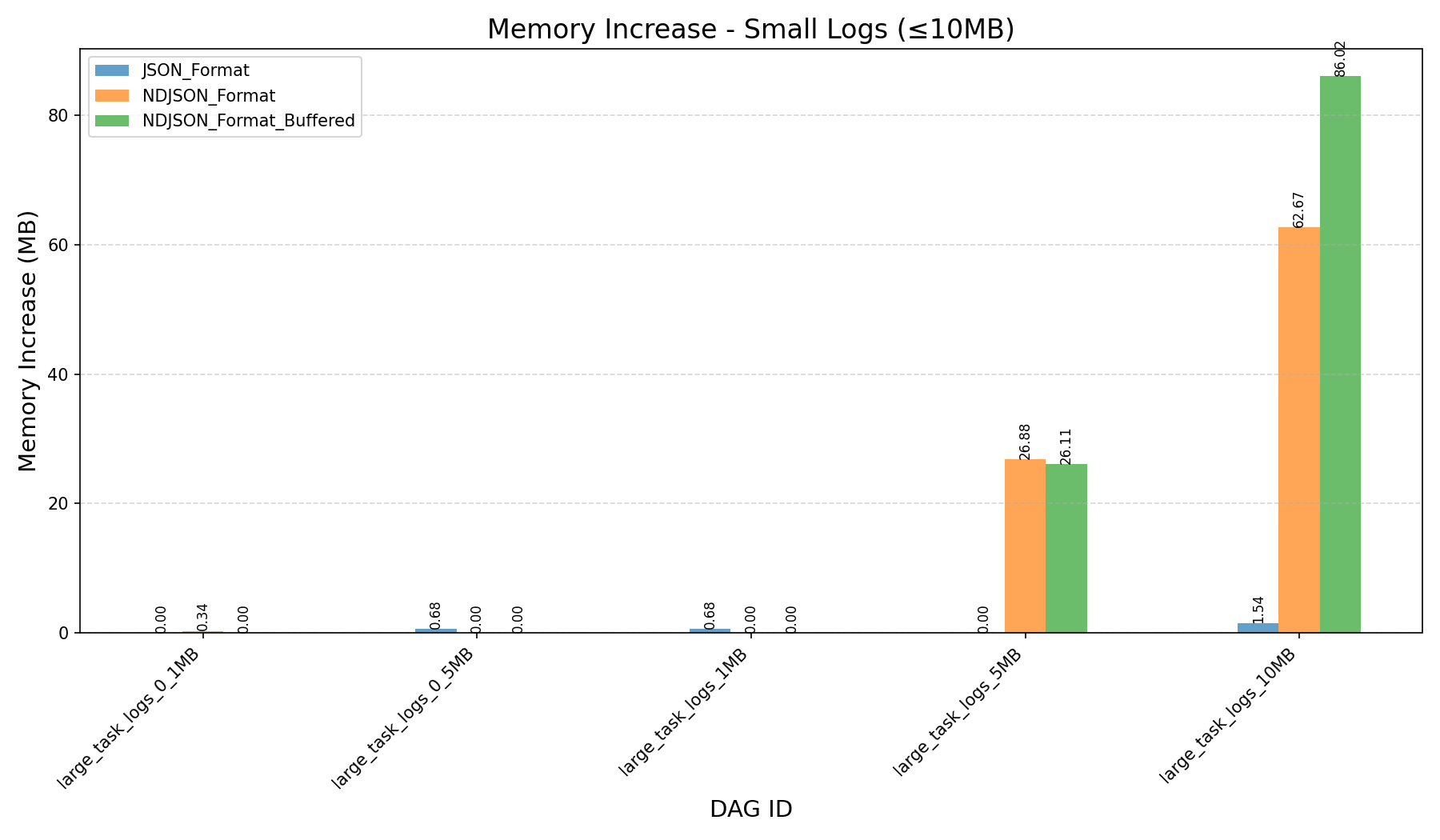 |
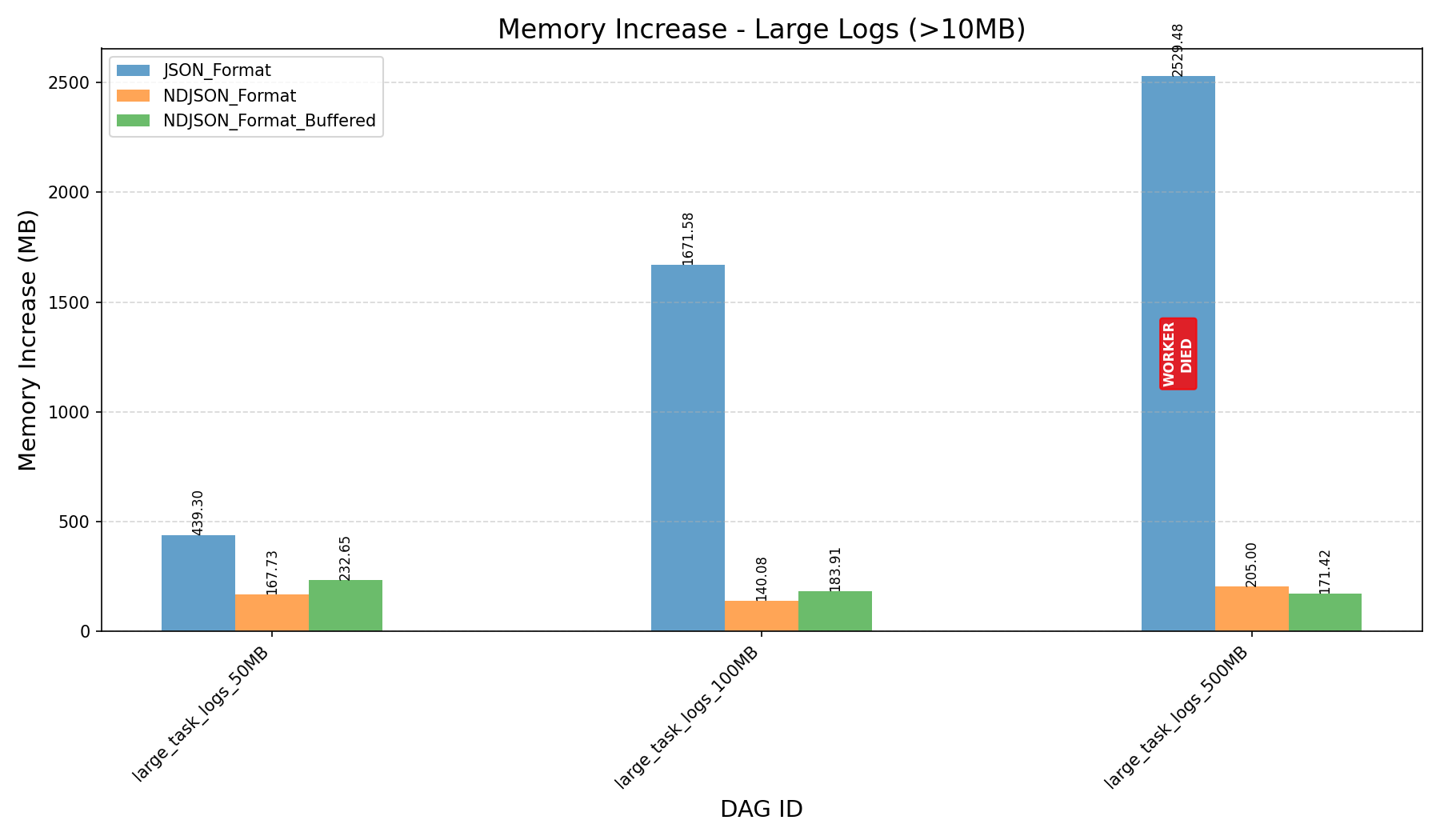 |
 |
Benchmark Results: Fine-Tuning HEAP_DUMP_SIZE
After Refactoring HEAP_DUMP_SIZE = 500000
| Small Logs (≤10MB) | Large Logs (≥ 50MB) | All Logs | |
|---|---|---|---|
| Log Fetch Duration (in seconds) |  |
 |
 |
| JSON Format Memory History (in MB) | 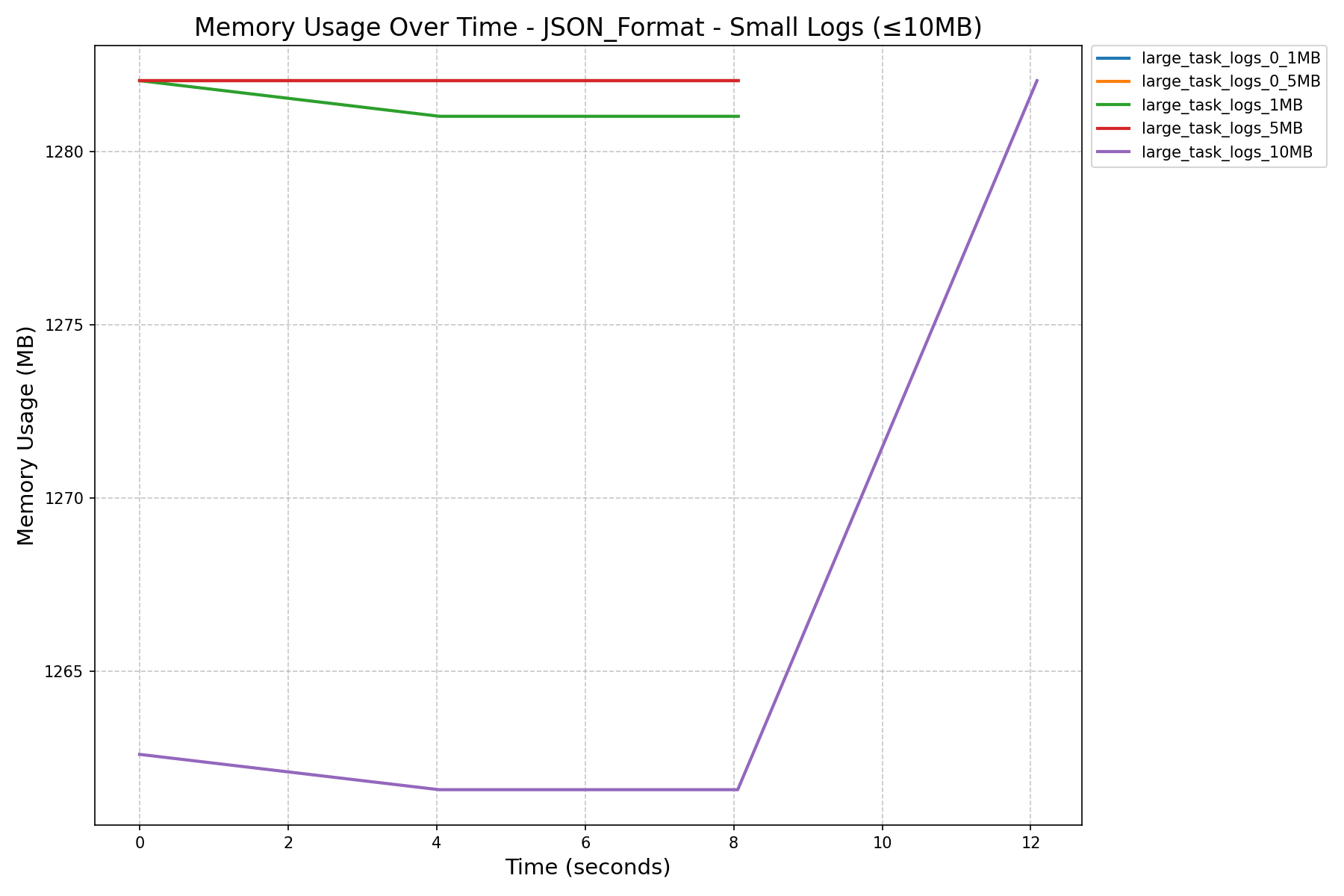 |
 |
 |
| NDJSON Format Memory History (in MB) | 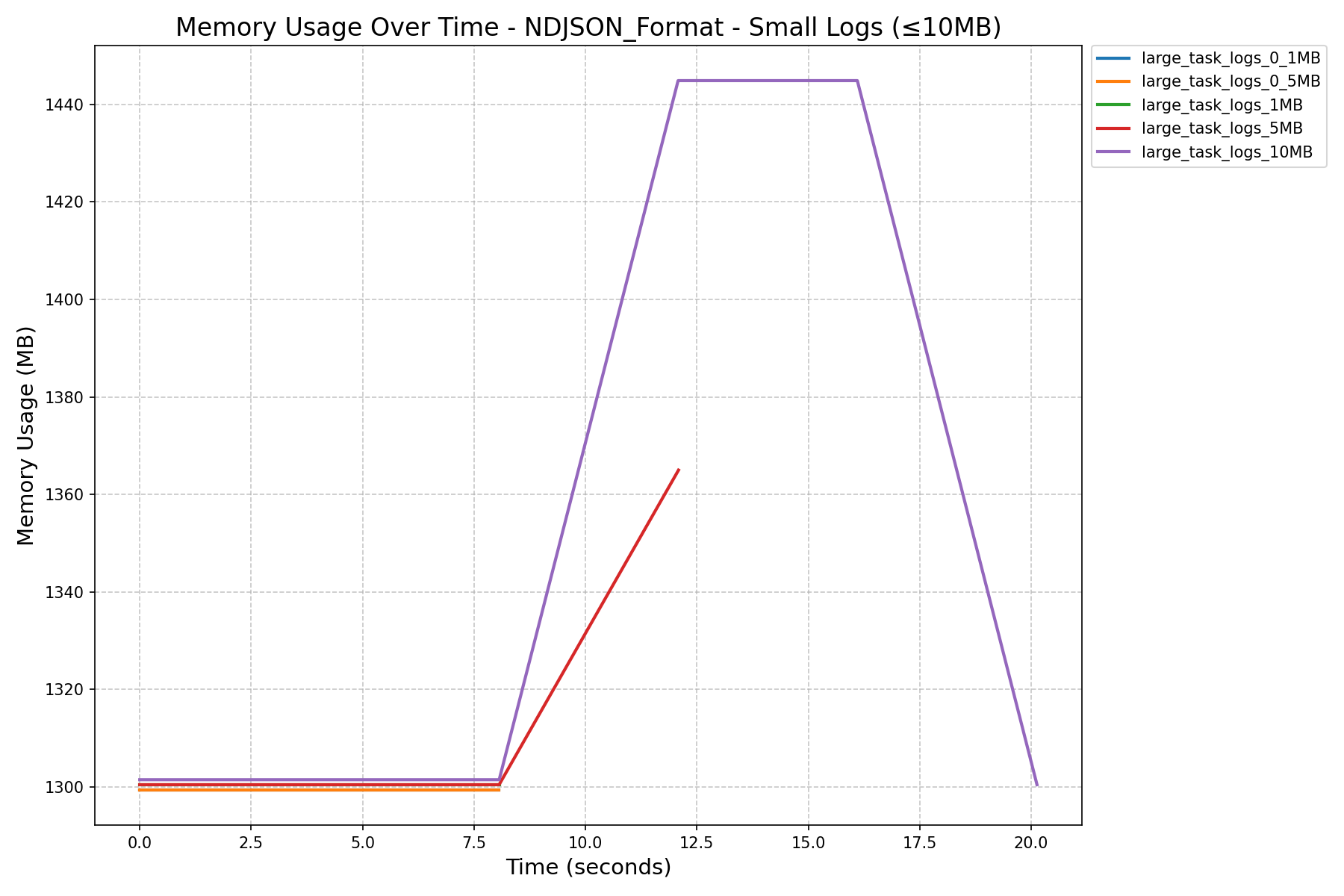 |
 |
 |
| Memory Increase (in MB) | 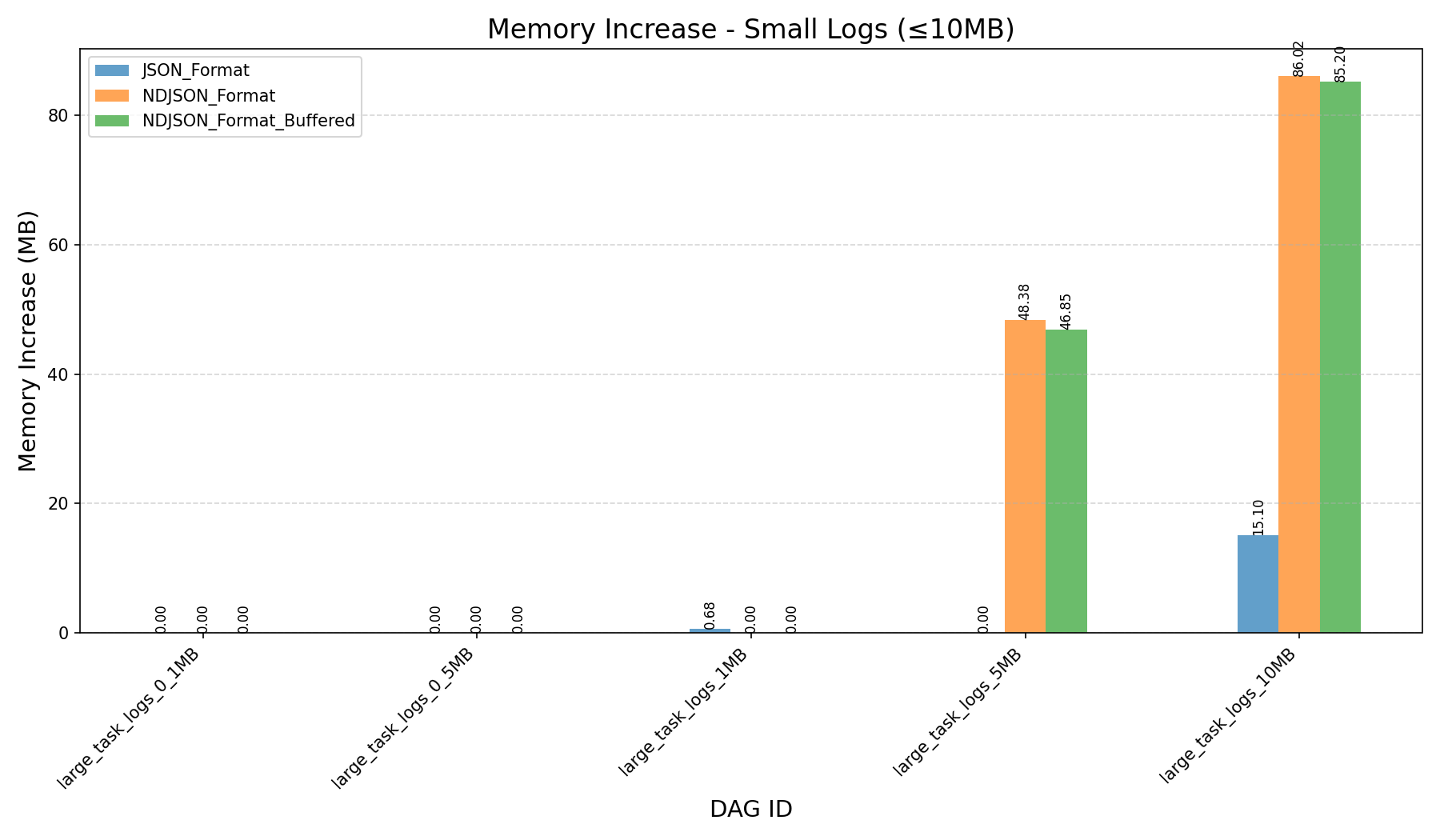 |
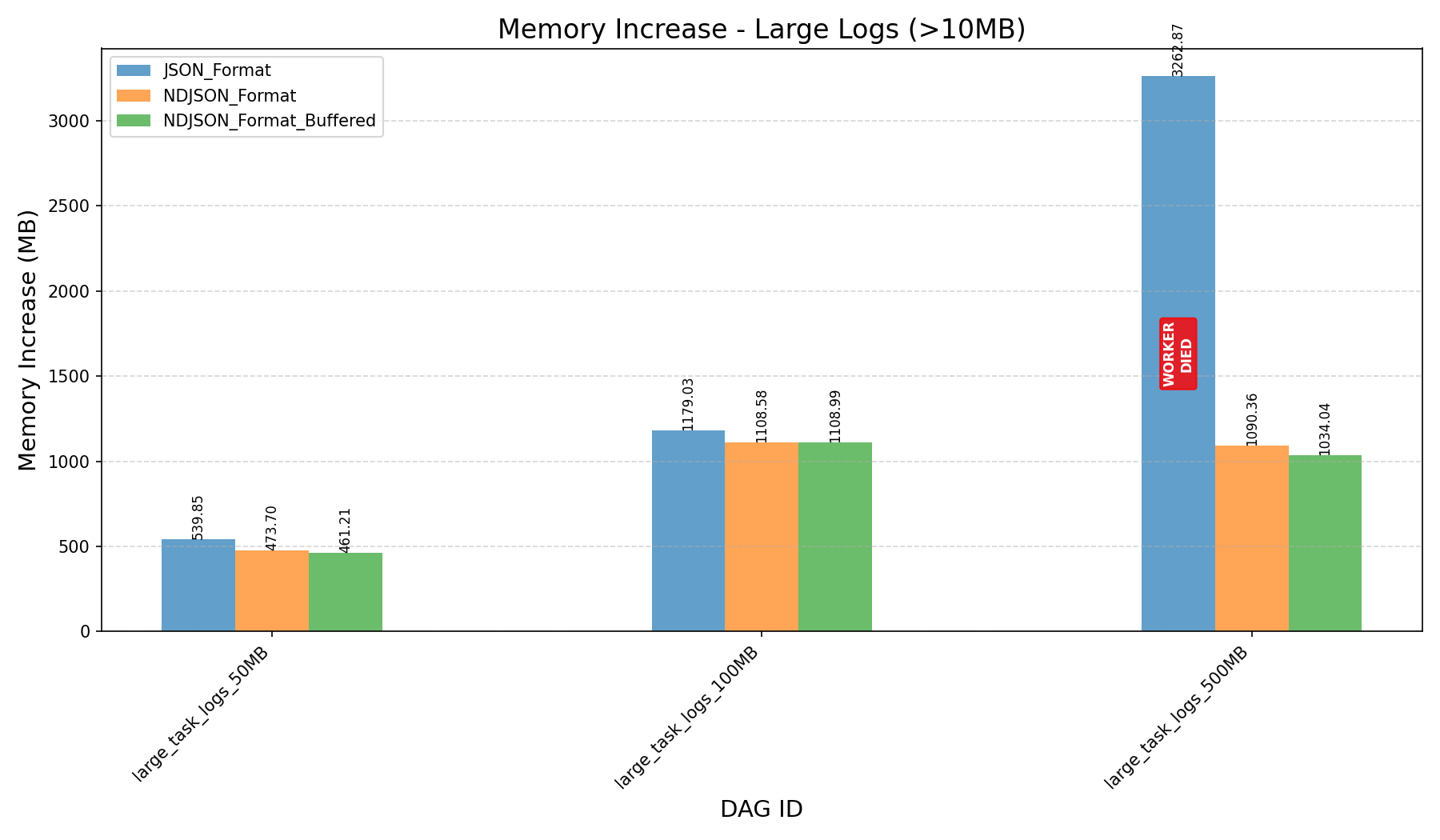 |
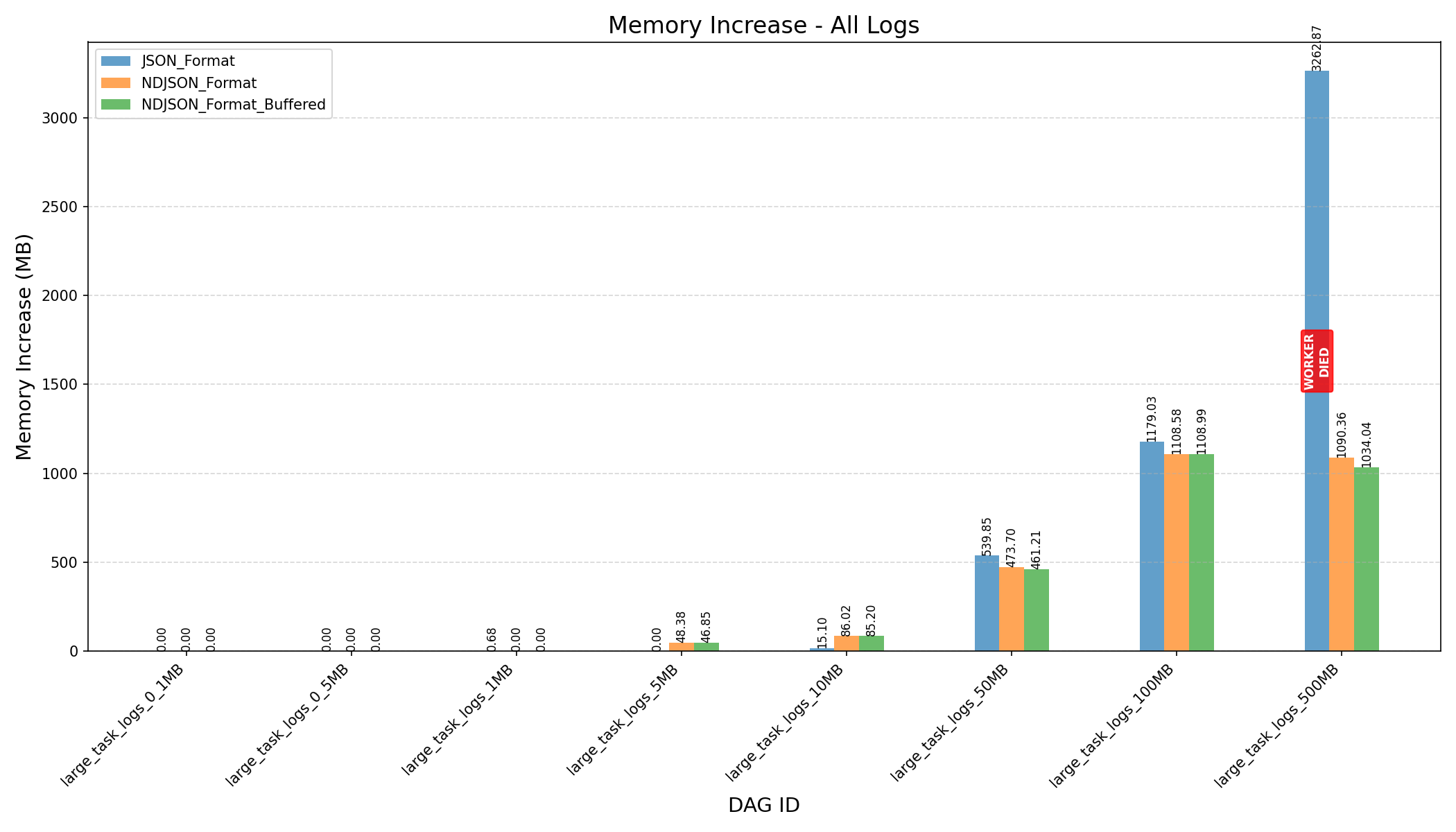 |
After Refactoring HEAP_DUMP_SIZE = 5000
| Small Logs (≤10MB) | Large Logs (≥ 50MB) | All Logs | |
|---|---|---|---|
| Log Fetch Duration (in seconds) | 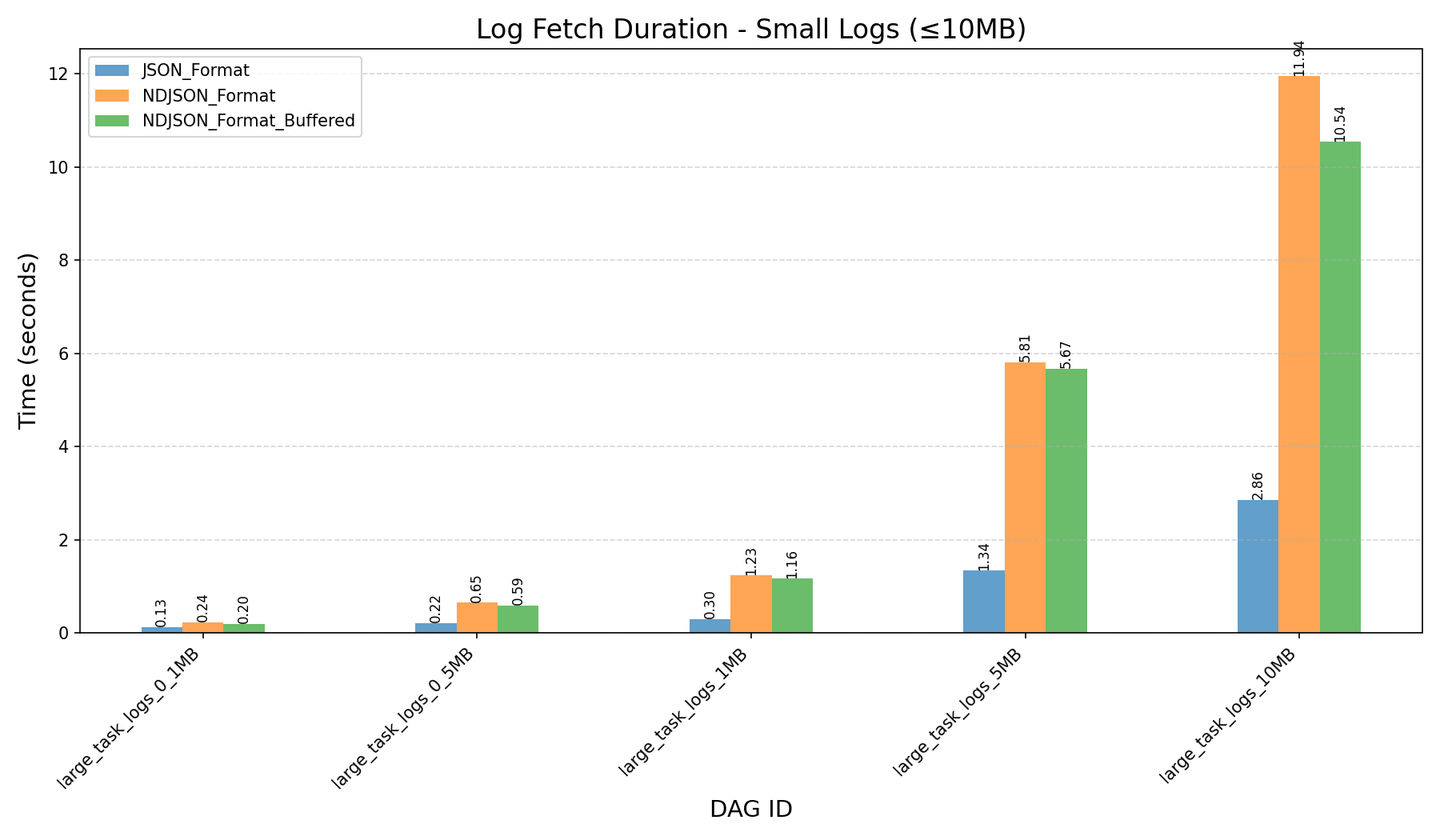 |
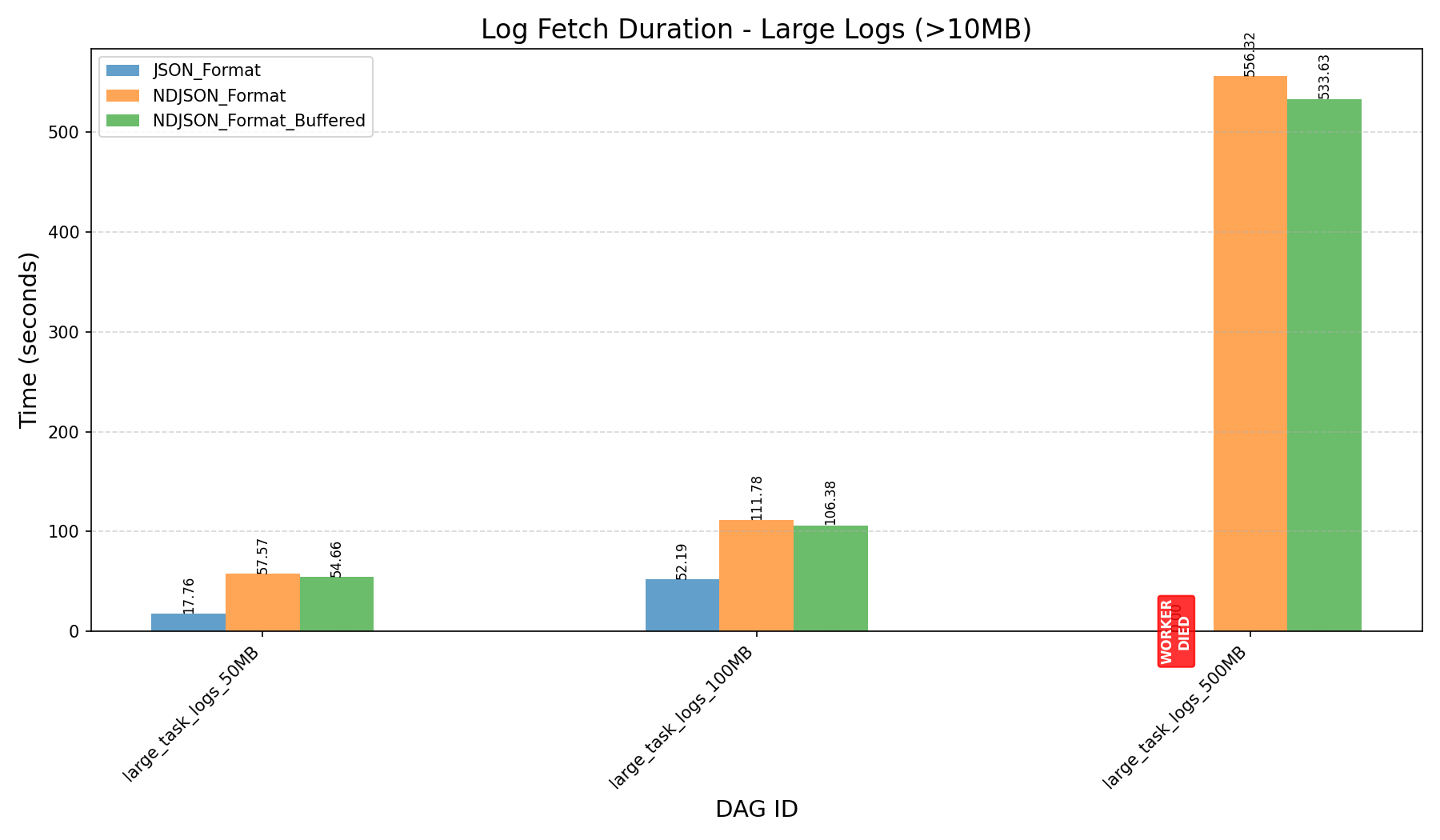 |
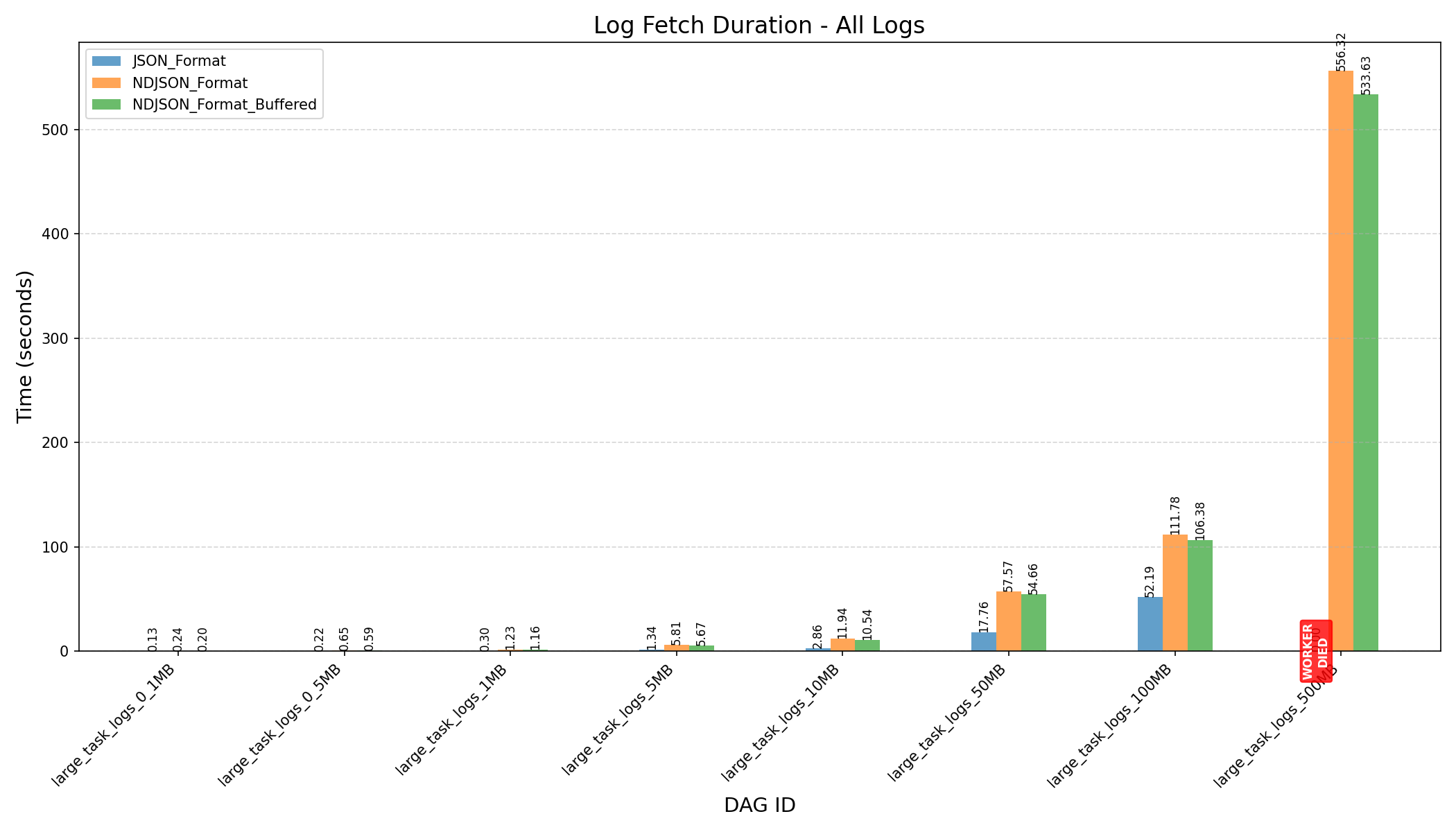 |
| JSON Format Memory History (in MB) | 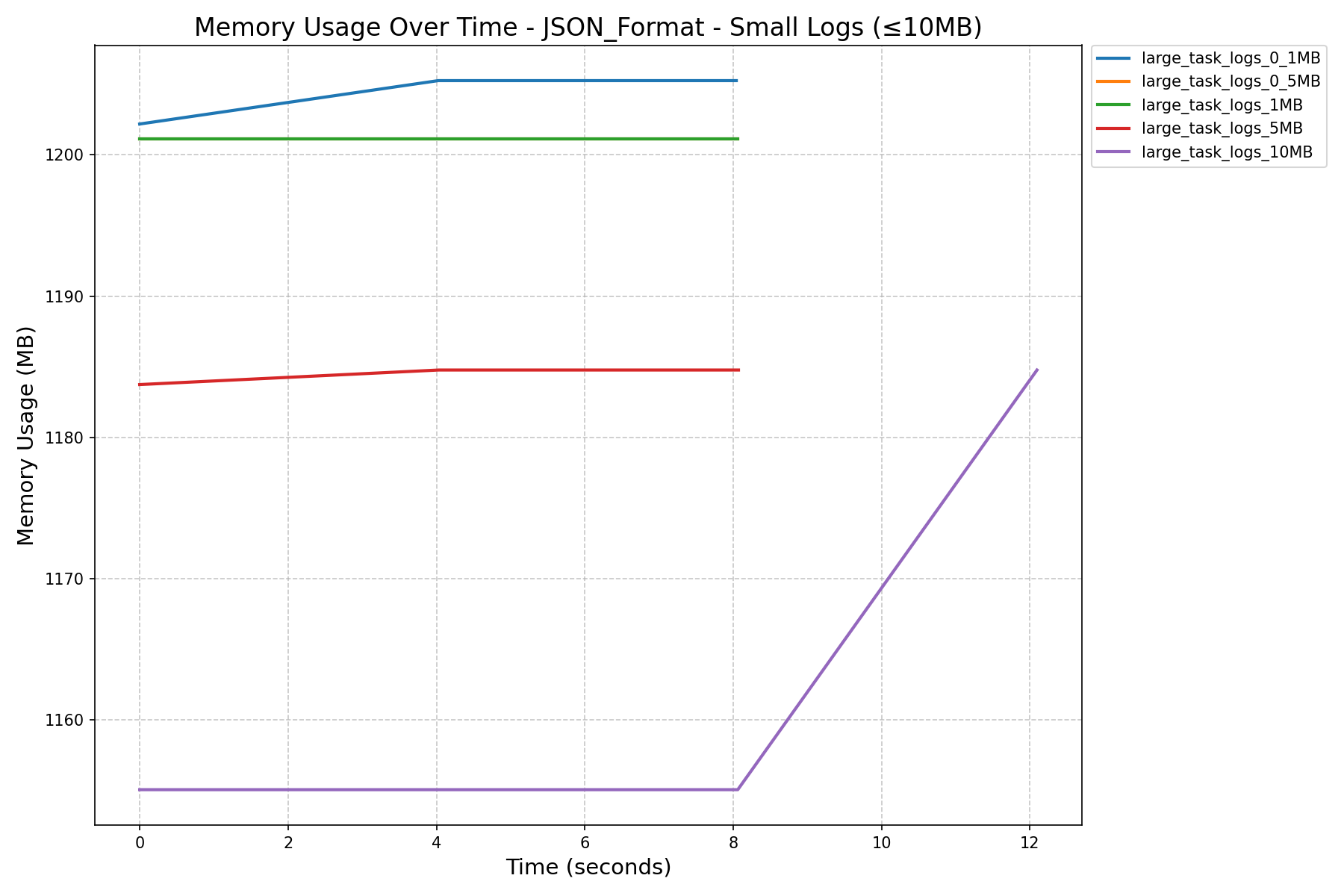 |
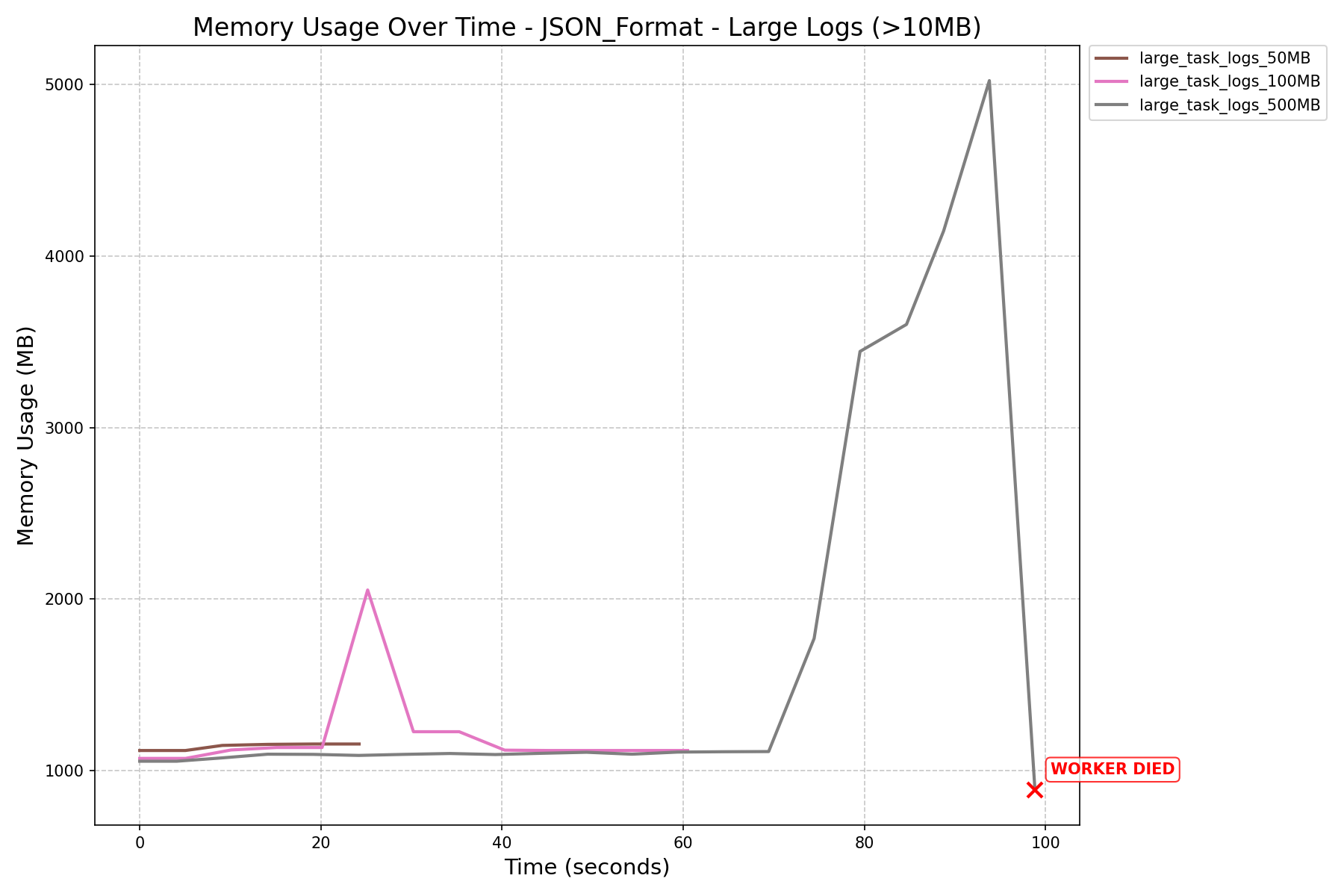 |
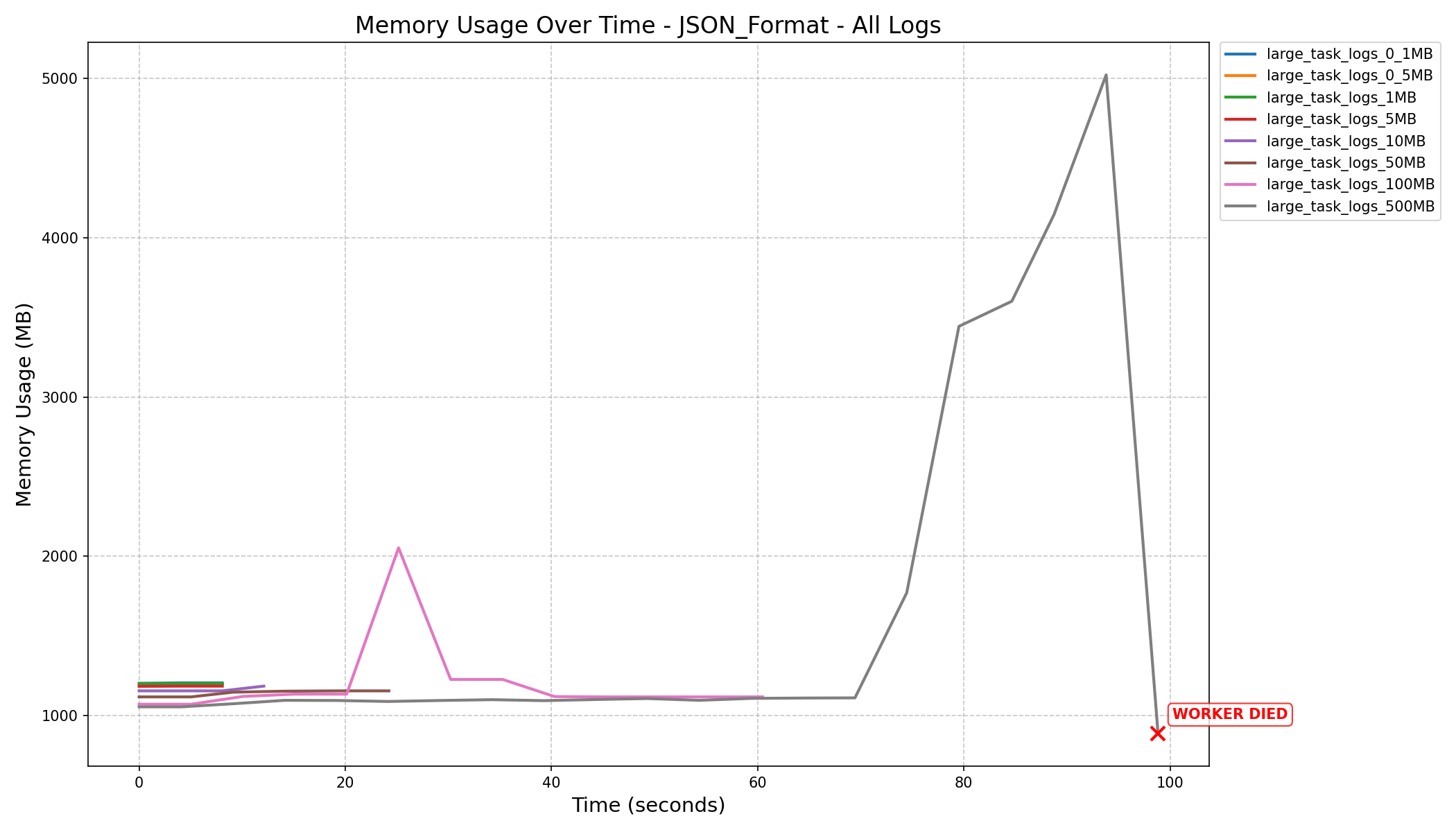 |
| NDJSON Format Memory History (in MB) | 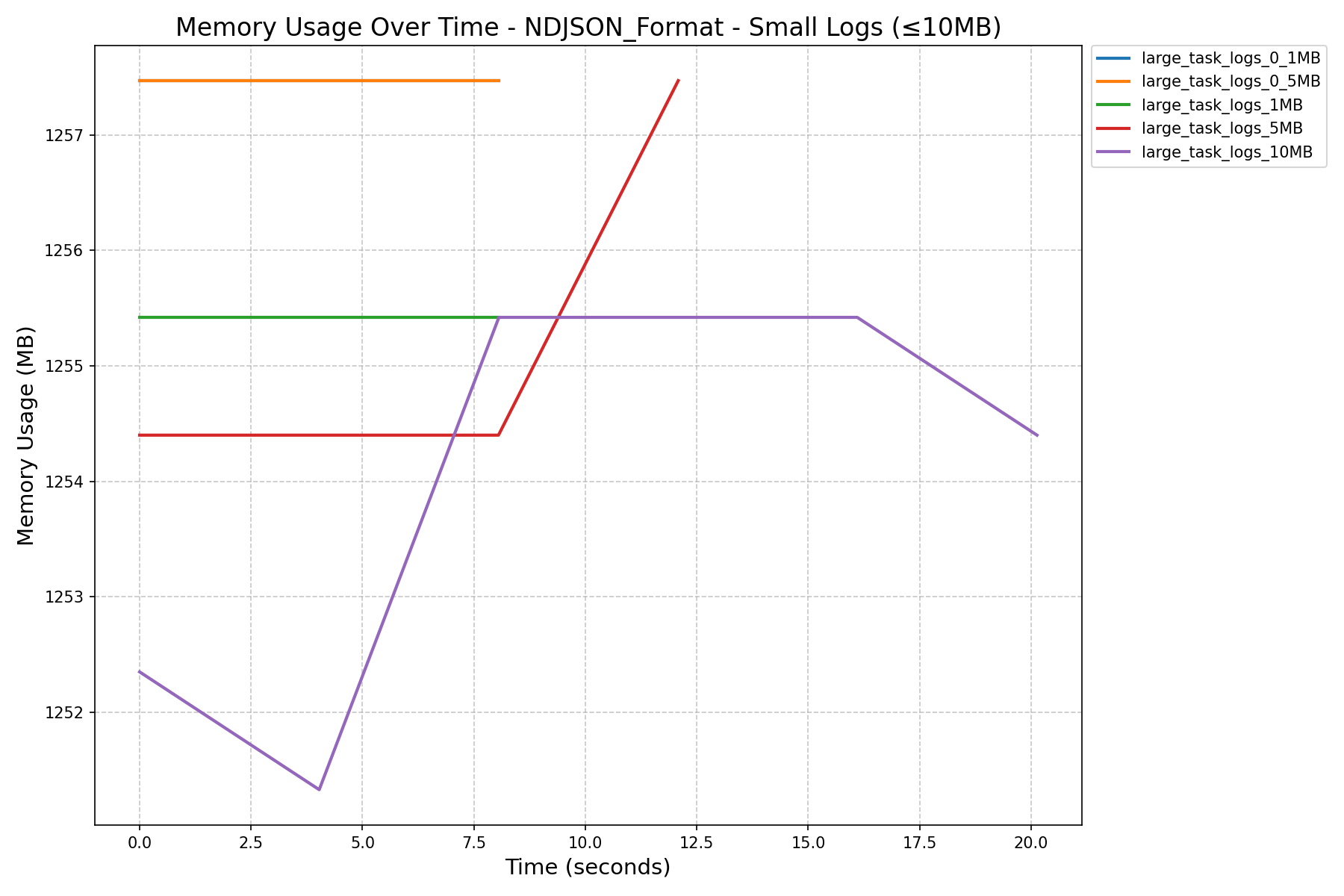 |
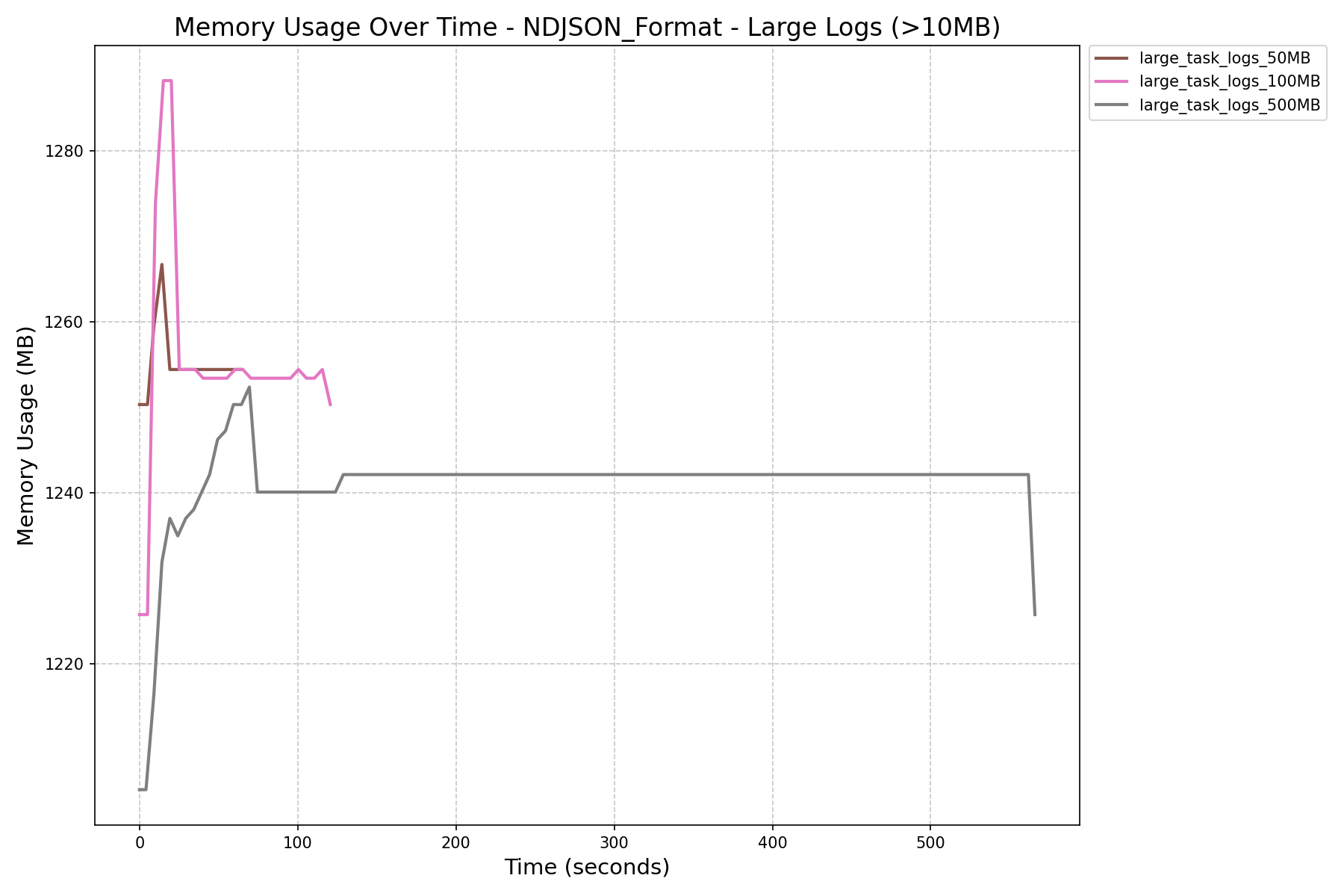 |
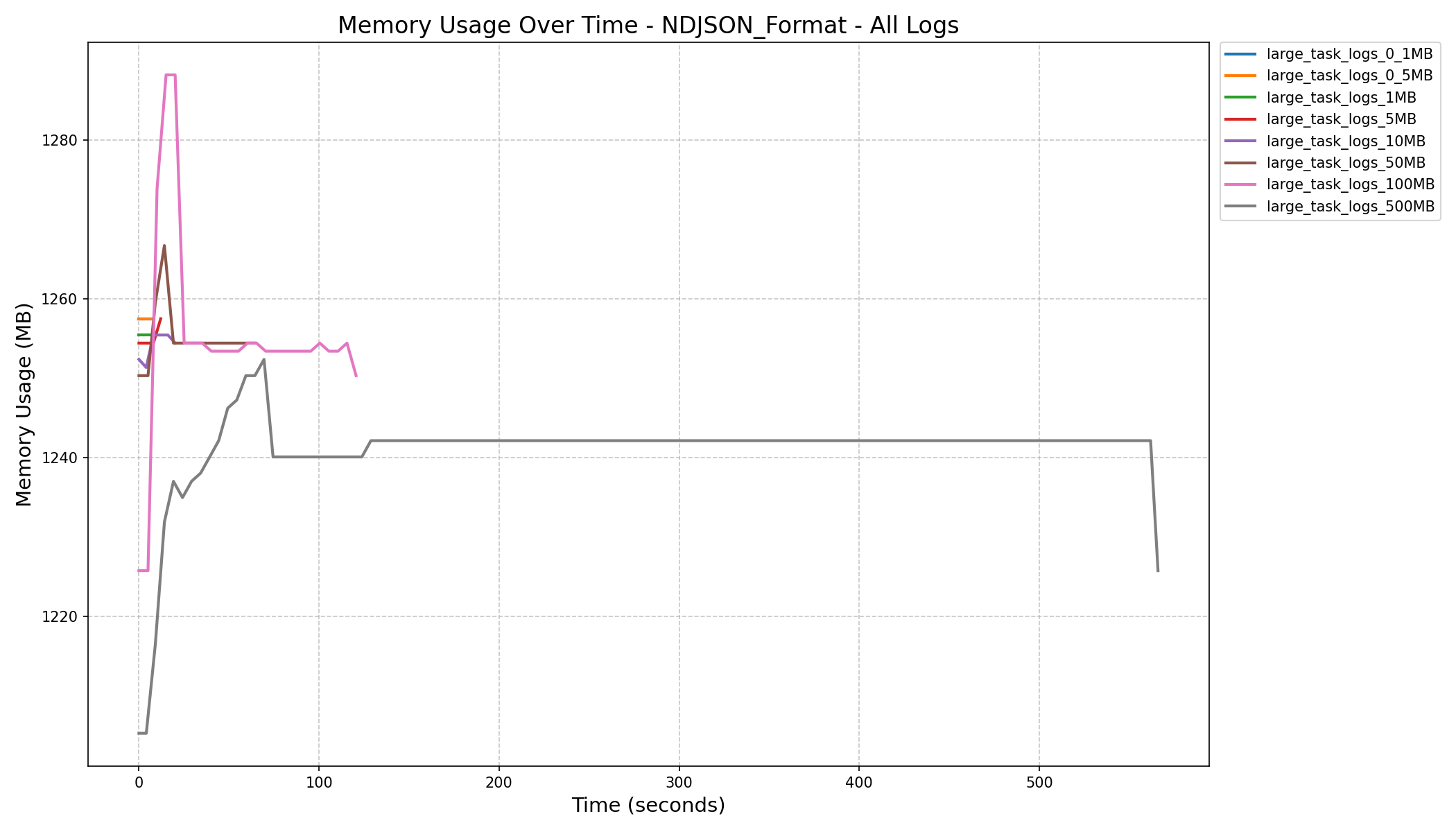 |
| Memory Increase (in MB) | 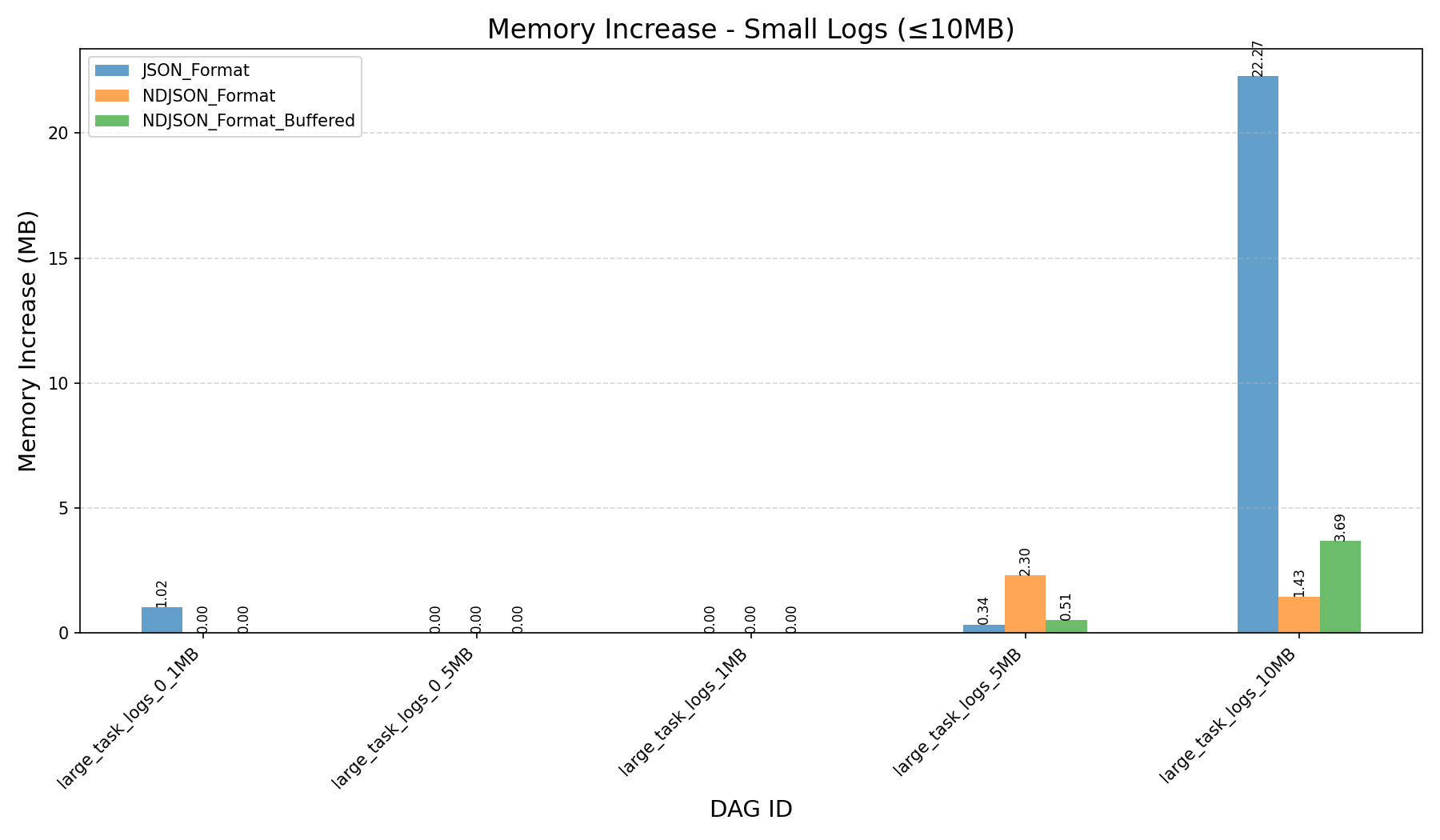 |
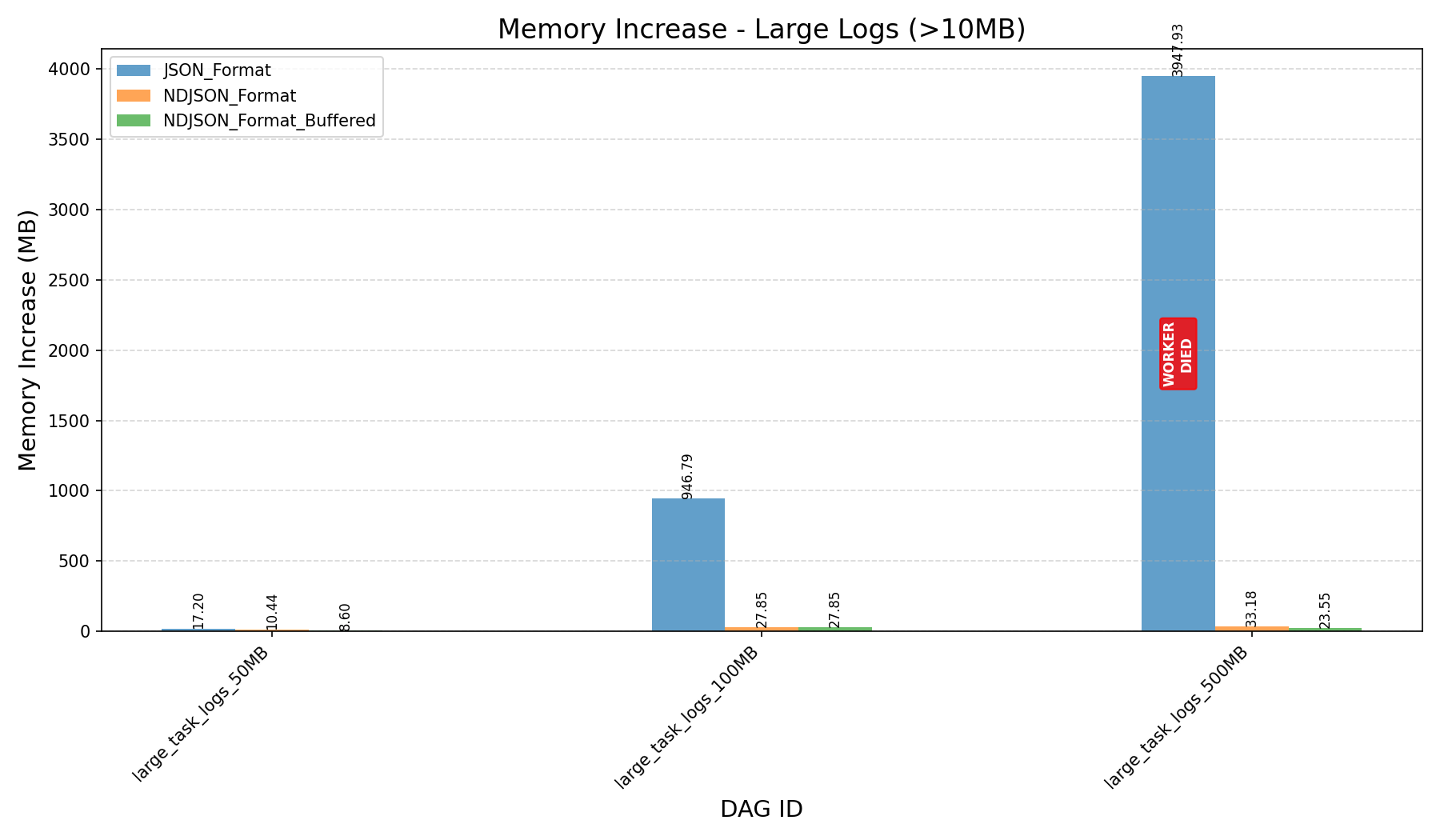 |
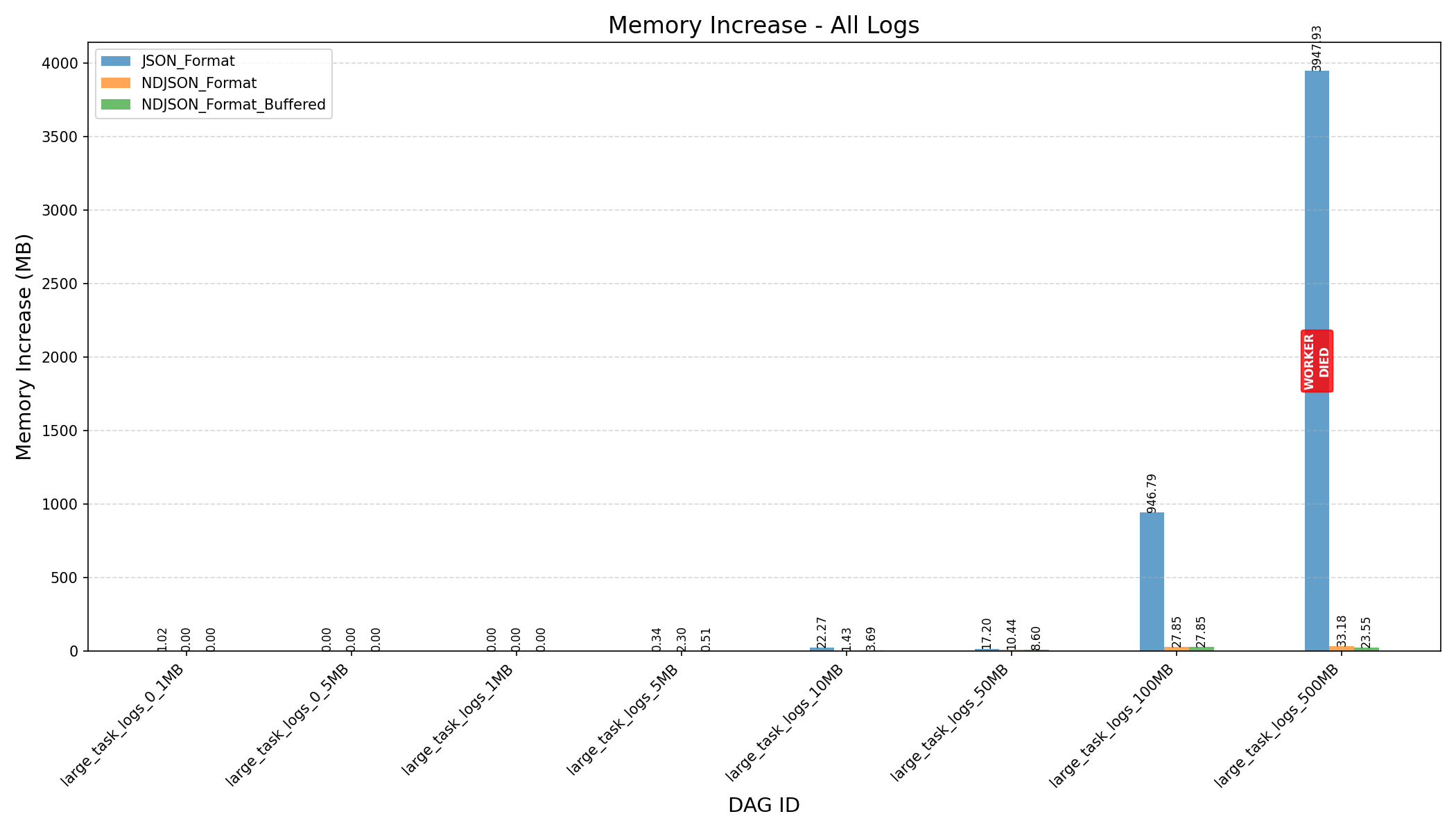 |
Nice, thanks for the benchmark, the memory improvement seems promising.
Do you know why it looks like the total response time is much longer after refactoring? Is that inherent to the stream solution? Also I'm not sure we care that much because the user will be able to see logs after the first chunck retrieval, wich might still be faster.
Yes, that's correct — the longer total response time is due to the use of StreamingResponse instead of returning a full JSON response.
the user will be able to see logs after the first chunk retrieval
Exactly. Even though the total response time might be longer, the user can start seeing logs immediately after the first chunk is streamed. Combined with #50746 (virtualized rendering) on the UI side, this approach should maintain — or even improve — the user experience while significantly stabilizing the API server under high-load or large-log scenarios.
As for improving response time further, I experimented with adding a read buffer on the log reader (e.g. yielding per X log lines). While it showed a slight improvement for large logs, it actually delayed the appearance of the first log line for smaller logs. So, I’ve removed the buffered reader from the final PR to optimize for initial responsiveness.
Thanks @Lee-W for the review, I will mark the PR as Draft while fixing.
Hi @eladkal, @ashb,
Would you mind taking another look at this PR when you have time? I’d really appreciate your time, thanks in advance!
A user has a problem that seems related (#52772) - and maybe we can work together with the user and help them to patch their airflow with this fix to confirm the isssue is resolved (but it would need to be rebased with conflict resolution - and maybe indeed that can get some reviews them and get prioritised for next patchlevel of Airflow ?
A user has a problem that seems related (#52772)
Yes, this PR will resolve the issue and the corresponding fix on frontend side is already merged ( #50333 )
There are at least 2 user DM me for this issue and there 3 related issues on GitHub ( now there are 4! ).
Here is what the user DM me last month:
and maybe we can work together with the user and help them to patch their airflow with this fix to confirm the isssue is resolved (but it would need to be rebased with conflict resolution
Yeah, I can resolve the conflict right away and it's not a big problem. The real problem is described as below.
and maybe indeed that can get some reviews them and get prioritised for next patchlevel of Airflow ?
IMO, this is the most difficult part, I had raised the same PR half year before ( #45129 ) but it was closed due to huge change of #46827 and #48491. So I have to raise this new one.
Additionally, it seems @ashb has another WIP PR #52651 that will definitely conflict ( and likely will change some interface ) with this one.
We might need to check the priority of ash's one and mine. If we go with ash's one first, I might need to raise a new one due to too much conflict and interface changes.
@ashb WDYT? I would be for merging this one (if you are OK with the code) and then re-applying it to the structlog changes - it seems important enough to be cherry-picked to 3.0.4 - we stil have months till 3.1 will be out. Happy to help with cherry-picking.
Hi @potiuk, @ashb, Just checking in, any updates on this one?
Thanks in advance!
I would love to merge it - but there is a bit of a silence for @ashb side on it. @ashb -> what's your take ? I don't thing keeping @jason810496 for a long time with this one is a good idea - unless you have some strong reasons why this one should not be merged (as apparently you had other ideas that are possibly manifested in https://github.com/apache/airflow/pull/52651 ).
Any commnents? I would be inclined to merge it if we do not hear back unless @Lee-W and @uranusjr have something to say here - there were some comments to verify if they were adressed.
Yeah don't block on my PR, that is a slow background task for me for 3.1
Yeah. Thought so : @Lee-W @uranusjr -> I will do one more pass but if you have any more comments - feel free (we can schedule it for 3.0.4 if it will be easily cherry-pickable,
Yeah don't block on my PR, that is a slow background task for me for 3.1
Yeah. Thought so : @Lee-W @uranusjr -> I will do one more pass but if you have any more comments - feel free (we can schedule it for 3.0.4 if it will be easily cherry-pickable,
I don't have major concerns if there is a second pair of eyes. My comments mostly focused on minor improvements and typos. Not sure 3.0.4 is a good idea (looks more like a feature) but I'm looking forward to merging this one as well.
I only have one comment - we already check if new providers will work with last released airflow versions - our compatibility checks are testing it. This is very cool.
But since that change also touches core, I am not 100% sure if the old providers will work with the "upcoming" version of airlfow - we do not have such "forward" looking changes, but I can imagine that someone will get Airflow 3.1 and will want to downgrade (say) google provider to the version released now - it should also work. It's diffucult to make all the mental juggling to see if it will work because you need to connect codebase coming from different branches, but it should be relatively easy to test.
rm -rf dist/*breeze release-management prepare-airflow-dstributionsbreeze release-management prepare-task-sdk-distributionsbreeze start-airflow --mount-sources tests --use-airflow-version wheel- in breeze
pip install apache-airflow-providers-google - Configure logging to use one of the providers handlers
- restart everything and see that it works
Is it possible to make such test(s) - just to be sure @jason810496 ?
Is it possible to make such test(s) - just to be sure @jason810496 ?
Sure, I will test this with real remote logging setup and update here.
Sure, I will test this with real remote logging setup and update here.
If you have any problems- let me know .. It could be that this recipe needs a bit of fixes and adjustments after recent changes ;)
I just test with the following setup with breeze k8s and it works smooth! And I re-build the k8s image before running the manual test for sure.
I will keep on testing setup with remote logging as well tomorrow.
Without remote logging
- KubernetesExecutor ( with no log persistent setup ): Works well, can only show logs when TI is in running state ( as expected )
- CeleryExecutor: Works well, can show logs no matter TI is in running or success, which means get get
serve_logswell after the refactor
With romote logging setup:
I setup Google Cloud Storage for remote logging
- KubernetesExecutor: Works well, can show logs now even if the TI is success
- CeleryExecutor: Works well, can show logs as expected and do really read from GCS
If you have any problems- let me know .. It could be that this recipe needs a bit of fixes and adjustments after recent changes ;)
All good until the last start-airflow command.
I didn't dig into it to find the root cause so far; I just use breeze k8s to test the behavior as workaround ( IMO, with breeze k8s the behavior will be more real and it's require for testing with KubernetesExecutor setup )
breeze start-airflow --mount-sources tests --use-airflow-version wheel
Here is the full traceback:
PostgreSQL: OK.
Starting Airflow
[2025-07-08T17:53:15.198+0000] {configuration.py:1249} WARNING - No module named 'airflow.providers'
[2025-07-08T17:53:15.199+0000] {cli_parser.py:81} WARNING - cannot load CLI commands from auth manager: The object could not be loaded. Please check "auth_manager" key in "core" section. Current value: "airflow.api_fastapi.auth.managers.simple.simple_auth_manager.SimpleAuthManager".
[2025-07-08T17:53:15.200+0000] {cli_parser.py:82} WARNING - Auth manager is not configured and api-server will not be able to start.
DB: postgresql+psycopg2://postgres:***@postgres/airflow
Performing upgrade to the metadata database postgresql+psycopg2://postgres:***@postgres/airflow
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 10, in <module>
sys.exit(main())
File "/usr/local/lib/python3.10/site-packages/airflow/__main__.py", line 55, in main
args.func(args)
File "/usr/local/lib/python3.10/site-packages/airflow/cli/cli_config.py", line 48, in command
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/airflow/utils/cli.py", line 113, in wrapper
return f(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/airflow/utils/providers_configuration_loader.py", line 56, in wrapped_function
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/airflow/cli/commands/db_command.py", line 197, in migratedb
run_db_migrate_command(args, db.upgradedb, _REVISION_HEADS_MAP)
File "/usr/local/lib/python3.10/site-packages/airflow/cli/commands/db_command.py", line 125, in run_db_migrate_command
command(
File "/usr/local/lib/python3.10/site-packages/airflow/utils/session.py", line 101, in wrapper
return func(*args, session=session, **kwargs)
File "/usr/local/lib/python3.10/site-packages/airflow/utils/db.py", line 942, in upgradedb
import_all_models()
File "/usr/local/lib/python3.10/site-packages/airflow/models/__init__.py", line 59, in import_all_models
__getattr__(name)
File "/usr/local/lib/python3.10/site-packages/airflow/models/__init__.py", line 81, in __getattr__
val = import_string(f"{path}.{name}")
File "/usr/local/lib/python3.10/site-packages/airflow/utils/module_loading.py", line 61, in import_string
module = import_module(module_path)
File "/usr/local/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/usr/local/lib/python3.10/site-packages/airflow/models/dag.py", line 65, in <module>
from airflow.assets.evaluation import AssetEvaluator
File "/usr/local/lib/python3.10/site-packages/airflow/assets/evaluation.py", line 34, in <module>
from airflow.sdk.definitions.asset.decorators import MultiAssetDefinition
File "/usr/local/lib/python3.10/site-packages/airflow/sdk/definitions/asset/decorators.py", line 25, in <module>
from airflow.providers.standard.operators.python import PythonOperator
ModuleNotFoundError: No module named 'airflow.providers'
Failed to run 'airflow db migrate'.
This could be because you are installing old airflow version
Attempting to run deprecated 'airflow db init' instead.
[2025-07-08T17:53:17.482+0000] {configuration.py:1249} WARNING - No module named 'airflow.providers'
[2025-07-08T17:53:17.483+0000] {cli_parser.py:81} WARNING - cannot load CLI commands from auth manager: The object could not be loaded. Please check "auth_manager" key in "core" section. Current value: "airflow.api_fastapi.auth.managers.simple.simple_auth_manager.SimpleAuthManager".
[2025-07-08T17:53:17.483+0000] {cli_parser.py:82} WARNING - Auth manager is not configured and api-server will not be able to start.
Usage: airflow db [-h] COMMAND ...
Database operations
Positional Arguments:
COMMAND
check Check if the database can be reached
check-migrations
Check if migration have finished
clean Purge old records in metastore tables
downgrade Downgrade the schema of the metadata database.
drop-archived Drop archived tables created through the db clean command
export-archived
Export archived data from the archive tables
migrate Migrates the metadata database to the latest version
reset Burn down and rebuild the metadata database
shell Runs a shell to access the database
Options:
-h, --help show this help message and exit
airflow db command error: argument COMMAND: invalid choice: 'init' (choose from 'check', 'check-migrations', 'clean', 'downgrade', 'drop-archived', 'export-archived', 'migrate', 'reset', 'shell'), see help above.
Error: check_environment returned 2. Exiting.
Error 2 returned
Hi @potiuk, I test with scenarios including
KuberntesorCeleryExecutor- Without remote logging or with Google Cloud Storage as remote logging
so there will be 4 permutations, and all of them work well !
Hi @potiuk, Just wanted to check, do you think this is good to merge? Or is there any additional testing I should perform? Thanks!
Hi @potiuk, I test with scenarios including
Kuberntes or Celery Executor Without remote logging or with Google Cloud Storage as remote logging so there will be 4 permutations, and all of them work well !
Fantastic! Thanks! All good!
Backport failed to create: v3-0-test. View the failure log Run details
| Status | Branch | Result |
|---|---|---|
| ❌ | v3-0-test |
You can attempt to backport this manually by running:
cherry_picker ee54fe9 v3-0-test
This should apply the commit to the v3-0-test branch and leave the commit in conflict state marking the files that need manual conflict resolution.
After you have resolved the conflicts, you can continue the backport process by running:
cherry_picker --continue