amundsen
 amundsen copied to clipboard
amundsen copied to clipboard
Add custom buttons on Amundsen UI and allow configurable actions upon clicking
Expected Behavior or Use Case
Amundsen currently surfaces high watermark and low watermark for partitioned tables. However, our data warehouse solution does not partition tables and we want to get realtime high watermark for tables. Databuilder that runs at fixed schedules for batch data is not a good fit for this purpose. We would like to have a button sitting together with Tags, Owners on the left side of the table detail page, so that upon clicking, it queries metadata service to fetch the real time high watermark and display it on the page. I can imagine this is very useful for non partitioned tables and ETL tasks that run frequently, for example, every 3 hours.
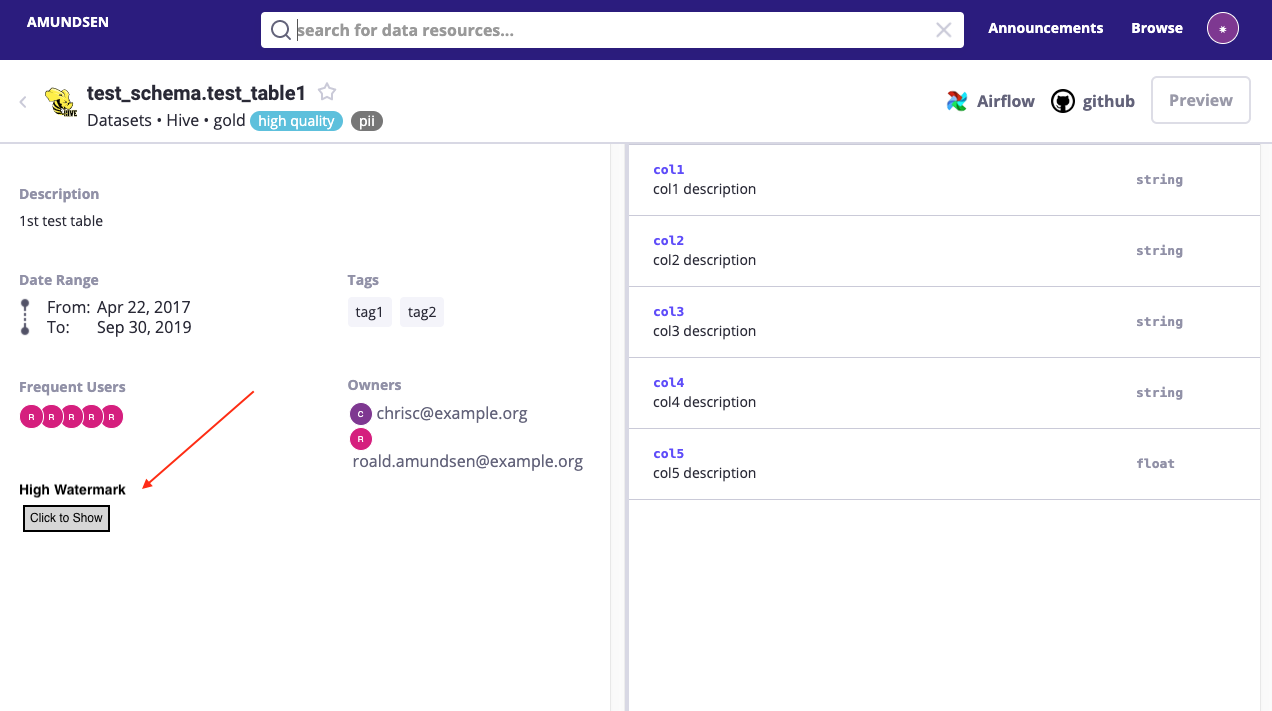
Service or Ingestion ETL
Frontend, Metadata
Possible Implementation
As the first section says
Example Screenshots (if appropriate):
Context
Getting something working locally with fake data as a POC.
https://github.com/youngyjd/amundsen/pull/11
I think this is very useful.
The cadence of Amundsen databuilder job and etl jobs are not always the same. For people who care about the freshness of the data, we can have some kind of fetch mechanism to fetch freshness, like data preview.
What do you think? @feng-tao @Golodhros @danwom
the questions would be: 1. which metadata will be refreshed (e.g how to make refresh generic); 2. UX; 3. how to handle different DW.
Also if we support push pattern (e.g instead of send the metadata to graph db, send it to kafka/pub sub with stream pipeline and persist into graph db) will it solve the use case?
instead of send the metadata to graph db, send it to kafka/pub sub with stream pipeline and persist into graph db
I am not sure how this will help with getting data freshness. Could you explain more?